Agentes e IA agéntica¶
En los últimos tiempos la IA ha dado un paso importante más en su constante evolución. Partiendo de los chatbots como ChatGPT o Gemini que ya llevan tiendo facilitándonos multitud de tareas, se ha desarrollado el concepto de agente de IA o de IAs agénticas o agentivas. En este documento explicaremos sus características principales y veremos algunas pinceladas de cómo desarrollar estos agentes.
1. ¿Qué es un agente de IA?¶
A diferencia de un chatbot tradicional (que solo responde a preguntas), un agente de IA es un sistema capaz de percibir su entorno, razonar y ejecutar acciones para alcanzar un objetivo específico de forma autónoma, o con la mínima intervención humana.
Imaginemos un ejemplo real: queremos pedir comida a domicilio. Si lo hiciéramos por nuestra cuenta, o incluso si empleáramos algún chatbot como Gemini o ChatGPT, los pasos serían:
- Pedir recomendaciones de restaurantes
- Elegir la comida (el chatbot podría sugerirnos ideas)
- Formalizar el pedido (a partir de este punto, el chatbot ya no nos puede ayudar)
- Pagar
- Llevar el seguimiento del pedido hasta que llegue a casa
Sin embargo, si empleamos un agente de IA y le decimos algo como "Tengo hambre, me apetece algo de comida mexicana", él se encargaría de elegir la aplicación con la que buscar comida, elegir el mejor restaurante mexicano de la zona, elegir la comida por nosotros, hacer el pedido y todo lo demás. Del mismo modo, podemos aplicarlo a tareas de muchos otros ámbitos, como la conducción autónoma ("Quiero ir a X"), o el desarrollo software ("Configura el entorno para un nuevo proyecto X").
Así, las características clave de un agente de IA son:
- Autonomía: es capaz de tomar decisiones sin intervención humana constante
- Uso de herramientas externas para realizar su labor, como puedan ser navegadores web para hacer búsquedas, acceso a bases de datos o APIs externas...
- Memoria: recuerda interacciones previas para mejorar su labor futura
- Planificación: descompone una tarea compleja en pasos lógicos más simples
1.1. Ámbitos de aplicación¶
Algunos de los ámbitos donde se utilizan actualmente estos agentes de IA son:
- Educación: por ejemplo, tutores personalizados que analizan los errores de los alumnos en ciertas materias (por ejemplo, matemáticas) y crea ejercicios específicos para reforzar sus debilidades.
- Ciberseguridad: por ejemplo, defensores proactivos que detecten intentos de intrusión en tiempo real y reconfiguren los firewalls para bloquear las amenazas
- Finanzas: analistas de inversión que monitoreen el mercado constantemente y ejecuten compras/ventas de activos según una estrategia predefinida
- Desarrollo de software: agentes que reciben reportes de errores en aplicaciones, detectan los fallos en el código y los corrigen, subiendo la revisión al repositorio (a modo de pull request, por ejemplo).
- Gestión empresarial: agentes que actualizan registros de CRMs, envían e-mails automáticamente, generan informes...
1.2. Agentes y LLMs¶
Los agentes de IA se basan en una capa previa de IA generativa o, para ser más precisos, de LLM (Large Language Models). A través de esta capa se es capaz de entender el contexto, razonar y generar contenido.
Sin embargo, los modelos LLM no son capaces de emprender acciones por sí mismos, y ahí es donde los agentes marcan el punto de inflexión, ya que serán capaces de realizar tareas por su cuenta sin intervención humana, tales como comunicarse con APIs remotas, o buscar en la web.
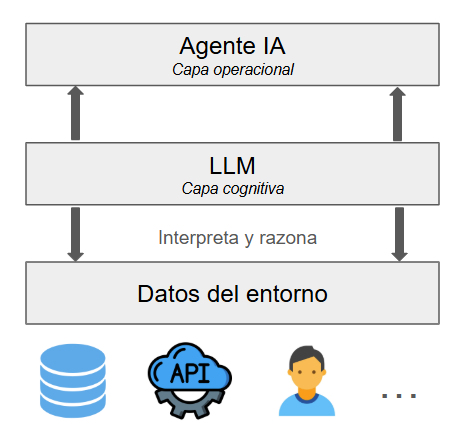
1.3. Un primer agente sencillo¶
Vamos a construir un primer ejemplo de agente IA que nos diga el tiempo que hace en una determinada localidad. Ya hemos dicho que la base sobre la que se sustentan estos agentes son los LLM, así que internamente emplearemos un LLM para hacer ese trabajo de interpretar los datos que se recogen de entrada.
Podemos escoger cualquier LLM al que podamos acceder mediante código, como ChatGPT, Gemini... En este ejemplo usaremos Gemini siguiendo los pasos que explicamos en esta sección. Comenzamos definiendo una función que recibe un texto del usuario (por ejemplo "Me gustaría saber qué tiempo hace en Zaragoza") y, mediante un prompt adecuado, le diga al LLM lo que debe hacer con ese texto: detectar si el usuario está preguntando por el tiempo y, si es así, averiguar de qué ciudad y devolverla:
Nota
Recuerda, siguiendo los apuntes de la sección mencionada antes, que debes tener instalada la librería google-genai como paso previo.
from google import genai
cliente = genai.Client(api_key='...') # Colocar la clave de Google AI Studio que tengamos
def obtener_ciudad(texto):
# Creamos el prompt para el LLM
prompt = f"""
El usuario ha dicho: "{texto}"
Tu tarea es extraer SOLO el nombre de ciudad si el usuario ha preguntado por el tiempo.
Si la pregunta no está relacionada con el tiempo o no se menciona ninguna ciudad,
devuelve NONE. Devuelve sólo un nombre de ciudad, sin texto extra ni signos de puntuación
"""
response = cliente.models.generate_content(
model="gemini-2.5-flash", contents=prompt
)
ciudad = response.text.strip()
return ciudad
Podemos probar esta función desde un pequeño programa principal como este:
texto = input("Introduce tu texto:\n")
ciudad = obtener_ciudad(texto)
print(ciudad)
Como puedes ver, Gemini hace el "trabajo sucio" por nosotros como desarrolladores: analiza el texto del usuario e identifica la ciudad a la que se refiere, sin necesidad de usar complejas expresiones regulares ni comprobaciones por nuestra parte.
