Conceptos básicos de inteligencia artificial¶
Vivimos en un mundo donde estamos en contacto, sin ser conscientes y día a día, con sistemas basados en inteligencia artificial. Cada vez que buscamos algo en Internet, o hacemos que nuestro móvil nos reconozca la cara para darnos acceso, por ejemplo, estamos empleando estos mecanismos. Antes de comenzar a entrar en materia, en este documento vamos a presentar algunos conceptos básicos relacionados con el campo de la inteligencia artificial, para empezar a familiarizarnos con ellos, y entender cómo se desarrollan estos procesos.
1. ¿Qué es la Inteligencia Artificial?¶
Comencemos por definir de manera formal el término que da nombre a todo este curso. ¿Qué es la inteligencia artificial? Si buscamos en Internet podemos encontrar varias definiciones relacionadas, como por ejemplo:
- Programa de computación diseñado para realizar determinadas operaciones que se consideran propias de la inteligencia humana
- Combinación de algoritmos planteados con el propósito de crear máquinas que presenten las mismas capacidades que el ser humano
- Habilidad de una máquina de presentar las mismas capacidades que los seres humanos, como el razonamiento, el aprendizaje, la creatividad y la capacidad de planear
De todas estas definiciones, y otras más que podemos encontrar, extraemos un denominador común: la inteligencia artificial tiene que ver con el hecho de hacer que las máquinas se comporten de forma similar a los humanos, en cuanto a capacidad de razonamiento, aprendizaje, estrategia, etc. Podríamos definir entonces la inteligencia artificial como la capacidad de un componente artificial de realizar tareas propias de la inteligencia humana. Dentro del concepto componente artificial entrarían diversos elementos, tales como ordenadores, dispositivos domóticos, robots, etc.
¿Qué cosas son propias de la inteligencia humana? Podemos partir de cosas algo elementales, como la capacidad de realizar cálculos y la capacidad de memorizar datos, para luego pasar a otras algo más sofisticadas, como la capacidad de reconocer algún tipo de objeto o persona con la vista, la creatividad para realizar una obra de arte, o la capacidad de predecir o intuir qué va a suceder a continuación en un momento determinado. Todo esto tiene que ver con la inteligencia humana y, en cierto modo, se puede modelar para ser implantado en un componente artificial.
En la gran mayoría de ocasiones esto se va a conseguir a través de distintos programas que, por sí mismos o combinados con otros, van a permitir que una máquina aprenda a realizar una tarea, o "razone" y emita unos resultados a partir de unos datos que le son proporcionados, entre otras cosas.
1.1. Fundamentos de los sistemas inteligentes¶
Los sistemas inteligentes son programas o dispositivos capaces de percibir información del entorno, procesarla y tomar decisiones con un grado de autonomía para alcanzar objetivos específicos. Su desarrollo se basa en la combinación de conocimientos de informática, matemáticas, estadística, lógica y ciencias cognitivas. Su finalidad es dotar a las máquinas de comportamientos que normalmente asociamos a la inteligencia humana, como el aprendizaje, la planificación, el razonamiento y la resolución de problemas.
Los sistemas inteligentes se apoyan en tres pilares principales:
- Representación del conocimiento: un sistema inteligente debe contar con un modelo interno del mundo, es decir, una forma de representar la información relevante para su funcionamiento. Esta representación puede consistir en reglas lógicas, bases de datos, modelos probabilísticos, redes semánticas o estructuras matemáticas. El tipo de representación determina la forma en que el sistema interpreta la realidad y delimita lo que puede y no puede resolver.
- Mecanismos de razonamiento: una vez que la información ha sido representada, el sistema debe ser capaz de utilizarla para inferir conclusiones, hacer predicciones o tomar decisiones. Los mecanismos de razonamiento pueden basarse en reglas lógicas, cálculos de probabilidad, optimización, heurísticas o modelos estadísticos. La eficacia del sistema depende en gran medida de la solidez de estos mecanismos y de su capacidad para manejar incertidumbre y situaciones no previstas.
- Aprendizaje y adaptación: los sistemas más avanzados no solo aplican conocimientos predefinidos, sino que aprenden a partir de los datos o de la experiencia. El aprendizaje automático (machine learning) permite ajustar modelos internos con el tiempo para mejorar el desempeño. En algunos casos, se recurre al aprendizaje profundo (deep learning), que emplea redes neuronales profundas para detectar patrones complejos y abstraer conceptos de forma autónoma.
