Herramientas de modelado: KNIME¶
KNIME es una herramienta muy útil para el análisis de datos. Es gratuita y open-source (al menos la parte para analítica de datos), y nos va a permitir realizar análisis de cualquier nivel de complejidad sobre nuestros datos, facilitando así la tarea de importar datos y limpiarlos, además de algunos pasos en el ámbito del machine learning.
1. Introducción a KNIME¶
Para empezar, veremos cómo podemos descargar, instalar y ejecutar KNIME, y qué elementos debemos tener en cuenta en el entorno de trabajo.
1.1. Instalación y primeros pasos¶
Lo primero que tendremos que hacer será descargar la herramienta desde la sección de descargas de la web oficial. Elegiremos la versión que queramos descargar e instalar para nuestro sistema operativo. En el caso de Windows, podemos descargar una versión ZIP portable, y descomprimirla y ejecutarla en la carpeta que queramos. Al ejecutar nos pedirá que elijamos nuestra carpeta de trabajo o workspace, y después veremos la pantalla de inicio. Dependiendo de la versión de KNIME que estemos utilizando es posible que nos muestre la interfaz clásica...
... o la interfaz moderna:
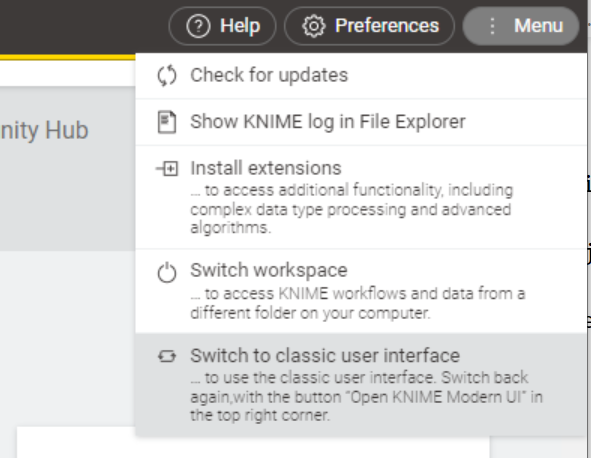
Desde ambas se puede cambiar a la otra desde la esquina superior derecha. En el caso de la interfaz moderna, en la sección Menu elegimos Switch to classic user interface.
En los siguientes apartados trabajaremos con la interfaz clásica, ya que, a nuestro modo de ver, integra de forma más sencilla los componentes a utilizar.
1.2. Componentes principales de la ventana de KNIME¶
Una vez abierto, el entorno y forma de trabajo es similar a IDEs como Eclipse. Distinguimos algunas zonas principales:
- En la esquina superior izquierda tenemos el explorador de KNIME (KNIME explorer). Hay un apartado llamado EXAMPLES que contiene ejemplos subidos por la comunidad al servidor o hub de KNIME, y que podemos consultar, y también una sección LOCAL con nuestro espacio de trabajo local.
- En la parte inferior izquierda tenemos el repositorio de nodos (Node repository), que son los componentes que podemos utilizar en nuestro proceso de análisis de datos. Para cada uno, podemos hacer clic y ver una descripción detallada en la parte superior derecha (Description). También tenemos un buscador incorporado en la sección del repositorio para buscar los nodos que nos interesen.
- La sección central es el workflow o área de trabajo, donde iremos colocando componentes del repositorio de nodos y conectándolos para resolver nuestra tarea.
- La sección superior derecha es la de descripción, aquí veremos una descripción detallada del elemento que hayamos seleccionado (bien del repositorio de nodos, o del área de trabajo).
- En la sección central izquierda tenemos el workflow coach, que estará disponible sólo si permitimos al programa enviar datos de uso. Aquí podemos ver un listado de los nodos más habituales, para que podamos acceder a ellos más rápidamente.
- Finalmente, en la sección inferior tenemos los paneles de outline (vista general del área de trabajo, para poder hacer zoom en alguna parte concreta) y de la consola, donde veremos el resultado del proceso cuando lo ejecutemos, por si hay algún error que debamos corregir.