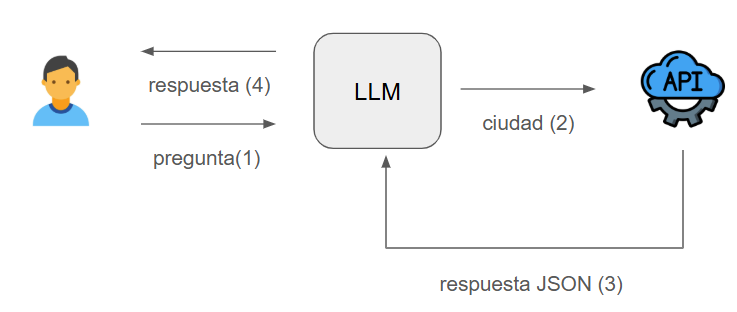
Ahora vamos a dar forma al funcionamiento de nuestro agente. Los pasos serán:
- El usuario hará una petición (ejemplo: "Quiero saber el tiempo que hace en Alicante")
- El LLM analiza el texto e identifica la ciudad
- Accederemos con ese nombre de ciudad a una API remota que nos dé datos del tiempo que hace (normalmente en formato JSON).
- Analizaremos los datos recibidos por la API con el LLM y, junto con la pregunta inicial hecha por el usuario, le ofreceremos una respuesta.
Ejercicio 1
Completa el agente anterior con estos pasos:
- Haz que acceda a una API remota de tiempo, como esta, pasándole el nombre de la ciudad para obtener datos en español del tiempo (incluyendo temperatura en grados Celsius).
- Utiliza de nuevo el LLM para que analice los datos JSON recibidos y, junto con la pregunta inicial del usuario, genere una respuesta adecuada para él.
2. Más sobre los LLM¶
Como hemos comentado en apartados anteriores, los LLM son un elemento esencial en el funcionamiento de los agentes, ya que constituyen su capa cognitiva. Sin embargo, el uso de LLM ofrece ciertas limitaciones, bien en cuanto a rendimiento (si los ejecutamos sobre ordenadores con características hardware limitadas) o bien en cuanto a límite de uso (si empleamos LLM remotos y sujetos a un máximo de peticiones).
En esta sección vamos a analizar algunas de las opciones de que disponemos para poder incorporar LLM a nuestros agentes.
2.1. Acerca de los prompts¶
A la hora de dirigir el funcionamiento de los agentes para completar una tarea es importante definir prompts adecuados. Existen distintas técnicas para establecer estos prompts; algunas de las más habituales son:
- Zero-shot prompting: le pedimos al modelo o agente que haga algo sin proporcionarle ejemplos de cómo hacerlo
- Few-shot prompting: le pedimos al agente una tarea y le proporcionamos algunos ejemplos del resultado que queremos obtener
- Cadena de pensamiento (chain of thought): hacemos que el agente vaya razonando paso a paso hasta encontrar la respuesta final. Esta técnica es habitual en razonamientos matemáticos, por ejemplo.
- Prompt estructurado: indicamos un formato de salida específico para la respuesta que buscamos (por ejemplo, formato JSON, o en forma de tabla), de modo que podemos emplearlo fácilmente como entrada de otro proceso.
2.2. Uso de LLM remotos¶
La realidad del uso de LLM remotos es bastante cambiante. Constantemente surgen nuevos modelos, y algunos de los que tradicionalmente estaban disponibles han cambiado sus requisitos y dejan de estarlo, al menos, de forma gratuita.
A continuación mostramos un listado de distintas webs donde poder registrarnos y obtener acceso a LLM de forma gratuita (y limitada):
- Google AI Studio: en este documento se dieron las pautas para registrarse y obtener una API Key con la que interactuar con distintos modelos. Sin embargo, los límites de uso son bastante restrictivos.
- Hugging Face: en este documento se explicó cómo darse de alta en la plataforma y utilizar algunos de sus modelos. También hay disponibles varios LLMs, aunque la cantidad de tokens que se nos permite usar con ellos de forma gratuita al mes está limitada y, excedido el límite, se bloquea su uso hasta el mes siguiente.
- Groq: se trata de una empresa estadounidense que ha desarrollado los LPUs (Language Processing Units). En su web podemos registrarnos de forma gratuita y acceder a distintos modelos a través de una API Key. El plan gratuito es más generoso que otras plataformas, y ofrece un número aceptable de peticiones y tokens. Para utilizarlo debemos instalar la librería
groq. Aquí tenemos un listado de los modelos disponibles.
El ejemplo anterior del tiempo quedaría así usando Groq (podemos cambiar el LLM por el que más nos guste):
import os
import requests
import json
from groq import Groq
# Configuración API Key Groq
os.environ['GROQ_API_KEY'] = '...'
cliente = Groq()
# Función para extraer del texto del usuario la ciudad de la que saber el tiempo
def obtener_ciudad(texto):
# Creamos el prompt para el sistema
prompt_sistema = """
Tu tarea es extraer el nombre de la ciudad si el usuario pregunta por el tiempo.
Debes responder EXCLUSIVAMENTE en formato JSON con la siguiente estructura:
{"ciudad": "nombre_de_la_ciudad"}
Si la pregunta no está relacionada con el tiempo o no hay ciudad, responde:
{"ciudad": "NONE"}
No añadas introducciones, ni saludos, ni formato markdown. Solo el JSON plano.
"""
response = cliente.chat.completions.create(
model="llama-3.3-70b-versatile",
messages = [
{"role": "system", "content": prompt_sistema},
{"role": "user", "content": texto}
],
response_format={"type":"json_object"}
)
try:
# Parseamos el JSON devuelto por el modelo
resultado_json = json.loads(response.choices[0].message.content)
ciudad = resultado_json.get("ciudad", "NONE").strip()
except Exception:
ciudad = "NONE"
return ciudad
...