Además de estos elementos, los sistemas inteligentes suelen incluir componentes de percepción, encargados de captar datos del entorno a través de sensores o fuentes digitales, y componentes de actuación, capaces de ejecutar acciones para alcanzar un objetivo. Un sistema inteligente es considerado eficaz cuando integra todos estos procesos en un ciclo de retroalimentación continuo: percibe, interpreta, decide, actúa y evalúa los resultados para mejorar en iteraciones futuras.
Los fundamentos de los sistemas inteligentes no solo ofrecen una base teórica para su diseño, sino que también explican su creciente impacto en la sociedad. Desde asistentes virtuales hasta vehículos autónomos y sistemas de diagnóstico médico, estas tecnologías están transformando múltiples sectores, impulsadas por la computación de alto rendimiento y la disponibilidad masiva de datos. Comprender estos fundamentos es esencial para desarrollar soluciones innovadoras y responsables en un mundo cada vez más automatizado.
1.2. Inteligencia artificial fuerte vs débil¶
Entre las clasificaciones de inteligencia artificial que podemos encontrar, una de las más habituales es la que distingue entre inteligencia artificial fuerte y débil.
- Un sistema de inteligencia artificial fuerte es aquel capaz de reproducir todas las capacidades humanas, sin centrarse en una única tarea. También se le conoce como AGI (inteligencia artificial general). Son sistemas capaces de aprender conceptos o técnicas nuevas por sí mismos, y por iniciativa propia. En la actualidad no existe (aún) ningun sistema real de IA fuerte, pero podemos encontrar algunos ejemplos ilustrativos de lo que supone en algunas películas o series de ciencia ficción. Por ejemplo, el asistente Jarvis de IronMan, o el robot Sony de la película Yo robot. Actualmente, este futuro se ve más cercano gracias a herramientas muy versátiles, como ChatGPT.
- En cambio, un sistema de inteligencia artificial débil o estrecha es aquel que se especializa en una tarea en concreto, y aprende y mejora sobre esa tarea, sin tener consciencia realmente de lo que hace. En este sector sí podemos encontrar varios ejemplos en la vida real: sistemas que aprenden a reconocer caras, o a jugar al juego de la serpiente, o a detectar tumores en radiografías u otras imágenes...
2. Inteligencia artificial y hardware¶
El hardware de los ordenadores personales ha sufrido una gran evolución en este último siglo. Se ha pasado de ordenadores con una capacidad de procesamiento limitada a sistemas escalables que multiplican dicha capacidad de procesamiento. Programas que antes podían tardar varias horas o días en acabar un simple renderizado 3D ahora lo pueden hacer en cuestión de minutos.
Esta evolución también afecta al desarrollo de aplicaciones de inteligencia artificial. Para aquellas que sean relativamente simples nos puede bastar con un ordenador y CPU (procesador) relativamente recientes. Sin embargo, a medida que la capacidad de procesamiento comienza a ser más exigente, como ocurre con las redes neuronales profundas, estos ordenadores pueden quedarse muy cortos, y necesitamos acudir a hardware más especializado. Comentaremos aquí dos términos que se utilizan con frecuencia en este ámbito:
- GPU (Graphics Processing Unit): tarjetas gráficas con una capacidad mayor de procesamiento. Inicialmente fueron concebidas para tareas relacionadas con renderización 3D y tareas similares, vinculadas a la computación matricial, pero esta misma capacidad las hace ideales para otras tareas de igual envergadura, como el entrenamiento de redes neuronales. Contar con una buena GPU (o varias) en nuestro sistema nos puede dar un plus de capacidad. En caso contrario, podemos acudir a sistemas en la nube como Google Colab, que nos ofrecen un uso (limitado) de GPU para nuestras tareas.
- TPU (Tensor Processing Unit, unidad de procesamiento tensorial): unidades específicas de aceleración de tareas relacionadas con la IA, desarrolladas por Google. También están disponibles en Google Colab, y ayudarán a acelerar ciertas tareas específicas relacionadas con el machine learning, como el entrenamiento de modelos o la inferencia. Están pensadas para procesamiento a gran escala y entrenamiento de modelos pesados o complejos.
