Conexión entre tecnologías¶
En el mundo actual la inteligencia artificial no se limita a una sola tecnología, sino que se manifiesta como un ecosistema interconectado donde voz, texto, imágenes, sonidos y datos trabajan de forma conjunta para crear experiencias inteligentes. Esta integración de medios permite desarrollar sistemas capaces de comprender el entorno, comunicarse de forma natural con los humanos y tomar decisiones informadas. En este contexto, conectar tecnologías —como el reconocimiento de voz, el análisis de imágenes o el procesamiento de lenguaje natural— no solo enriquece las capacidades de la IA, sino que también abre un abanico de posibilidades educativas y creativas. Proyectos como asistentes por voz, clasificadores de imágenes o sistemas de análisis de sentimientos demuestran cómo estas tecnologías pueden dialogar entre sí para resolver problemas reales de manera intuitiva e innovadora.
A lo largo de este documento plantearemos algunos ejemplos de proyectos que se pueden llevar a cabo conectando estas tecnologías.
1. Asistente por voz¶
Como primer proyecto vamos a desarrollar un asistente por voz, que reconozca y transcriba un audio con una determinada orden, la sepa interpretar y ejecute el comando asociado. Comenzaremos con una versión básica donde el asistente responderá a dos órdenes distintas:
- Abrir el navegador
- Indicar la hora actual
Posteriormente lo iremos enriqueciendo con otras acciones adicionales.
Para la transcripción de voz a texto podemos emplear el servicio de Speech de Azure, que hemos visto en otros documentos. Definiremos una función que devuelva el texto transcrito:
import azure.cognitiveservices.speech as speechsdk
# Configuración general
KEY ='...' # Coloca aquí tu clave de uso
REGION = 'francecentral' # Coloca aquí la región donde ubicaste el recurso
config_speech = speechsdk.SpeechConfig(subscription=KEY, region=REGION)
config_speech.speech_recognition_language="es-ES"
config_audio = speechsdk.audio.AudioConfig(use_default_microphone=True)
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=config_speech,
audio_config=config_audio)
def recoger_orden():
print("Esperando instrucciones...")
resultado = speech_recognizer.recognize_once_async().get()
orden = ""
if resultado.reason == speechsdk.ResultReason.RecognizedSpeech:
orden = resultado.text
print("Reconocido:", orden)
else:
print("No se ha reconocido audio")
return orden.lower()
Nota
Recuerda que, para poder utilizar el asistente por voz de Azure, necesitas haber creado un recurso de voz (Speech) en el portal de azure, y haber instalado en local el paquete azure-cognitiveservices-speech.
Nuestro programa principal va a consistir en un bucle donde recogeremos lo que el usuario diga y ejecutaremos una u otra opción en función de lo que se haya entendido:
from datetime import datetime
import webbrowser
...
orden = ""
while "salir" not in orden and "cerrar" not in orden:
orden = recoger_orden()
if "hora" in orden:
print("Son las", datetime.now().strftime('%H:%M:%S'))
elif "navegador" in orden:
webbrowser.open("https://www.google.com")
1.1. Ampliación: obtención del tiempo en una ciudad¶
Como ampliación de este proyecto, vamos a añadir la opción de conocer el tiempo que hace en una determinada ciudad del mundo. Para ello haremos uso de la API proporcionada por openweathermap. Debemos acceder aquí para registrarnos, y obtener una API key con la que consultar la información. Aquí tenemos información sobre el uso de la API.
Ejercicio 1
Amplía el asistente de voz visto en el ejemplo anterior haciendo que responda a preguntas del tipo "¿Qué tiempo hace en XXXX?" o "Quiero saber el clima en/de XXXX". Para ello, debes tener en cuenta estas consideraciones sobre la API de OpenWeatherMap:
- Para incluir en la URL un nombre de ciudad, debes utilizar el parámetro
qen la URL (por ejemplo,q=Alicante) - Las temperaturas que devuelve el JSON están en grados Kelvin por defecto. Para que las devuelva en grados centígrados debemos indicar el parámetro
unit=metrics. - Para especificar que queremos la respuesta en español también deberemos indicar el parámetro
lang=esen la URL.