2.3. Uso de LLM locales. Ollama¶
En el caso de que no podamos utilizar un modelo remoto de forma gratuita o controlada para nuestros propósitos, puede resultar recomendable instalar de forma local algún LLM si vamos a desarrollar agentes.
2.3.1. Primeros pasos con Ollama¶
Podemos emplear Ollama. Se trata de un gestor local de LLMs, que equivaldría al Docker de los LLMs. Desde la web oficial podemos descargarlo, y también consultar los modelos que tenemos disponibles. En cada modelo veremos algunos badges que indican las distintas versiones que hay disponibles. Por ejemplo, este modelo de llama 3.2 está disponible en una versión de 1 billón de parámetros (1B) o de 3 billones (3B).
Cuantos más parámetros tenga más ocupará desplegado en memoria RAM. Debemos analizar cuáles son los más recomendables dependiendo de nuestras características de procesador, RAM disponible y tarjeta gráfica.
2.3.2. Uso básico de Ollama¶
Una vez tengamos instalado Ollama podemos controlarlo desde línea de comandos con algunas instrucciones básicas:
ollama pull <id_modelo>descarga el modelo con el id indicadoollama run <id_modelo>pone en marcha el modelo (lo descarga también si no está disponible en local)ollama listlista los modelos disponibles en localollama rm <id_modelo>elimina el modelo indicado del repositorio local
Aquí vemos algunos ejemplos de descarga de algunos modelos que nos pueden venir bien:
# LLM Qwen ligero (1.5 billones de parámetros)
ollama pull qwen2.5-coder:1.5b
# LLM Qwen intermedio (3 billones de parámetros)
ollama pull qwen2.5-coder:3b
# LLM Llama intermedio (3 billones de parámetros)
ollama pull llama3.2:3b
# LLM Gemma 4 intermedio (4 billones de parámetros)
ollama pull gemma4:e4b
Si queremos ejecutar o probar el LLM desde terminal, escribimos la orden correspondiente. Por ejemplo:
ollama run llama3.2:3b
Se abrirá un prompt para que preguntemos al LLM. Hay que tener en cuenta que algunos modelos están basados en chain of thought (cadena de pensamiento) y expresan en terminal su razonamiento previo antes de emitir la respuesta (son algo más lentos para darla, pero también más precisos generalmente).
Si queremos finalizar la sesión basta con pulsar Ctrl + D para concluir el prompt.
2.3.3. Uso de Ollama en código¶
Desde este punto ya podríamos usar los LLM descargados con Ollama en nuestros agentes, instalando previamente el paquete ollama. El ejemplo anterior de la búsqueda del tiempo meteorológico podría quedar así:
from ollama import Client
import requests
import json
cliente = Client(host="http://localhost:11434") # Puerto por defecto de Ollama
# Función para extraer del texto del usuario la ciudad de la que saber el tiempo
def obtener_ciudad(texto):
# Creamos el prompt para el sistema
prompt_sistema = """
Tu tarea es extraer el nombre de la ciudad si el usuario pregunta por el tiempo.
Debes responder EXCLUSIVAMENTE en formato JSON con la siguiente estructura:
{"ciudad": "nombre_de_la_ciudad"}
Si la pregunta no está relacionada con el tiempo o no hay ciudad, responde:
{"ciudad": "NONE"}
No añadas introducciones, ni saludos, ni formato markdown. Solo el JSON plano.
"""
response = cliente.chat(
model="llama3.2:3b", # Elegir el LLM que más nos guste
messages = [
{"role": "system", "content": prompt_sistema},
{"role": "user", "content": texto}
],
format="json"
)
try:
# Parseamos el JSON devuelto por el modelo
resultado_json = json.loads(response['message']['content'])
ciudad = resultado_json.get("ciudad", "NONE").strip()
except Exception:
ciudad = "NONE"
return ciudad
...
Ejercicio 2
Completa el ejemplo con las funciones que faltan para obtener el tiempo de OpenWeather (esta función no cambiará respecto al ejercicio anterior) y unir e interpretar los resultados con el LLM local de Ollama, y también con Groq (en dos programas independientes)
3. IA agéntica¶
En el apartado anterior hemos hablado de agentes de IA. Sin embargo, hay una diferencia entre el concepto de agente de IA y el de IA agéntica, que veremos a continuación.
Imaginemos que estamos cansados y nos apetece una pizza.
- IA Generativa: si le decimos a una app de IA generativa "me apetece pizza" nos podría recomendar alguna pizza sabrosa, con sus ingredientes. Nos ahorra el proceso de pensar o decidir la pizza, y nos propone alternativas que quizá no hayamos pensado. Pero no va a pedir la pizza por nosotros
- Agente IA: si le decimos a un agente de IA "pídeme una pizza carbonara de la pizzería X", simplemente lo hará, pero no razonará, ni buscará mejores opciones, ni se adaptará a cambios si, por ejemplo, la pizzería no responde a su orden. Un agente IA es una entidad software capaz de interactuar con su entorno, recopilar datos y realizar acciones.
- IA agéntica: la IA agéntica, a diferencia de los agentes en sí, está orientada a un objetivo (conseguir una pizza, en este caso), y no a órdenes concretas. Para la orden anterior, sería capaz de buscar pizzerías alternativas si la que pedimos no está disponible, incluso recoger nuestros gustos habituales y pedir una que crea que nos puede gustar. En realidad, la IA agéntica controla diferentes agentes que hacen las distintas tareas simples que se les encomiendan, y los coordina para alcanzar el objetivo buscado.
3.1. Etapas de la IA agéntica¶
Un sistema de IA agéntica funciona en un bucle de cuatro etapas:
- Percepción: se recogen datos del entorno (webs, bases de datos, usuario...)