- NPU (Neural Processing Unit, unidad de procesamiento neuronal), son unidades más pequeñas que las TPU, más pensadas para procesamiento de IA en dispositivos finales, como teléfonos u ordenadores de sobremesa o portátiles.
3. Inteligencia artificial y datos¶
El desarrollo de la inteligencia artificial está íntimamente ligado al desarrollo del procesamiento de la información. No se puede construir un sistema inteligente si no se le pasan los datos adecuados para que pueda aprender. El proceso por el que pasan estos datos es el siguiente:
- En primer lugar, hay que extraer los datos de la(s) fuente(s) correspondiente(s) y procesarlos para que tengan un formato adecuado. Esto convierte los datos en información.
- Esta información es la que se proporciona a los programas para que la almacenen de algún modo, para así poderla consultar cuando se requiera. Generamos así el conocimiento.
- A partir de este conocimiento, debemos hacer que nuestros programas sepan analizarlo e interpretarlo para poderlo comprender.
- Una vez comprendemos la información almacenada, pasamos a la última (y quizá más importante) etapa en este proceso: poder generar nuevo conocimiento a partir del que ya tenemos, mediante un proceso conocido como inferencia. Este último paso es el que determinará, generalmente, que el comportamiento de nuestro programa sea inteligente.
Veamos el siguiente esquema para entender mejor todas las piezas de las que estamos hablando:

En la parte izquierda tenemos todo lo relacionado con la ciencia de datos o data science.
- Una parte de ella es el big data, que contempla todo lo relacionado con el almacenamiento de grandes cantidades de datos. Por ejemplo, un hospital que almacene datos de sus pacientes. Ese almacenamiento en sí no aporta nada a la inteligencia artificial si no se hace algo con esos datos, por lo que el círculo de big data no conecta con el de IA.
- Otra parte del data science es el data mining que consiste en extraer algo de información valiosa de los datos almacenados (que, a su vez, pueden ser big data o datos más simples). Por ejemplo, ver qué porcentaje de los pacientes de un hospital son mayores de 65 años. Estos datos sí tienen una relación más directa con aplicaciones IA, ya que podemos hacer algo con esa información.
En la parte derecha tenemos todo lo relacionado con la IA. De entre las técnicas o ramas que abarca la IA, como vemos, el machine learning es hoy por hoy la más importante. La analizaremos con más detalle a continuación, pero comprende una serie de estrategias para que un programa aprenda a comportarse de forma inteligente. Dentro de esta rama hay un subtipo algo más específico de aprendizaje automático es el que se conoce como deep learning (aprendizaje profundo).
4. Ramas de la inteligencia artificial¶
Podemos dividir los estudios o aplicaciones basadas en inteligencia artificial en diferentes ramas. Algunas de las más populares son:
- Aprendizaje automático (Machine learning): es, quizá, la rama más importante y extensa de la inteligencia artificial hoy por hoy. Dedicaremos un subapartado a continuación para explicar algo mejor en qué consiste, y algunas subramas interesantes.
- Procesamiento del lenguaje natural (NLP, Natural Language Processing): son un conjunto de técnicas que se centran en saber interpretar el lenguaje humano para dar respuestas. En esta rama están basados los asistentes personales que podemos encontrar hoy en día, como Alexa o Google Assistant. La capacidad para entender lo que decimos, incluso lo que queremos decir y no hemos dicho, es cada vez mayor.
- Sistemas basados en búsqueda: estas técnicas de búsqueda se utilizan de forma exhaustiva en ciertos aspectos de la inteligencia artificial, como por ejemplo la búsqueda del mejor resultado para un problema dado (planificación, logística), o el análisis de opciones en juegos de estrategia como el ajedrez.
- Sistemas lógicos: son sistemas basados en una serie de reglas o normas conocidas con antelación y que, aplicadas, ayudan a encontrar la posible solución a un determinado problema.
- Sistemas expertos: sistemas que acumulan una gran base de conocimientos sobre un tema en concreto (medicina, economía...) y, ante una pregunta o petición de información, acuden a los datos almacenados para dar una respuesta. Por ejemplo, a partir de los síntomas que describe un paciente, indicar posibles enfermedades que puede tener.
- ...
Existen otros tipos de clasificaciones que podemos encontrar en Internet, y también subcategorías dentro de cada una de estas ramas. Veremos algunas de ellas a lo largo de estos apuntes.