1.2. Ampliación: uso de la cámara¶
Añadimos ahora una segunda funcionalidad a nuestro asistente para que nos diga lo que capta a través de una cámara conectada al ordenador, mediante la orden ¿Qué ves?.
Para acceder a la cámara usaremos la librería opencv, para lo que debemos instalar el paquete opencv-python. Esta función detecta la primera cámara conectada al ordenador y graba en el fichero captura.jpg una captura tomada con ella. Devuelve True si ha podido tomar la captura y False en caso contrario:
# Instalar opencv-python
import cv2
...
def capturar_imagen():
cam = cv2.VideoCapture(0) # Primera cámara disponible
resultado = True
if not cam.isOpened():
resultado = False
else:
ret, frame = cam.read()
if ret:
cv2.imwrite("captura.jpg", frame)
else:
resultado = False
cam.release()
cv2.destroyAllWindows()
return resultado
Ejercicio 2
Añade el servicio al asistente para que responda a la orden ¿Qué ves? o similares. Captura para ello una imagen con la cámara y utiliza el servicio de análisis de imágenes de Azure para que te devuelva una descripción de la misma (caption) o los objetos que encuentra (objects, en el caso de no tener la descripción disponible).
Nota
Ten en cuenta que el servicio de Azure devolverá la descripción o los objetos en inglés (en el momento de escribir estas líneas no está disponible el servicio en español). Puedes también usar el recurso Translator de Azure para hacer una traducción al español, o utilizar cualquier otro traductor que conozcas.
En cuanto al traductor de Azure, puedes invocarlo con una petición como esta:
requests.post(URL_TRADUCTOR + "?api-version=3.0&to=es",
json=[{"Text": texto}], headers=cabeceras_traductor)
Las cabeceras de la petición son las habituales, junto con la región:
cabeceras_traductor = {"Ocp-Apim-Subscription-Key": KEY_TRADUCTOR,
"Content-Type": "application/json",
"Ocp-Apim-Subscription-Region": REGION_TRADUCTOR}
Ejercicio 3
Añade un par de mejoras más al asistente:
- Hacer que nuestro asistente hable en lugar de escribir mensajes por pantalla (usando la API de síntesis de voz de Azure)
- Hacer que se abra un buscador con el texto de la orden en el caso de que no se reconozca como ninguna de las definidas
1.3. Otras mejoras¶
Además de las ampliaciones hechas en los apartados anteriores, podemos convertir nuestro programa Python en una aplicación que se inicie con el arranque del sistema operativo, y se quede en segundo plano a la escucha de alguna orden que la active, como por ejemplo "Hola, asistente".
Para ello debemos tener en cuenta varios pasos a realizar. En primer lugar, debemos convertir nuestro programa Python en un ejecutable (Windows, en nuestro ejemplo). Instalamos la herramienta pyinstaller con el comando pip install pyinstaller, y luego convertimos el fichero Python en ejecutable con algo como esto:
pyinstaller --noconsole --onefile fichero_asistente.py
Nota
El parámetro --noconsole es para que no se abra una consola o terminal (no es necesario si todo va por voz) y el segundo para que se empaquete todo en un único fichero ejecutable.
Ahora debemos iniciar la aplicación con el arranque del sistema Windows. Para ello, podemos copiar un acceso directo de la misma en la carpeta C:\Users\<tu_usuario>\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Startup.
Con los pasos anteriores conseguimos que nuestra aplicación arranque con el sistema y se quede constantemente escuchando órdenes, hasta que le digamos que termine. Esto puede consumir muchos recursos en el bucle de espera de instrucciones. Un paso final correcto sería hacer que la aplicación quede en segundo plano hasta que una instrucción la active. Una forma eficiente de hacer esto es emplear la librería porcupine, siguiendo estos pasos:
- Instalar las librerías necesarias con
pip install pvporcupine pyaudio - Conseguir una clave gratuita para uso de porcupine. Para ello nos registramos en esta web y copiamos la clave de acceso que nos faciliten.
- Finalmente, descargamos un modelo que aprenda la hot word o palabra de activación que decidamos. Podemos acceder aquí y completar la información que nos piden: el idioma en que decimos el texto, el texto que debemos identificar y depués podemos entrenar el modelo con el micrófono.