- Razonamiento: se interpreta la información recogida y se establecen los objetivos a alcanzar. Se emplean técnicas básicas como procesamiento del lenguaje natural, visión artificial o reconocimiento de patrones. A partir de aquí se evalúan posibles acciones y se prevén los resultados que se podrían alcanzar. Por ejemplo, qué resultado se obtendría aplicando un árbol de decisión sobre los datos recogidos.
- Actuación: el sistema pone en marcha la acción elegida, que puede ser muy variada: acceder a una API remota, controlar un robot, etc.
- Aprendizaje: se obtiene el feedback de la acción realizada y se da un proceso de adaptación si es necesario. Por ejemplo, si la acción tomada no da el resultado esperado, se aprende de ello y se evaluarán entonces otras acciones alternativas. En este aspecto, el aprendizaje por refuerzo o el auto-supervisado juegan un papel importante.
3.2. Limitaciones¶
La IA agéntica tiene algunas limitaciones que conviene tener presentes:
- Comprensión limitada de temas complejos, que normalmente suelen ser supervisados o gestionados por humanos.
- Dependencia de la calidad de los datos recopilados en la etapa de percepción. Si los datos recopilados no son suficientes o son incorrectos, el razonamiento y actuaciones posteriores no serán los adecuados.
- Autonomía y toma de decisiones limitada, ya que, al ser una tecnología aún emergente, no se le confía una autonomía plena para hacer su tarea por los riesgos que eso pueda conllevar. También en lo relativo a toma de decisiones que tengan algún componente ético o legal.
- Problemas en integraciones más complejas, a la hora de interactuar con otros agentes o sistemas de otras plataformas.
- Cuestiones legales en cuanto a privacidad y seguridad, en el acceso a los datos recogidos
- Se requiere una supervisión y monitoreo continuo de su actividad
3.3. Gestión de memoria en sistemas agénticos¶
Los LLM y modelos conversacionales que podemos utilizar hoy en día tienen una capacidad de memoria limitada, y medida en tokens. A medida que se alcanza el límite de tokens que se pueden gestionar, las conversaciones antiguas se pierden y estos sistemas no son capaces de recordarlas.
Sin embargo, una IA agéntica debería ser capaz de retener información de forma más duradera, tanto para poder evolucionar en su trabajo como para adaptarse mejor a su entorno. En este sentido, distinguimos dos tipos de memoria en los sistemas agénticos:
- Memoria a corto plazo (STM, Short Term Memory), que es la que se usa para la interacción inmediata. En esta memoria el sistema es capaz de recordar interacciones recientes que pertenezcan al contexto actual. Si por ejemplo decimos "Planifica una reunión con Juan mañana a las 3PM" y luego indicamos "Mejor que sea a las 4PM", el sistema reconoce que se trata de la misma reunión con Juan.
- Memoria a largo plazo (LTM, Long Term Memory), que es la que permite que el sistema evolucione y sea persistente. Se almacenan datos entre sesiones, y se permite consultar interacciones pasadas, hábitos del usuario, etc.
3.4. Sistemas multi-agente (MAS)¶
Un sistema multi-agente (MAS, Multi-Agent System), como su nombre indica, es un sistema agéntico donde intervienen coordinados varios agentes. A diferencia de los agentes simples, en estos sistemas cada agente tiene un rol específico con unas responsabilidades más delimitadas.
Para hacernos una idea de las ventajas que esto puede suponer, imaginemos la tarea de construir una casa; si se encargara una sola persona tendría que ocuparse de muy diversas tareas como diseñarla, obtener los permisos, gestionar materiales, cableados, fontanería, pintar el interior... Esto conllevaría un desarrollo mucho más lento y propenso a errores. En cambio, con un equipo trabajando de forma conjunta cada miembro (arquitecto, pintor, fontanero...) puede dedicarse de forma más especializada a su tarea, agilizando el proceso.
3.4.1. Arquitectura de un MAS¶
Los principales elementos que componen un sistema multi-agente son:
- Agentes: cada una de las unidades individuales, con sus capacidades, conocimiento y objetivos a alcanzar
- Entorno: compartido por todos los agentes. Aquí hablamos del espacio de memoria y almacenamiento donde todos operan, restricciones, etc.
- Interacciones y comunicaciones: cómo los agentes interactúan entre ellos y con el entorno. Determina cómo se distribuyen las tareas y cómo se desarrolla el trabajo colectivo.
3.4.2. Orquestando sistemas multi-agente¶
La orquestación hace referencia a cómo podemos comunicar agentes (A2A, Agent to Agent Communication). Una de las tareas importantes es encadenar múltiples prompts, gestionando distintos procesos, APIs, etc, y manteniendo un flujo lógico entre ellos. De este modo, la salida de un prompt a menudo se convierte en la entrada del siguiente... y así sucesivamente. Esto se consigue normalmente con formatos estructurados de comunicación entre agentes (por ejemplo, JSON).
Los prompts definen así qué hacer, y la orquestación cómo hacerlo. Ambas partes constituyen la capa de control del sistema agéntico.
Existen varios tipos de orquestación:
- Centralizada: uno de los agentes actúa como manager (orchestrator agent) y controla la coordinación entre el resto. Así, selecciona los agentes requeridos, les asigna responsabilidades y coordina el workflow general. Si algún agente falla en su cometido, el coordinador puede repetir la tarea o incluir otro agente adicional de apoyo.
- Descentralizada o coreografiada: no existe la figura del manager, y cada agente que interviene es autónomo y sabe qué tiene que hacer, basándose en el estado actual del sistema o los mensajes recibidos por sus compañeros. Así, cada agente genera eventos que activan a otros agentes en el proceso.
- Jerárquica: hay un manager principal que divide el gran objetivo en macro-tareas. Este manager delega estas tareas a varios sub-managers, y cada uno de estos controla de forma centralizada a su propio subequipo de agentes especialistas.
- Dinámica o emergente: las responsabilidades no están predefinidas por código ni las asigna un jefe, sino que los agentes compiten o cooperan en tiempo real. Por ejemplo, un agente puede necesitar traducir un texto, y el resto de agentes evalúa su capacidad para hacerlo y se ofrece.