4.1. Aprendizaje automático¶
Una de las principales ramas de desarrollo en la inteligencia artificial (quizá la más importante, ya que muchas veces se tiende a decir que son lo mismo) es la capacidad que tiene un sistema de aprender. El aprendizaje realizado por las máquinas suele denominarse aprendizaje automático, o machine learning, y podríamos definirlo como la capacidad que tiene un programa o algoritmo de modificar su propio comportamiento en base a ciertos datos que ha ido acumulando, o de cierta retroalimentación externa que le indica lo bien o mal que está resolviendo sus tareas.
Para empezar, la concepción del aprendizaje automático es diferente a la de la programación tradicional. Cuando elaboramos un programa convencional le proporcionamos unos datos de entrada y unas reglas que deben cumplirse (generalmente, a base de condiciones, bucles, secuencias de instrucciones) para obtener un resultado. En cambio, al desarrollar un sistema de aprendizaje automático, lo que debemos proporcionarle son los datos de entrada y los resultados que se han obtenido, para que él solo deduzca las reglas que le van a permitir obtener nuevos resultados con nuevos datos de entrada.
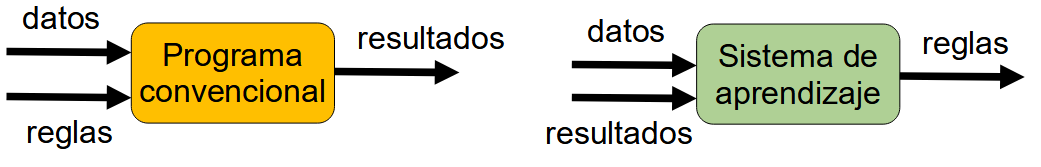
4.1.1. Tipos de aprendizaje automático¶
Cuando proporcionamos a un algoritmo de aprendizaje información sobre lo bien o mal que está resolviendo la tarea, o le "ayudamos" en cierto modo a saber cuándo ha hecho el trabajo correctamente, se dice que estamos aplicando un mecanismo de aprendizaje supervisado, y son los mecanismos más habituales de aprendizaje que podemos encontrar hoy en día.
En el otro lado están los mecanismos de aprendizaje no supervisado, que normalmente sirven para clasificar información. Por ejemplo, algoritmos que predicen los gustos de un usuario en base a la música que ha escuchado, las webs que ha visitado, etc. ofreciéndole otras alternativas similares a lo que ya ha hecho.
A medio camino entre estos dos extremos estaría el aprendizaje semi-supervisado, que se basa en mezclar ambas estrategias. Se puede aplicar una estrategia supervisada al principio, cuando disponemos de pocos datos y necesitamos "construir" más conocimiento, para luego pasar a un comportamiento más autónomo y no supervisado. Y también a la inversa: partir de un comportamiento no supervisado para catalogar un conjunto de datos y, una vez catalogado, aplicar aprendizaje supervisado para aprender a detectar nuevos datos de cada categoría. Por ejemplo, dado un conjunto de fotos, que el sistema las agrupe en categorías, y luego nosotros etiquetar cada categoría.
En otra línea diferente de trabajo nos encontramos también con el aprendizaje por refuerzo, muy aplicado en juegos, y en el que el algoritmo aprende a base de estrategias de prueba y error, en función del resultado final que obtiene al ejecutar el proceso, asimila los movimientos que ha hecho, o las decisiones que ha tomado y que le han llevado allí, para profundizar en las que le hacen mejorar y descartar las que no. Aquí existen distintos ámbitos de aplicación, como por ejemplo los algoritmos genéticos.
4.1.2. Aprendizaje profundo¶
El aprendizaje profundo, o deep learning, es una subrama dentro del aprendizaje automático que aplica un análisis más profundo a los datos de entrada para producir un resultado. Comprenderemos mejor este concepto con dos ejemplos:
Imaginemos un sistema de autodiagnóstico de enfermedades de pacientes. En una fase previa de tratamiento de datos, aislamos los datos relevantes de miles de pacientes: edad, peso, presión sanguínea, etc. Con esos datos, también facilitamos al sistema el diagnóstico final que recibió el paciente: resfriado, meningitis, etc. Entrenamos al sistema con todos esos datos para que, cuando llegue otro paciente, aislemos de nuevo los datos relevantes (edad, peso, etc), se los pasemos al sistema y nos indique qué posibles diagnósticos cuadran con esos datos de entrada. Lo que hemos construido es un modelo de machine learning, mediante aprendizaje supervisado. Pero... ¿y si al programa sólo tuviéramos que facilitarle un PDF con el historial del paciente, y el propio modelo supiera extraer los parámetros clave para emitir un diagnóstico? En este caso, nos ahorraríamos la fase previa de identificación de parámetros relevantes, ya que el propio sistema se encargaría de eso. Haría un análisis más profundo de los datos de entrada; se trata de un modelo de deep learning.