Podemos arrastrar estos componentes a otras zonas de la ventana, o incluso ocultarlos. Siempre podemos restablecer la apariencia original desde el menú View > Reset perspective.
1.3. Un primer proyecto de prueba¶
Para trabajar con KNIME tenemos que crear proyectos, desde el menú File > New. Elegiremos un nuevo Workflow de KNIME, y le pondremos un nombre. Por defecto se guardará en una carpeta en el workspace que elegimos al iniciar KNIME (por ejemplo, carpeta knime-workspace en nuestra carpeta de usuario).
También podemos crear Workflow Groups, que básicamente son una especie de carpetas para agrupar proyectos relacionados entre sí. Alternativamente, también podemos crear proyectos o grupos haciendo clic derecho en la sección LOCAL del explorador de KNIME, en el panel superior izquierdo.
KNIME es un programa basado en flujos. Deberemos definir el flujo que van a seguir los datos para hacer lo que necesitamos. En los siguientes subapartados veremos algunas de las cuestiones más importantes al respecto.
Crearemos ahora un proyecto llamado Prueba_Titanic en KNIME. Vamos a procesar los datos de este fichero CSV sobre pasajeros del Titanic. Para ello, desde el proyecto, vamos a la sección inferior izquierda (repositorio de nodos) y elegimos en la sección IO > Read el elemento CSV Reader y lo arrastramos al área de trabajo del proyecto.
Haciendo doble clic en el nodo podemos elegir el fichero CSV que queramos cargar. Ahora vamos a conectarlo con ciertos nodos de filtrado. Por ejemplo, vamos a quedarnos sólo con los supervivientes. En el repositorio de nodos, vamos a la sección de Manipulation > Row y elegimos Filter. Dentro, elegimos el nodo Rule-based Row Filter (filtro de fila basado en reglas) y lo arrastramos a la zona de trabajo.
Ahora vamos a unir el nodo anterior de lectura con este nuevo nodo. Arrastramos desde la flecha de salida del nodo de lectura hasta el nodo de filtro.
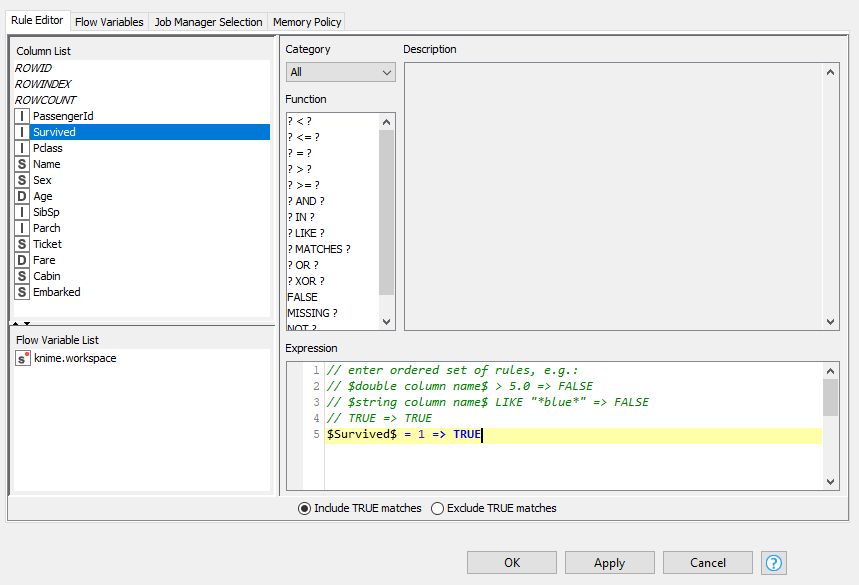
Hacemos a continuación doble clic en el nodo de filtro, y definimos el filtro. Es IMPORTANTE hacer esto después de unir el nodo con el de lectura, para que así este nodo ya reconozca los campos que hay en el CSV. Hacemos doble clic en el campo Survived del panel izquierdo y completamos la instrucción indicando que queremos las filas que tengan este campo a 1:
Ahora vamos a quedarnos con el nombre, sexo, edad y clase a la que pertenecen los supervivientes. Añadimos un filtro de columna, desde la sección Manipulation > Column > Filter del repositorio de nodos, eligiendo Column Filter. Conectamos este nodo con el anterior, hacemos doble clic en él y dejamos en la sección Include las columnas con las que queramos quedarnos.