4. Frameworks y plataformas¶
Para desarrollar sistemas agénticos debemos tener en cuenta y hacer uso de herramientas a distintos niveles:
- Por un lado tendríamos los modelos de base, los LLM sobre los que vamos a apoyarnos para generar los prompts para nuestros agentes. Aquí podemos elegir entre distintas alternativas como ChatGPT, Claude, Gemini... Recordemos que esta capa se va a encargar de recoger nuestros mensajes, entenderlos y razonarlos.
- Por otra parte tenemos herramientas de apoyo, tales como bases de datos de donde recuperar información, o APIs q las que consultar. Incluiríamos aquí también herramientas de orquestación para comunicar los agentes
- Los frameworks ofrecen juntas todas estas funcionalidades: memoria donde almacenar la información recogida y aprendida, modelos de razonamiento, coordinación entre agentes, etc. De este modo, el desarrollador se centra en definir el comportamiento de los agentes o del sistema, y los objetivos a alcanzar, en lugar de implementar cada componente necesario.
Los frameworks disponibles podemos catalogarlos en distintas categorías:
- Code: se requieren conocimientos de programación para definir el sistema y los objetivos a alcanzar, y a cambio ofrecen mucha flexibilidad y control. En esta categoría encontramos frameworks como LlamaIndex, LangChain o Smolagents.
- Low Code: no se requieren grandes conocimientos de programación al respecto, pero sí es necesario introducir algunas instrucciones que coordinen los componentes pre-implementados que incorporan. Aquí podemos encontrar frameworks como Langflow o CrewAI.
- No Code: son frameworks donde no hay que programar ninguna línea de código para poner el sistema en marcha. Se trabaja a través de interfaces visuales y sistemas drag and drop para colocar los componentes. Algunos framerworks de esta categoría son OpenAI Agents o n8n.
En los siguientes subapartados probaremos algunos de estos frameworks con algunos ejemplos, para analizar la forma de trabajar con ellos.
4.1. Frameworks para sistemas simples. Smolagents¶
Smolagents se define como una librería opensource en Python para crear y ejecutar agentes de forma sencilla, con pocas líneas de código. Pertenece, de hecho, al ecosistema Hugging Face, donde también tiene una web propia.
Entre sus características principales, podemos destacar la integración con el hub de Hugging Face, o que es un framework agnóstico en cuanto a modelos (podemos emplear Claude, OpenAI, etc) o herramientas externas (podemos hacer uso de herramientas como MCP Server o LangChain, entre otras).
Comenzaremos por instalar el framework en nuestro entorno:
pip install smolagents
Un ejemplo sencillo que viene en la web de Hugging Face permite probar los fundamentos de Smolagents:
import os
from smolagents import CodeAgent, InferenceClientModel
os.environ['HF_TOKEN'] = '...' # Token de Hugging Face
# Inicializa el modelo LLM por defecto de Smolagents
model = InferenceClientModel()
# Crea un agente sin herramientas externas
agent = CodeAgent(tools=[], model=model)
# Pide una tarea al agente
result = agent.run("Calculate the sum of numbers from 1 to 10")
print(result)
Podremos ver que obtenemos una salida similar a esta (observa que en la salida también se indica el modelo de inferencia por defecto que se ha cargado):
╭──────────────────────── New run ────────────────────────╮
│ │
│ Calculate the sum of numbers from 1 to 10 │
│ │
╰─ InferenceClientModel - Qwen/Qwen3-Next-80B-A3B-Thinkin─╯
━━━━━━━━━━━━━━━━━━━━━━━━━ Step 1 ━━━━━━━━━━━━━━━━━━━━━━━━━━
─ Executing parsed code: ────────────────────────────────
result = sum(range(1, 11))
final_answer(result)
─────────────────────────────────────────────────────────
Final answer: 55
[Step 1: Duration 4.85 seconds| Input tokens: 2,036 |
Output tokens: 697]
55
En el caso de querer utilizar un LLM local para no consumir créditos de forma descontrolada, podemos emplear algún modelo local de Ollama (necesitamos instalar litellm para usar la clase LiteLLMModel):
from smolagents import CodeAgent, LiteLLMModel
# Instalar "litellm" para usar esta clase
model = LiteLLMModel(
model_id="ollama/llama3.2:3b",
api_base="http://localhost:11434"
)
agent = CodeAgent(tools=[], model=model)
result = agent.run("Calculate the sum of numbers from 1 to 10")
print(result)
4.1.1. Ejemplo: búsqueda del tiempo que hace¶
Vamos a usar Smolagents para generar un sistema que asista al usuario cuando quiera consultar el tiempo en una determinada localidad, de forma similar a como hemos hecho en un ejemplo previo. Pero, en este caso, será el propio agente el que se encargue de buscar la información meteorológica en la web, a través de una herramienta de búsqueda. Emplearemos en esta ocasión el LLM de Groq:
import os
from smolagents import CodeAgent, LiteLLMModel, DuckDuckGoSearchTool
os.environ["GROQ_API_KEY"] = "..."
model = LiteLLMModel(
model_id="groq/llama-3.3-70b-versatile",
# Máximo 30 segundos por petición completa
timeout=30,
# Máximo 15 segundos esperando el primer token (evita cuelgues de red)
stream_timeout=15,
# Si falla, que no reintente eternamente en bucle
max_retries=1
)
agent = CodeAgent(
tools=[DuckDuckGoSearchTool()],
model=model,
max_steps=5
)
texto = input("Introduce tu texto:\n")
prompt_usuario = f"""
Busca en internet el tiempo actual según la frase que diga el usuario.
Lee los resultados, extrae la temperatura en grados Celsius (ºC) y el estado del cielo.
Devuelve un mensaje breve en español con el resultado final."