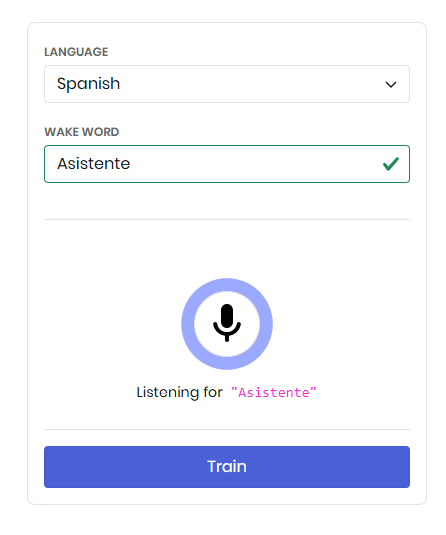
- Una vez probado, podemos darle a Train para descargar el modelo para el sistema donde lo vayamos a utilizar (por ejemplo, Windows). Se descargará un archivo que contiene el asistente entrenado (fichero con extensión
.ppn).
A partir de aquí se puede integrar este modelo con nuestro asistente de voz, y volver a generar el ejecutable con el modelo integrado. No es un paso sencillo, pero en la web de porcupine tienes información sobre cómo hacerlo en Python.
2. Clasificador de música¶
Como segundo proyecto vamos a desarrollar una red neuronal que clasifique estilos musicales. La entrenaremos con una batería de archivos MP3, para que aprenda a clasificarlos en un conjunto predefinido de estilos musicales, y después la utilizaremos para que nos clasifique la música que tengamos disponible.
2.1. Procesamiento de los archivos de audio¶
Como puedes imaginar, no podemos proporcionar directamente un archivo de audio a una red neuronal. Necesitamos convertir ese archivo de audio en una representación que la red pueda entender. Tenemos principalmente dos alternativas.
2.1.1. Espectrogramas¶
Una primera opción es convertir los archivos de audio en imágenes que representen el contenido frecuencial del audio a lo largo del tiempo, llamadas espectrogramas. En el eje horizontal (X) se representa el tiempo del audio y en el eje vertical (Y) las frecuencias que se escuchan en ese tiempo.
Se marcan con mayor o menor brillo las intensidades de cada frecuencia; sonidos más continuados, como por ejemplo notas graves o bajos, se marcarán con líneas horizontales gruesas, y líneas onduladas o rayas rápidas horizontales indicarían distintos tonos de voz o de instrumentos.
Aquí vemos una imagen de ejemplo:
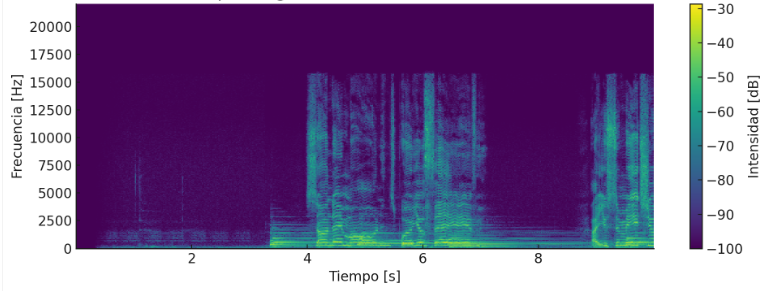
Como podrás imaginar, la utilidad que tiene generar el espectrograma de cada canción es hacerlo pasar después por una red convolucional que analice las distintas imágenes con las frecuencias y pueda clasificar así las canciones.
2.1.2. Secuencias numéricas MFCC¶
Una segunda alternativa es generar vectores numéricos que codifiquen de algún modo las canciones. Uno de estos vectores es el MFCC (Mel-Frequency Cepstral Coefficients), que genera un vector de coeficientes numéricos que resumen el contenido frecuencial del audio. Cada vector representa una porción de audio, y toda la secuencia de vectores define cómo va cambiando el audio con el tiempo. El resultado es una matriz bidimensional donde cada fila es un fragmento de tiempo del audio (por ejemplo, 13 coeficientes (columnas) por 500 frames o divisiones del audio (filas)).