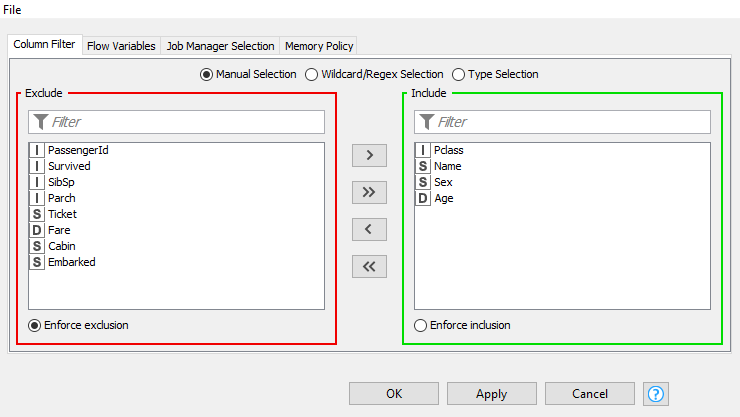
Finalmente, vamos a guardar el resultado en una hoja de cálculo Excel. Añadimos para ello un nuevo nodo de la categoría IO > Write. En este caso elegimos Excel Writer, pero notar que también podemos exportar a otros formatos, como por ejemplo generar otro CSV con los datos procesados (CSV Writer). Conectamos el nodo con el anterior, y hacemos doble clic para elegir el fichero de salida.
Ahora podemos poner en marcha el proceso desde el menú Node > Execute All o bien pulsando Shift + F7, o con el icono verde de la doble flecha de la barra de herramientas. Podremos comprobar que se genera el fichero de salida esperado con los datos que hemos filtrado.
Nota
Podemos ejecutar todo el workflow de golpe o ejecutar nodo a nodo (haciendo clic derecho en cada nodo y eligiendo Execute). Las luces bajo cada nodo nos indican su estado. En amarillo indican que no se ha ejecutado pero está listo para hacerlo, y en verde que ya se ha ejecutado y contiene resultados (que también podemos consultar con clic derecho, yendo a la última opción del menú contextual correspondiente).
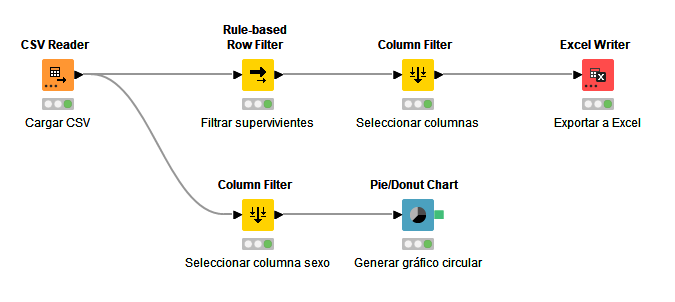
El proceso se puede diversificar todo lo que queramos. Por ejemplo, podemos añadir otra rama paralela que filtre sólo la columna de sexo, y con ello construya un gráfico circular de porcentajes por sexo (apartado Views > JavaScript, nodo Pie/Donut Chart). También podemos hacer doble clic en los nombres de los nodos (Node 1, Node 2... etc) y cambiarlo por otros más representativos.
2. Análisis de las principales opciones de KNIME¶
En esta sección haremos un análisis más detallado de los principales elementos o nodos que podemos emplear en nuestros desarrollos en KNIME. Desde elementos simples para lectura o escritura de datos a otros más avanzados para filtrado y transformación de datos.