Veamos otro ejemplo: queremos identificar entre distintas variedades de tomate. Cada uno tiene un color, tamaño, forma, textura diferente. Construimos una tabla con muchas filas, y en cada fila anotamos el ancho, alto, colores, forma, textura de diferentes tomates, junto con la categoría final a la que pertenece cada muestra (tomate canario, tomate pera, etc). De nuevo, es un modelo de machine learning donde, en base a ciertos datos de entrada se cataloga el tomate en una categoría. Pero... ¿y si bastara con proporcionar al sistema una foto de un tomate para que lo pudiera catalogar? En este caso, el sistema sería capaz de extraer las características relevantes de la imagen del tomate: forma, tamaño... incluso algunas cosas particulares que a nosotros se nos hayan pasado por alto en nuestra tabla. Este segundo modelo hace un análisis profundo de la imagen para catalogarla, y sería un modelo de deep learning.
4.1.3. IA vs ML vs DL¶
Llegados a este punto, deberíamos saber la diferencia entre estos tres conceptos interrelacionados: inteligencia artificial, machine learning y deep learning.
Como hemos dicho al principio, cualquier comportamiento de un componente artificial que simule la inteligencia humana podemos considerarlo inteligencia artificial. Sin embargo, para que, además, sea machine learning o aprendizaje automático, debe darse un proceso de aprendizaje interno del sistema, sin que el programador o humano le diga cómo debe resolver el problema. Así, un sistema que nos diga qué tiempo hace hoy es inteligente, pero no forma parte del machine learning. En cambio, un sistema al que le introduzcamos datos de un vehículo de segunda mano y nos diga cuál es su precio orientativo de venta sí puede ser machine learning, si ha aprendido por sí mismo a calcular ese precio de venta, en base a datos previos de venta de otros coches que le han ayudado a ajustar esos parámetros de cálculo.
Si, además, ese sistema de venta de vehículos funciona pasándole unas fotos del mismo y su tarjeta de inspección técnica, sacando a partir de ahí su precio, entonces estaríamos ante un sistema de aprendizaje profundo o deep learning, donde la mayor parte del trabajo de extracción de características relevantes recae en el propio sistema, más que en el humano.
4.2. Otras técnicas de inteligencia artificial¶
Además del machine learning que, como decíamos, es la rama o técnica de la inteligencia artificial más extendida hoy en día, existen otras ramas que tienen su particular ámbito de aplicación.
4.2.1. Procesamiento del lenguaje natural¶
El procesamiento del lenguaje natural (NLP, Natural Language Processing) es una rama que abarca diferentes tareas: comprender el significado de un texto, clasificar un texto en una categoría, interactuar en una conversación, traducir un texto de un idioma a otro... Todo esto queda englobado en lo que se conoce como procesamiento del lenguaje natural (NLP). Una parte importante de esta rama está en contacto con el machine y deep learning que hemos visto antes.
Por ejemplo, podemos desarrollar un sistema que catalogue las opiniones o reseñas de distintos usuarios sobre un establecimiento en buenas, malas o neutrales. Para ello el sistema tiene que aprender a identificar componentes en una reseña que la etiqueten como "buena" o "mala", y necesitaremos normalmente entrenar al sistema con muchos datos de entrada previos, etiquetados como "buenos", "malos" o "neutrales" para que, dada una nueva reseña, el sistema pueda inferir su clasificación.
También en sistemas de traducción ha habido un entrenamiento previo: los traductores aprenden a traducir a base de analizar miles y miles de textos traducidos entre varios idiomas para que, junto a ciertas normas sintácticas, puedan emitir nuevos textos traducidos de un idioma origen. Ocurre lo mismo a la hora de mantener una conversación con un asistente virtual: éste aprende a escribir mensajes fijándose en miles y miles de textos escritos por diferentes personas en Internet.