En este caso, estas matrices numéricas se harían pasar por una red recurrente para que analice la secuencia de valores numéricos, representando la secuencia de sonidos de la canción (importa también el orden en que están dados los valores en la secuencia).
2.1.3. Nuestro dataset¶
Como banco de datos usaremos un repositorio público de música, como es FMA (Free Music Archive). En este repositorio de GitHub tienes enlaces a los elementos relevantes del mismo, como por ejemplo:
- Metadatos de los archivos de audio. El fichero
genres.csvdentro de ese ZIP contiene la codificación numérica de cada género musical identificado, y el ficherotracks.csvguarda información de cada canción, incluyendo el género al que pertenece. - Hay también paquetes de archivos de distintos tamaños para entrenar (pequeño, mediano, grande), aunque son bastante voluminosos y reconocen varios géneros. Para la prueba que haremos aquí nos limitaremos a un dataset más reducido que hemos preparado a partir del repositorio general, y con unos pocos géneros de prueba. Puedes descargarlo aquí.
Nota
Si prefieres crear tu propio dataset con los géneros de canciones que te interesen, puedes descargar este script y ajustarlo a tu medida, siguiendo las instrucciones que se indican en él. Los géneros disponibles los puedes consultar en el CSV genres.csv de los metadatos de FMA comentado antes.
2.1.4. Ejemplo¶
En nuestro ejemplo vamos a generar los espectrogramas de las canciones de nuestro dataset. Emplearemos para ello una librería de Python llamada librosa (que deberás instalar si no lo has hecho antes), junto con NumPy y Matplotlib para generar las imágenes de los espectrogramas.
Este código toma todos los archivos de audio que hay en la subcarpeta dataset_canciones (divididos en una carpeta por género) y genera el espectrograma de cada uno en la subcarpeta espectrogramas. También puedes descargar aquí los espectrogramas ya generados para los géneros que vamos a probar en nuestro ejemplo.
El siguiente paso es crear una red convolucional que lea de la carpeta espectrogramas los espectrogramas de las canciones, clasificados por géneros, y aprenda a identificar el género de cada canción. Nuestra red podría quedar así:
from keras.utils import image_dataset_from_directory
from keras.models import Sequential
from keras.applications import MobileNetV2
from keras.layers import Rescaling, Dense, GlobalAveragePooling2D, RandomFlip, RandomRotation, RandomZoom
TAM_IMAGEN = (128, 128)
clases=['Electronic', 'Folk', 'Pop', 'Rock']
# Carga de imágenes de entrenamiento y test
train_dataset = image_dataset_from_directory(
'.\\espectrogramas',
validation_split=0.2,
subset='training',
seed=1,
image_size=TAM_IMAGEN,
labels='inferred',
label_mode='categorical',
class_names=clases
)
test_dataset = image_dataset_from_directory(
'.\\espectrogramas',
validation_split=0.2,
subset='validation',
seed=1,
image_size=TAM_IMAGEN,
labels='inferred',
label_mode='categorical',
class_names=clases
)
normalizar = Rescaling(1./255)
data_augmentation = Sequential([
RandomFlip("horizontal"),
RandomRotation(0.1),
RandomZoom(0.1),
])
train_dataset = train_dataset.map(lambda x, y: (data_augmentation(normalizar(x)), y))
test_dataset = test_dataset.map(lambda x, y: (normalizar(x), y))
# Modelo
extractor = MobileNetV2(input_shape=TAM_IMAGEN + (3,), include_top=False, weights='imagenet')
extractor.trainable = False
modelo = Sequential([
extractor,
GlobalAveragePooling2D(),
Dense(128, activation='relu'),
Dense(len(clases), activation='softmax')
])
modelo.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
modelo.fit(train_dataset, validation_data=test_dataset, epochs=15)
modelo.save("clasificador_canciones.keras")
Ahora podemos probar la red con nuevas canciones MP3, y que las clasifique en uno de los géneros establecidos. Aquí tenéis un pequeño conjunto de imágenes de prueba, extraído también del repositorio FMA anterior. Ubicaremos en la carpeta canciones las canciones que queramos identificar, y el programa cargará el modelo entrenado, generará el espectrograma de las canciones de esa carpeta (o de las canciones nuevas que no hayamos procesado aún) y las guardará en un CSV que será nuestra base de datos musical, asociada a esa carpeta musica.