2.1. Lectura y escritura de información¶
KNIME permite leer y escribir información en varios formatos, aunque los más habituales quizá sean Excel y CSV. Para ello, disponemos de nodos como:
- Excel Reader y CSV Reader para leer ficheros con esos formatos específicos. Además del fichero en cuestión, podemos especificar otros parámetros, dependiendo del nodo en sí. Por ejemplo, para el CSV Reader podemos indicar el carácter delimitador, o si la primera fila contiene las cabeceras de columna. Además, disponemos de un nodo genérico File Reader que permite actuar como "comodín", y leer cualquier tipo de fichero (incluidos CSV y Excel).
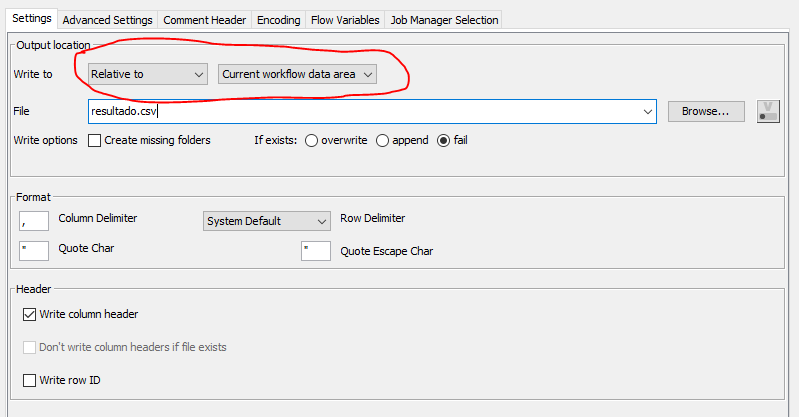
- Análogamente, disponemos de los nodos Excel Writer, CSV Writer o File Writer para los correspondientes procesos de escritura. Además de especificar el nombre del fichero destino, en algunos casos podremos indicar también si queremos guardar el identificador de fila en el fichero o no, y otras opciones. Notar que, tanto para leer como para guardar, podemos indicar una ruta absoluta del sistema de ficheros, o relativa, por ejemplo, al espacio de datos del proyecto (subcarpeta data dentro de la carpeta del proyecto).
2.2. Herramientas de filtrado¶
KNIME proporciona varios nodos que nos van a permitir filtrar la información de que disponemos, bien por filas, bien por columnas.
El nodo Row Filter nos va a permitir filtrar filas indicando un criterio general, como por ejemplo "todas aquellas cuya columna X sea mayor que cierto valor, o sea igual a cierto valor"). En este caso podemos elegir si queremos incluir o excluir las filas que cumplan el criterio indicado.
Por otra parte, el nodo Rule-based Row Filter, como hemos visto en el ejemplo introductorio, permite especificar una fórmula de filtrado algo más compleja, indicando las condiciones a cumplir.
En cuanto al filtrado de columnas, el nodo más habitual es Column Filter, donde indicamos qué columnas nos interesa mantener, y cuáles excluimos. Ya lo hemos utilizado en el ejemplo introductorio también:
2.3. Herramientas de limpieza y transformación de datos¶
Una vez hemos filtrado los datos que nos interesan (o, a veces, como paso previo a este filtrado), también es necesario hacer algunas tareas de limpieza: sustituir valores nulos, convertir tipos de datos entre columnas, etc. Veamos qué nodos de KNIME podemos emplear habitualmente en estos casos.
El nodo Missing Value se emplea para reemplazar valores faltantes en un conjunto de datos. En su configuración podemos elegir qué hacer con cada tipo de dato presente en la tabla. Por ejemplo, los valores alfanuméricos se pueden reemplazar por un texto fijo, o por el valor que haya en la fila anterior. Los valores numéricos (enteros o reales) se pueden reemplazar por valores representativos, como la media, el valor máximo, el mínimo...