4.2.2. Sistemas de búsqueda¶
Los sistemas de búsqueda tratan de encontrar una solución a un problema explorando todos los posibles caminos hacia la misma. Podemos aplicarlos en diferentes ámbitos: juegos de mesa, sistemas de organización industrial, optimización de recorridos, etc.
Por ejemplo, un sistema de búsqueda puede aplicarse al juego del ajedrez, para, dada una situación del tablero, examinar todos los posibles futuros movimientos (o un rango de los mismos) y emitir cuál será la mejor jugada posible. En el ámbito de la organización industrial, podemos aplicar esos sistemas a robots para que puedan distribuir o buscar componentes en los pasillos de un almacén, minimizando el camino recorrido, o evitando chocar con otros robots que estén trabajando allí.
4.2.3. Sistemas expertos¶
Los sistemas expertos, como hemos comentado anteriormente, almacenan una gran cantidad de información sobre un ámbito concreto, y la aplican en la resolución de determinados problemas. Podemos, por ejemplo, almacenar gran cantidad de síntomas patológicos junto con posibles enfermedades derivadas para, dado un paciente con una sintomatología, poder ofrecerle un abanico de posibles enfermedades que pueda padecer, y que el equipo médico pueda orientar más fácilmente su diagnóstico.
También en sistemas de inversión, el sistema experto puede recopilar mucha información sobre el mercado: valores de acciones, decisiones gubernamentales, políticas de empresas... para que, en un momento determinado, y consultado sobre una empresa en concreto, sea capaz de determinar si conviene o no invertir en esa empresa.
4.2.4. Otros sistemas¶
Como hemos comentado, además de las ramas citadas en apartados anteriores, el campo de la inteligencia artificial abarca otras ramas, como por ejemplo:
- Sistemas basados en reglas o restricciones a satisfacer para obtener la solución a un problema. Por ejemplo, cómo agrupar a un conjunto de personas sin que ciertas personas coincidan con otras.
- Sistemas de lógica difusa, en los que se trabaja con datos inciertos, para emitir conclusiones aproximadas; por ejemplo, decir que un vehículo va muy rápido (sin especificar velocidad), o que un motor está muy caliente, sin precisar la temperatura.
- ...
5. Algunos ejemplos introductorios¶
Para ilustrar algunas de las cosas que la inteligencia artificial puede resolver, y las etapas y problemas que debemos considerar, vamos a analizar algunos ejemplos prácticos a continuación: presentaremos en qué consisten, y algunas de las etapas importantes que hay que tener en cuenta en el desarrollo de los distintos modelos.
5.1. Presentando los ejemplos¶
Para tener variedad, vamos a presentar varios ejemplos diferentes de proyectos basados en IA.
- Una empresa de vehículos de segunda mano quiere desarrollar un sistema que le oriente sobre el precio que debería tener un vehículo para ponerlo a la venta.
- Una entidad bancaria necesita determinar si las solicitudes de préstamo que realizan sus clientes son viables o no
- Una tienda online quiere clasificar a sus clientes en diferentes categorías, pero no tiene muy claro cómo hacerlo
- Una empresa quiere desarrollar un sistema de conducción autónoma de vehículos. Para ello, equipará a sus vehículos con una serie de cámaras que tomarán secuencias del entorno que rodea al vehículo, de forma que éste pueda determinar qué acción realizar en cada momento.
5.2. Recopilación de datos¶
Una de las tareas más tediosas y que más tiempo consumen en un proyecto de inteligencia artificial es la recopilación de datos para entrenar y preparar el modelo que estamos desarrollando. Hay que tener en cuenta que estos datos pueden venir de fuentes muy heterogéneas: bases de datos relacionales, no relacionales, páginas web, ficheros de log... Es tarea de los analistas de datos acceder a esta información, recopilarla, centralizarla y, si es el caso, tratarla y adaptarla a lo que el programa espera recibir.
- Por ejemplo, en el caso de la empresa de vehículos de segunda mano, sería necesario recopilar todo el material posible sobre ventas pasadas: marca, modelo, kilometraje, año de fabricación, estado general, etc... y también el precio al que se vendió el vehículo. En este caso es posible que la información de que se disponga sea más o menos homogénea, y esté almacenada en algún tipo de base de datos u hoja de cálculo.