import librosa
import librosa.display
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from tensorflow.keras.models import load_model
from tensorflow.keras.preprocessing.image import img_to_array, load_img
import os
# Parámetros de configuración
carpeta_mp3 = "canciones"
TAM_IMAGEN = (128, 128)
clases=['Electronica', 'Folk', 'Pop', 'Rock']
temp_espectrograma = "temp_espectrograma.png"
# Cargar modelo y CSV de canciones (si existe)
modelo = load_model("clasificador_canciones.keras")
try:
datos = pd.read_csv("canciones.csv")
except FileNotFoundError:
datos = pd.DataFrame(columns=["fichero", "genero"])
for archivo in os.listdir(carpeta_mp3):
if archivo.lower().endswith(".mp3"):
# Si ya existe en el DataFrame, lo salta
if archivo in datos["fichero"].values:
print(f"Ya procesado: {archivo}")
else:
print(f"Procesando: {archivo}")
ruta_mp3 = os.path.join(carpeta_mp3, archivo)
# Cargar y convertir a espectrograma
y, sr = librosa.load(ruta_mp3, duration=30)
S = librosa.feature.melspectrogram(y=y, sr=sr, n_mels=128)
S_dB = librosa.power_to_db(S, ref=np.max)
# Guardar como imagen temporal
plt.figure(figsize=(1.28, 1.28), dpi=100)
librosa.display.specshow(S_dB, sr=sr, x_axis=None, y_axis=None)
plt.axis('off')
plt.tight_layout(pad=0)
plt.savefig(temp_espectrograma, bbox_inches='tight', pad_inches=0)
plt.close()
# Cargar imagen y preparar para la red
img = load_img(temp_espectrograma, target_size=TAM_IMAGEN)
img_array = img_to_array(img) / 255.0
img_array = np.expand_dims(img_array, axis=0)
# Predicción
pred = modelo.predict(img_array)
indice = np.argmax(pred)
genero = clases[indice]
prob = np.max(pred)
print(f"{archivo} → {genero} ({prob:.2%})")
# Añadir al DataFrame
nueva_fila = {"fichero": archivo, "genero": genero}
datos = pd.concat([datos, pd.DataFrame([nueva_fila])], ignore_index=True)
datos.to_csv("canciones.csv", index=False)
Ejercicio 4
Crea con el código anterior una red que identifique géneros de canciones. Para ello, sigue los pasos a continuación:
- Descarga los espectrogramas de las canciones y cópialos a una subcarpeta
espectrogramas(con una subcarpeta por cada género) - Implementa el fichero
clasificador_canciones_train.pycon la red convolucional que entrene sobre la carpeta de espectrogramas. Guarda el resultado del modelo entrenado - Guarda unos MP3 de prueba en una subcarpeta
cancionesy crea el ficheroclasificador_canciones.pycon el código para extraer una a una las canciones de la carpeta, generar su espectrograma y clasificarla, usando el código anterior
Ejercicio 5
Una vez tengas las canciones clasificadas y añadidas al CSV, prueba a integrarlas con el asistente de voz de ejercicios anteriores para que responda a la orden Pon música XXXX, siendo XXXX uno de los géneros musicales identificados. Lo que hará el asistente es elegir al azar una de las canciones de esa categoría y reproducirla. Para reproducir música puedes usar la librería pygame:
import pygame
pygame.mixer.init()
pygame.mixer.music.load("archivo.mp3")
pygame.mixer.music.play()
# La ejecución es asíncrona, el programa sigue ejecutando después
# Si queremos esperar podemos hacer esto:
while pygame.mixer.music.get_busy():
pygame.time.Clock().tick(10) # 100 ms
3. Chatbot para una web¶
Como tercer proyecto vamos a crear un chatbot que informe a los usuarios sobre contenidos publicados en una web. Lo que haremos será adaptar un chatbot general, como ChatGPT o similar, y entrenarlo con las URLs y documentos de la web en cuestión, para que aprenda a resolver preguntas de la misma.