El usuario introduce esta frase: {texto}
"""
result = agent.run(prompt_usuario)
print(result)
Sobre el ejemplo anterior, hay que hacer algunas puntualizaciones:
- La primera es que hay varios buscadores que elegir. En este caso hemos usad
DuckDuckGoSearchTool, para lo que es necesario instalar el paqueteddgs. También tenemos disponibleWebSearchTool, directamente incorporado en Smolagents - Notar cómo, al ejecutar este ejemplo, si los resultados que encuentra el agente no le son satisfactorios, hace otra búsqueda distinta para conseguirlo. El
CodeAgentfunciona mediante un ciclo continuo de pensamiento y acción llamado ReAct (Reason + Act). No se limita a ejecutar el código y conformarse con lo que salga, sino que evalúa activamente el resultado. Esto también puede ocasionar que se hagan demasiadas peticiones al LLM y consumamos el saldo gratuito sin darnos cuenta en algunos casos. Los parámetros adicionales al crear el modelo (constructor deLiteLLMModel) y el agente (constructor deCodeAgent, parámetromax_steps) evitan un bucle continuo de intentos, o un tiempo de espera excesivo.
4.1.2. Ejemplo: búsqueda en una base de datos¶
Vamos a desarrollar ahora otro agente que busque por nosotros información en una base de datos. Para simplificar un poco el proceso emplearemos una base de datos SQLite, así no será necesario instalar ningún SGBD para el ejemplo. Para gestionarla desde Python instalaremos la librería sqlalchemy, que también permite trabajar con otros SGBD conocidos como MySQL u Oracle.
En este caso le deberemos proporcionar al agente como herramienta (tool) una función para buscar en la base de datos. Recibirá como parámetro una query SQL (que el propio agente le pasará) y la ejecutará contra la base de datos, devolviendo el resultado en forma de texto:
from smolagents import tool
@tool
def buscar(query: str) -> str:
"""
Función para buscar en la base de datos
Es importante poner esta descripción para luego poderla
modificar por código (description) y dar información al agente sobre la BD
Args:
query: La consulta a realizar, en SQL
"""
resultado = ""
# La variable "conexion" se creará fuera, conexión global a la BD
filas = conexion.execute(text(query))
for fila in filas:
resultado += "\n" + str(fila)
return resultado
Además, dejaremos hecha una pequeña base de datos de ejemplo con la que trabajar:
# Creamos la BD en memoria para simplificar el proceso
from sqlalchemy import (
create_engine,
MetaData,
Table,
Column,
String,
Integer,
Float,
insert,
inspect,
text,
)
# Función para insertar filas en una tabla
def insertar_filas(filas, tabla, con):
for fila in filas:
stmt = insert(tabla).values(**fila)
con.execute(stmt)
con.commit()
# Creación de la BD y sus tablas, e inserción de datos
engine = create_engine(
"sqlite:///:memory:",
# Útil porque CodeAgent usa un hilo separado para acceder a la BD
# y podría dar error de seguridad
connect_args={"check_same_thread": False}
)
# Útil al ser una BD en memoria, si no se borraría en cada conexión
conexion = engine.connect()
metadata_obj = MetaData()
# Tabla 1: recibos de un restaurante
tabla1 = "recibos"
recibos = Table(
tabla1,
metadata_obj,
Column("id", Integer, primary_key=True),
Column("nombre_cliente", String(16), primary_key=True),
Column("precio", Float),
Column("propina", Float)
)
metadata_obj.create_all(conexion)
filas = [
{"id": 1, "nombre_cliente": "Juan Pérez", "precio": 20.06, "propina": 2.34},
{"id": 2, "nombre_cliente": "Ana García", "precio": 41.28, "propina": 5.56},
{"id": 3, "nombre_cliente": "Mario Vázquez", "precio": 55.12, "propina": 8.13},
{"id": 4, "nombre_cliente": "Laura Martínez", "precio": 33.84, "propina": 4.45}
]
insertar_filas(filas, recibos, conexion)
Ahora vamos a facilitarle en la descripción de la herramienta buscar la estructura de tablas de la base de datos:
# Añadimos descripción detallada de la BD
descripcion = """La herramienta te permite hacer consultas SQL contra la
base de datos, y devolver el resultado en formato texto.
Se pueden consultar las siguientes tablas:"""
inspector = inspect(conexion)
for tabla in ["recibos"]:
columns_info = [(col["name"], col["type"]) for col in inspector.get_columns(tabla)]
descripcion_tabla = f"Tabla '{tabla}':\n"
descripcion_tabla += "Columnas:\n" + "\n".join([f" - {name}: {col_type}" for name, col_type in columns_info])
descripcion += "\n\n" + descripcion_tabla
# Añadimos la descripción a la herramienta de búsqueda
print(descripcion)
buscar.description = descripcion
Ejercicio 3
Completa el ejercicio creando un agente Smolagents que:
- Le pregunte al usuario qué quiere saber sobre la base de datos
- Realice la consulta pertinente y muestre los resultados encontrados
Ejercicio 4
Añade una segunda tabla llamada camareros con campos id_recibo (entero, clave primaria) y nombre (string, clave primaria). Añade algunas filas que vinculen ids de recibos de la tabla anterior con camareros, e incorpora también esta información a la herramienta buscar. Pregunta ahora a la BD qué camarero obtuvo más dinero en propinas.
4.2. Frameworks para sistemas multi-agente. CrewAI¶
Las tareas de comunicar distintos agentes, coordinarlos y planificarlos en el tiempo puede ser muy costosa (y propensa a errores) si la tenemos que hacer de forma manual. Es por ello que un framework orientado a MAS nos puede facilitar mucho la tarea, ya que incorpora utilidades y herramientas para comunicación entre agentes, asignación de roles, orquestación... En este apartado echaremos un vistazo a uno de ellos: CrewAI.
CrewAI es un framework para sistemas MAS orientado en definir roles claros, objetivos y colaboración entre agentes. En los siguientes subapartados aprenderemos algunas nociones básicas de este framework junto a algunos ejemplos prácticos.
4.2.1. Componentes principales¶
En la documentación oficial de CrewAI podemos ver sus principales características y componentes, que son:
- Crew: se encarga de gestionar los equipos de agentes, la colaboración entre ellos y supervisar las salidas generadas.