- En el caso de la entidad bancaria, también habrá que recopilar datos de procesos pasados con clientes: edad del cliente, salario anual, otras cargas que pudiera tener, cantidad solicitada, plazo solicitado para devolverla... y también el resultado final del proceso (es decir, si se le concedió o no el préstamo). Nuevamente, tratándose de una entidad bancaria, es posible que la información también sea homogénea, y esté almacenada en alguna base de datos.
- Para la tienda online que quiere clasificar a sus clientes, también deberemos decidir qué datos de los clientes son relevantes; ya que no tenemos claro cómo queremos clasificarlos, aquí el abanico de datos puede ser más diverso: edad del cliente, localidad, número de transacciones realizadas en los últimos X meses, volumen de compra media por transacción, número de accesos a la web, o frecuencia de acceso, etc. En este caso la información a recopilar puede venir de diferentes fuentes: por un lado, la base de datos donde almacenemos la información personal de los clientes pero, para acceder a datos como la frecuencia de accesos, puede ser necesario consultar también ficheros de log en formato texto y detectar en ellos los accesos del cliente en cuestión. Puede resultar interesante centralizar después toda esa información en alguna parte: base de datos, hoja de cálculo o similar, para poder acceder a ella de forma sencilla desde un programa
- Finalmente, para el ejemplo del sistema de conducción autónoma, harán falta multitud de secuencias de imágenes y/o vídeos con los que alimentar al sistema y determinar qué acción es la más recomendable (girar izquierda/derecha, frenar, acelerar...). Estas imágenes de entrada pueden venir de diferentes tipos de dispositivos (cámaras fotográficas, móviles, cámaras integradas en vehículos), y necesitarán pasar por un proceso de "normalización" para homogeneizarlas en cuanto a formato y tamaño.
5.3. Limpieza de datos (data cleaning)¶
Se conoce como limpieza de datos (en inglés, data cleaning) al pre-procesado de los datos de entrada a un sistema de IA con diferentes fines:
- Detectar valores faltantes (missing values) y determinar qué hacer con ellos: borrar el registro afectado, "inventarse" un valor acorde al resto de registros... Por ejemplo, si en la empresa de venta de vehículos falta el año de fabricación de algunos coches, podemos intuir cuál puede ser en función del kilometraje y modelo del motor, y aproximar esa cifra.
- Detectar anomalías (outliers), valores que difieran significativamente del resto de valores del conjunto de datos a tratar. Nuevamente, tendremos que determinar qué hacer con esos valores: descartarlos para el proceso o reemplazarlos por valores más acordes. Por ejemplo, en el caso de la entidad bancaria, si los salarios anuales de los clientes que consultamos están entre 20.000 y 60.000 euros y de repente encontramos un registro con un salario anual de 500.000 euros, podemos pensar que es un error, y elegir si descartar ese cliente para el estudio, o reemplazar ese valor aparentemente erróneo por uno más acorde, como la media o la mediana de salarios estudiados.
- Determinar los campos relevantes para el estudio (feature selection). Por ejemplo, en el caso de la tienda online, es posible que el correo electrónico de los clientes no sea relevante para clasificarlos en diferentes grupos o categorías
- Generar nuevas características a partir de otras dadas (feature engineering). En el caso de los vehículos de segunda mano, por ejemplo, si el estado general del vehículo lo etiquetamos como Bueno/Regular/Malo, a un sistema que suele trabajar con valores numéricos le va a aportar poco. Como veremos, los sistemas basados en IA suelen trabajar con datos de entrada numéricos y, en este caso, convendría re-codificar esa información a, por ejemplo, un rango del 0 al 2 (0 = Malo, 1 = Regular y 2 = Bueno).
- ... etc.
5.4. Determinar el tipo de sistema a desarrollar¶
Cada proyecto de inteligencia artificial requiere escoger adecuadamente el tipo de sistema que vamos a desarrollar. Existen diferentes opciones en este sentido:
- El sistema para predecir el valor de venta de un vehículo usado es un sistema de regresión en el que tratamos de encontrar una relación entre los parámetros de entrada (marca, modelo, año de fabricación, kilometraje, estado general) para generar un valor de salida (precio de venta), de forma que esa relación se asemeje a las de otros vehículos que ya se han vendido o están en venta. Pertenece a la rama de aprendizaje supervisado, dentro del machine learning: proporcionamos al sistema una serie de ventas de coches para que aprenda a establecer la relación entre los parámetros de entrada.