El trabajo de estos chatbots entra dentro de un área conocida como RAG (Retrieval-Augmented Generation, generación aumentada por recuperación). Con esto conseguimos que un LLM entrenado con textos comunes de conocimiento general se centre más en un contenido o ámbito específico que nosotros le proporcionamos y al que él normalmente no puede acceder directamente (documentos PDF, bases de datos...), y se evita de esta forma que las respuestas sean poco precisas e incluso erróneas.
3.1. Opciones de desarrollo¶
Para llevar a cabo nuestro cometido tenemos distintas opciones, que podrían resumirse en dos grandes grupos:
- Utilizar una plataforma existente que permite preparar un chatbot sin código, facilitando las URLs o documentos de la web sobre la que trabajar. Existen distintas plataformas para ello, como Chatbase, CustomGPT.ai o Botpress. La mayoría ofrece planes de pago para utilizarlo, salvo algunas como Botpress que ofrecen algún plan gratuito para uso limitado.
- Desarrollar el chatbot con código, combinando un modelo como GPT-4 con RAG (Retrieval Augmented Generation), una tecnología que permite adaptar un modelo existente a otros contenidos específicos. No se re-entrena el modelo, sino que hacemos que consulte esos documentos para formular respuestas. Esta segunda opción implica scrapear los contenidos, vectorizarlos y pasarlos al modelo para que los asocie a los prompts de entrada.
3.2. Planteando el ejemplo¶
Para simplificar el proceso aquí emplearemos Botpress para crear nuestro ejemplo. Lo primero que tenemos que hacer es registrarnos en su web. Nos hará algunas preguntas sobre el propósito del chatbot, y entraremos en el workspace para crearlo:
Si creamos un nuevo bot, le podemos poner un nombre y desarrollarlo en el Studio:
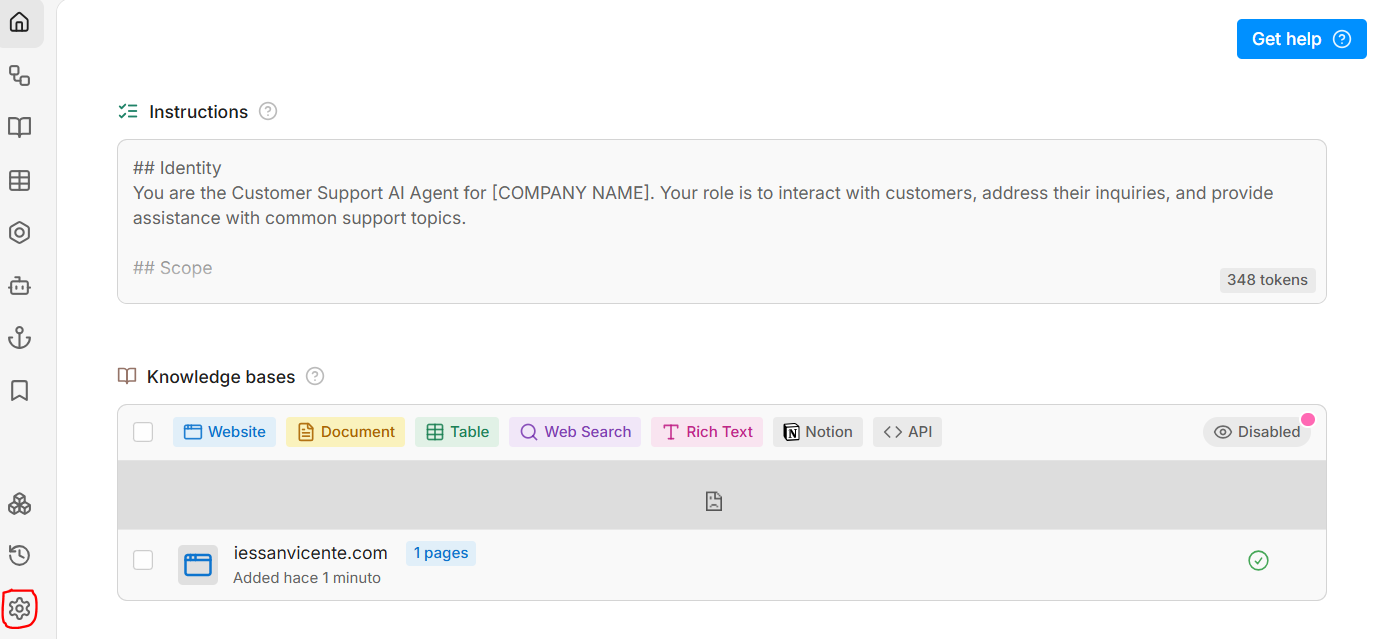
En la parte izquierda, con el icono de Settings (marcado en rojo en la imagen anterior) podemos cambiar algunas opciones, como el LLM utilizado por defecto para las respuestas. En la parte central superior tenemos las instrucciones (Instructions) que le damos al bot para que formule sus respuestas, y debajo podemos proporcionar la información que necesita para trabajar, como por ejemplo la(s) web(s) donde buscar (Website), o documentos PDF adicionales que queramos proporcionar (Document).