- Agentes: cada uno tiene un rol específico, y puede utilizar las herramientas que se le designen para realizar su tarea, tomando decisiones de forma autónoma.
- Proceso: define los patrones de colaboración o comunicación entre agentes y controla la asignación de tareas
- Tareas: asignaciones de trabajo individuales para cada agente, con objetivos claros y específicos.

Componentes de CrewAI. Fuente: documentación oficial
4.2.2. Instalación¶
Dentro de la documentación oficial también podemos consultar las pautas de instalación.
Como podemos ver, CrewAI utiliza uv como su gestor de paquetes (una herramienta similar a pip para Python). Así que deberemos instalarla en nuestro sistema.
# Linux/Mac (usar uno u otro comando, dependiendo de cuál tengamos disponible)
curl -LsSf https://astral.sh/uv/install.sh | sh
wget -qO- https://astral.sh/uv/install.sh | sh
# Windows
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
Una vez tengamos instalado uv, podemos usarlo para instalar crewai:
# CUIDADO! En la documentación puede aparecer el paquete "crewai", pero
# no funciona. Se recomienda instalar este otro:
uv tool install crewai-cli
También podemos ejecutar este comando para asegurarnos de tener en el PATH del sistema la carpeta con el comando crewai:
uv tool update-shell
Advertencia
Acudir a la documentación oficial en caso de tener problemas ejecutando los comandos.
Para verificar la instalación podemos ejecutar:
uv tool list
Y ver algo similar a esto (los números de versión pueden cambiar):
crewai-cli v1.14.5
- crewai
Si necesitamos actualizar la versión de crewai en un futuro podemos ejecutar:
uv tool install crewai-cli --upgrade
4.2.3. Un ejemplo sencillo¶
Vamos a comenzar con un MAS sencillo. Crearemos un sistema de dos agentes: uno que buscará información sobre un tema determinado y otro que redactará un documento dando forma a la información recogida, que guardaremos en formato Markdown. Utilizaremos, evidentemente, un LLM como soporte.
Necesitaremos instalar las librerías crewai y crewai-tools en nuestro entorno Python:
pip install crewai crewai-tools
En primer lugar, configuraremos el LLM que vamos a utilizar. En este caso elegimos un LLM local con Ollama, pero podría ser cualquier otro. El constructor de la clase LLM de crewai permite indicar la API Key si es necesario:
import os
from crewai import LLM, Agent, Task, Crew
from crewai_tools import SerperDevTool
crewai_llm = LLM(
model="ollama/llama3.2:3b",
#api_key=...
temperature=0.0 # Baja temperatura para resultados más consistentes
)
Ahora vamos a definir las características del agente de búsqueda, que empleará la herramienta SerperDevTool para buscar. Para ello necesitamos registrarnos en serper.dev y obtener una API Key.
os.environ['SERPER_API_KEY'] = '...'
herramienta_busqueda = SerperDevTool()
agente_busqueda = Agent(
role="Especialista en búsqueda",
goal="Recoger información precisa y útil en la web relacionada con un tema",
backstory="Un buscador experto capaz de encontrar información de calidad rápidamente",
tools=[herramienta_busqueda],
verbose=True,
llm=crewai_llm
)
De un modo similar creamos el agente de escritura (que no necesita herramientas externas):
agente_escritura = Agent(
role="Escritor de contenido",
goal="Crear una explicación clara y estructurada utilizando la información recopilada",
backstory="Un escritor habilidoso que convierte información genérica en contenido pulido",
verbose=True,
llm=crewai_llm
)
Definimos a continuación la tarea que hará cada agente, aunque no se la asignamos aún (lo haremos después)
tarea_busqueda = Task(
description="Busca en la web y recoge información sobre: Cómo funciona el aprendizaje por refuerzo?",
expected_output="Un listado detallado pero simple de datos (en forma de puntos en una lista)",
agent=None # Se asigna después
)
tarea_escritura = Task(
description="Utilizando un resumen de búsqueda, escribe una explicación final entendible para principiantes",
expected_output="Una explicación pulida sobre aprendizaje por refuerzo",
agent=None
)
Finalmente, creamos el grupo (crew) y lo ponemos en marcha para recoger el resultado:
tarea_busqueda.agent = agente_busqueda
tarea_escritura.agent = agente_escritura
crew = Crew(
agents=[agente_busqueda, agente_escritura],
tasks=[tarea_busqueda, tarea_escritura],
verbose=True
)
resultado = crew.kickoff()
with open("resultado.md", "w", encoding="utf-8") as f:
f.write(resultado.raw)
Ejercicio 5
Une las piezas anteriores para crear el MAS con CrewAI y comprueba el resultado
Ejercicio 6
Dado un fichero de logs que refleja problemas en el acceso a una web como este:
2026-05-22 08:00:05 [INFO] Sistema iniciado correctamente. Servidor Web listo.
2026-05-22 08:15:30 [WARNING] Conexiones concurrentes en puerto 443 superan el 80%.
2026-05-22 08:16:01 [ERROR] DB_TIMEOUT: La consulta a la tabla 'usuarios' tardó 5.4 segundos.
2026-05-22 08:16:10 [ERROR] DB_TIMEOUT: La consulta a la tabla 'pedidos' tardó 7.1 segundos.
2026-05-22 08:20:00 [INFO] Tarea programada 'Limpieza_Cache' ejecutada con éxito.
2026-05-22 08:35:42 [WARNING] Uso de Memoria RAM crítico: 92% ocupado.
2026-05-22 08:36:00 [CRITICAL] OUT_OF_MEMORY: El proceso 'Generador_PDF' fue terminado por el sistema.
2026-05-22 08:36:05 [ERROR] HTTP_500: Error interno en el endpoint '/descargar-factura'.
2026-05-22 08:45:12 [INFO] Tráfico normalizado. Conexiones concurrentes al 35%.
2026-05-22 08:50:22 [ERROR] DB_TIMEOUT: La consulta a la tabla 'pedidos' tardó 6.2 segundos.