- El sistema para determinar si conceder o no un préstamo bancario a un cliente es un sistema de clasificación, donde se clasifica la entrada (en este caso, el cliente) en una serie de categorías de salida. En nuestro ejemplo concreto se trata de un sistema de clasificación binaria, ya que sólo hay dos posibles categorías de salida: SI se le concede el préstamo o NO se le concede. Nuevamente, pertenece a la rama de aprendizaje supervisado del machine learning: alimentamos al sistema con datos de préstamos (concedidos y denegados) a clientes previos para que el sistema aprenda a determinar la relación entre los parámetros del cliente y emitir un veredicto acorde a los anteriores.
- El sistema para clasificar a los clientes de la tienda online en grupos es un sistema de categorización (clustering). Pertenece a la rama de aprendizaje no supervisado del machine learning. En este caso sólo proporcionamos los datos de entrada al sistema, pero no la "solución" a cada caso. En los casos anteriores le indicábamos cuál debía ser el precio de venta, o el resultado final de concesión del préstamo, pero aquí no le decimos a qué categoría debe pertenecer el cliente. Será el sistem el que, analizando las características de todos los clientes, encuentre un patrón determinado que les permita agruparlos en diferentes clusters.
- El sistema de conducción autónoma pertenece al campo de la visión artificial. Dentro de este campo existen diferentes categorías, como la detección de objetos y la segmentación de imágenes, para detectar qué objetos hay en ellas y dónde están. Estas técnicas se aplicarían en este caso para, por ejemplo, detectar si en las imágenes hay semáforos, de qué color están, si hay peatones cruzando la calle, si hay curvas a izquierda/derecha... y, en función de los objetos detectados, tomar una decisión.
- Existen otros muchos tipos de sistemas que no hemos cubierto en estos primeros ejemplos, y que también pertenecen al campo de la IA. En los que se engloben dentro del campo del machine learning será necesario recopilar una buena cantidad de datos de entrada para preparar o entrenar al sistema, limpiar y tratar los datos adecuadamente, y luego elegir el sistema que queramos desarrollar.
5.5. Riesgos y limitaciones¶
Hay que tener muy presente los riesgos que se corren y las limitaciones que se tienen cuando se desarrolla un sistema de inteligencia artificial. Pondremos a continuación algunos ejemplos:
- ¿Qué ocurriría si la empresa de venta de vehículos desarrolla su sistema con una base histórica de 50 coches vendidos? Puede que esa cantidad sea demasiado corta, y el sistema no sea capaz de establecer una conexión sólida entre los parámetros de entrada (marcas, modelos, kilometrajes, etc) y el precio de venta asociado.
- Imaginemos ahora que la entidad bancaria tiene un registro de 20.000 solicitudes de préstamo, donde la mayoría de las mujeres que lo han solicitado han sido amas de casa sin ingresos demostrables y que, por tanto, han visto denegada su solicitud. Ante un nuevo caso de entrada de una mujer que solicite un préstamo, aunque tenga solvencia económica, el sistema puede haber aprendido que a las mujeres no se les conceden préstamos habitualmente, y se lo deniegue. El conjunto de datos de entrada con que hemos entrenado al sistema tiene un sesgo que no le permite generar un resultado correcto en algunos casos.
- En el caso de la tienda online, ¿qué ocurriría si la mayoría de clientes tiene un patrón similar?: misma localidad, similares transacciones mensuales, etc. El sistema tendría muy difícil establecer categorías diferenciables entre estos clientes. El sistema de datos de entrada necesita tener la variedad suficiente para el propósito que se persigue.
- Finalmente, en el caso del sistema de conducción autónoma, ¿qué ocurriría si se toma una decisión equivocada ante unas imágenes de entrada? Esto puede repercutir en accidentes graves, incluso mortales. Existen ciertos sistemas, como éste de conducción autónoma y otros en el ámbito de la salud, o incluso las finanzas, donde la respuesta que se da debe ser segura, y debemos garantizar que así sea.
A lo largo de los siguientes documentos iremos profundizando en todos los conceptos que hemos visto en este apartado: veremos qué herramientas tenemos para analizar y tratar los datos de entrada a un problema, cómo podemos construir algunos de los diferentes sistemas basados en IA que existen y cómo podemos evaluarlos para intentar optimizar su rendimiento y funcionamiento al máximo.