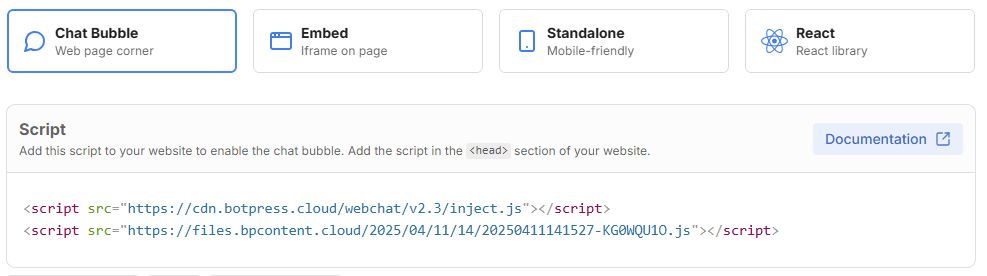
Una vez hemos proporcionado todas las páginas y documentos para entrenar a nuestro chatbot, podemos publicarlo yendo a la parte superior derecha de Botpress Studio y eligiendo Publish. Después, desde el botón de Share en esa parte superior izquierda podemos ver qué código podemos embeber en nuestras páginas para conectar con el chatbot, en la sección Chat Bubble.
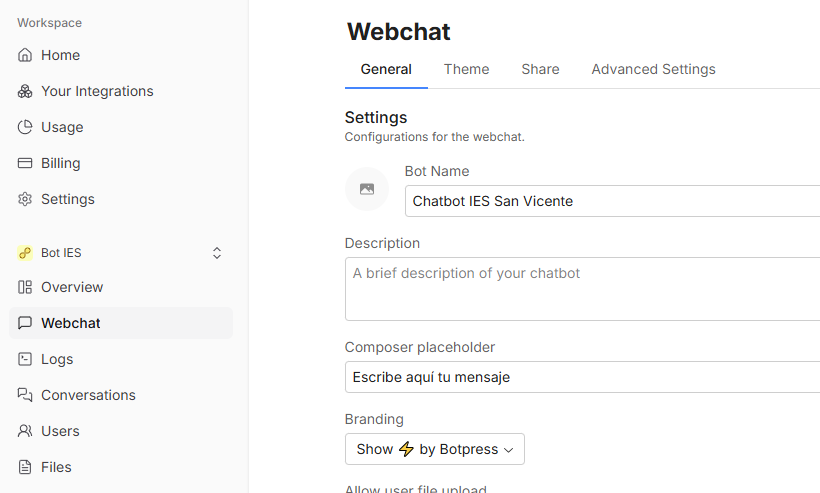
Finalmente, desde el workspace del chatbot podemos cambiar algunas opciones de configuración en el menú izquierdo WebChat. Por ejemplo, personalizar los mensajes que aparecen en el chat, al idioma que nos interese:
Ejercicio 6
Crea ahora tú un chatbot sobre la web o los documentos que quieras, y construye una pequeña página de prueba que le haga consultas.