Crea un sistema MAS con CrewAI que tendrá 3 agentes:
- El primero leerá el contenido del fichero de logs usando la herramienta
FileReadTool(disponible directamente encrewai_tools). - El segundo analizará el contenido proporcionado por el primero y detectará las anomalías y cuellos de botella, para proponer mejoras
- El tercero redactará un documento bien formado con los problemas y mejoras detectados
4.3. Otros frameworks¶
En este apartado echaremos un vistazo más rápido a otros frameworks disponibles:
- Langflow es una plataforma open source gratuita para crear flujos de trabajo de forma visual, editando únicamente el código de lo que queramos adaptar, lo que la sitúa en el campo de los frameworks low code. Comenzó como una interfaz visual para LangChain, pero ha evolucionado hasta convertirse en un entorno de desarrollo completo para arquitecturas multi-agente.
- Flowise es un framework visual y gratuito para desarrollar sistemas mediante bloques conectados. Está construido sobre Node.js y TypeScript, con licencia MIT.
- LangChain proporciona bloques de código para crear aplicaciones basadas en LLM. Dispone de una cuenta gratuita limitada por mes.
5. El protocolo MCP¶
Hasta hace muy poco los LLMs y los agentes de IA vivían "aislados" en sus propias plataformas. Si un desarrollador quería que su agente de IA pudiera leer una base de datos, revisar el correo o interactuar con GitHub, tenía que programar una integración a medida utilizando APIs complejas. Este enfoque planteaba tres grandes inconvenientes:
- Falta de estándares: cada aplicación (Slack, Notion, PostgreSQL) tiene una API totalmente distinta.
- Duplicación de trabajo: si cambiamos de modelo de IA (por ejemplo, de OpenAI a Anthropic), puede tocar reescribir gran parte del código de integración.
- Seguridad: dar acceso directo a un agente de IA a todo un sistema o base de datos es un riesgo crítico de seguridad.
Para solucionar esto, a finales de 2024 nació MCP (Model Context Protocol), un estándar abierto que funciona como el "enchufe universal" para conectar los modelos de IA con el mundo real.
5.1. Arquitectura de MCP¶
MCP es un protocolo de arquitectura abierta de tipo cliente-servidor que permite a los desarrolladores construir conexiones seguras, uniformes y bidireccionales entre los modelos de IA y las fuentes de datos o herramientas externas.
Para entender cómo viaja la información, el protocolo divide el ecosistema en tres partes fundamentales:
- El Cliente MCP (Host): entorno o aplicación donde el usuario interactúa con la IA. El cliente es el encargado de iniciar la conexión.
- El Servidor MCP (Server): programa ligero e independiente que expone datos o funciones específicas a través del protocolo MCP. Actúa como el "traductor seguro" entre la IA y el servicio final. Por ejemplo, un servidor MCP para Postgres, un servidor MCP para la API de Slack, un servidor MCP para leer archivos locales...
- El Modelo (LLM): el cerebro de la IA (Claude, GPT, Llama...). No se conecta directamente a los datos, sino que le pide al Cliente que use las herramientas que el Servidor ha puesto a su disposición.
5.2. Capacidades de MCP¶
Un servidor MCP puede ofrecerle a la IA tres tipos de superpoderes, llamados capacidades (capabilities):
- Recursos (Resources): datos de solo lectura que el modelo puede consultar para enriquecer su contexto. Por ejemplo, el contenido de un archivo de texto, o la documentación de una API
- Herramientas (Tools): funciones ejecutables de lectura y escritura que permiten a la IA realizar acciones que cambian el estado de las cosas. Por ejemplo, crear un commit en GitHub, o ejecutar una operación matemática
- Plantillas (Prompts): guías de texto predefinidas proporcionadas por el servidor para ayudar al usuario a interactuar con el modelo de manera óptima para esa herramienta concreta.
5.3. Ejemplo¶
Imaginemos que queremos desarrollar un agente de investigación financiera sobre empresas basadas en IA, que busque datos en tiempo real. Podemos usar CrewAI, y definir un agente que busque noticias sobre evolución de la IA, y analice los 3 hitos financieros más importantes de las empresas de IA. El agente debe buscar datos en el exterior, y ahí es donde utilizaremos MCP para comunicarnos con un buscador externo, en este caso uno llamado Exa AI, especializado en IA (debemos obtener una API Key)
El código podría quedar más o menos así (necesitamos instalar mcp además de crewai):
import os
from crewai import LLM, Agent, Task, Crew, Process
os.environ["EXA_API_KEY"] = "..."
exa_key = os.getenv("EXA_API_KEY")
crewai_llm = LLM(
model="ollama/llama3.2:3b",
#api_key=...
temperature=0.0 # Baja temperatura para resultados más consistentes
)
# Investigador financiero
investigador_financiero = Agent(
role="Analista de Investigación Financiera",
goal="Buscar y consolidar las últimas noticias sobre la evolución de la IA en 2026.",
backstory="Eres un analista experto con acceso directo a un motor de búsqueda avanzado para IA.",
verbose=True,
llm=crewai_llm,
# Usamos la URL del servidor MCP de Exa pasándole la API Key
mcps=[
f"https://mcp.exa.ai/mcp?api_key={exa_key}"
]
)
# Tarea asociada (usando el servidor MCP)
tarea_analisis = Task(
description=(
"Utiliza la herramienta de búsqueda de tu servidor MCP para encontrar "
"los 3 hitos financieros más importantes de las empresas de IA este año. "
"Genera un resumen ejecutivo de cada uno."
),
expected_output="Un informe en Markdown con los 3 hitos y sus resúmenes.",
agent=investigador_financiero
)
# Crear el Crew y ejecutar
equipo = Crew(
agents=[investigador_financiero],
tasks=[tarea_analisis],
process=Process.sequential
)
print("Iniciando el agente con soporte MCP...")
resultado = equipo.kickoff()
print("RESULTADO DEL INFORME:")
print(resultado)