Por suparte, el nodo Duplicate Rows permite eliminar filas duplicadas. Podemos especificar qué columnas queremos comparar para ver si las filas están duplicadas. Si especificamos todas las columnas (algo habitual), se considerará que dos filas están duplicadas si coinciden sus valores en todas las columnas.
El nodo String Replacer permite reemplazar texto en columnas alfanuméricas. Deberemos elegir la columna en cuestión, y las condiciones del reemplazo.
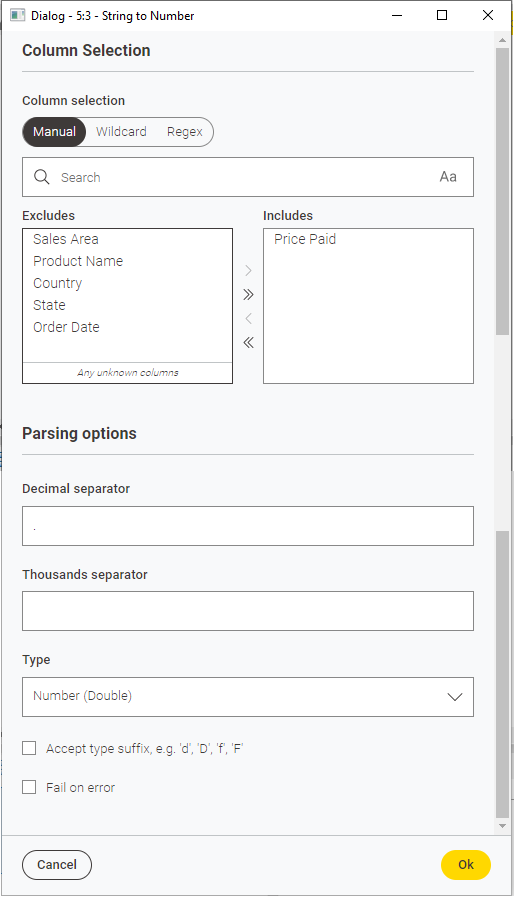
El nodo String To Number permite convertir datos de texto a numéricos (enteros o reales), eligiendo la(s) columnas a convertir en el listado inferior y el tipo al que convertir en las opciones superiores. De forma análoga, pero a la inversa, está el nodo Number To String.
Un nodo algo más avanzado es Value Lookup, que permite reemplazar ciertas ocurrencias de una columna por otros valores, dando los emparejamientos en un diccionario (tabla Excel). Veremos algún ejemplo de esto más adelante.
El nodo Joiner nos resultará muy útil cuando queramos unir datos de varias tablas. Añadiremos con ellos nuevas columnas, emparejando las filas por las columnas clave (aquellas que se repiten en las dos tablas). Veremos también un ejemplo de uso de este nodo más adelante.
El nodo Math Formula permite definir una fórmula que haga cálculos más o menos complejos con datos de otras columnas. Podremos elegir las columnas con las que operar del panel izquierdo, y construir la fórmula en el panel inferior.
2.4. Otros nodos útiles¶
Además de los nodos comentados en los apartados anteriores, mostramos aquí un breve resumen de algunos nodos más que pueden resultarnos útiles en un momento dado:
- Transfer Files: permite mover/copiar ficheros desde una ubicación a otra desde dentro de KNIME. Puede venir bien para compartir ficheros entre diferentes proyectos, o trasladar resultados a una carpeta externa gestionada por otro programa. Además, permite filtrar los archivos que nos interesan, incluir subcarpetas, etc.
- List Files/Folders: permite leer secuencialmente un conjunto de ficheros (admite también opciones de filtrado). Combinado con otros nodos como Table Row to Variable Loop Start y Loop End resulta muy útil, al generar un bucle que recorra cada fichero, para luego usar algún Reader de los vistos anteriormente para leerlos uno a uno, en bucle. Lo veremos en un ejemplo posterior.
- Column Merger es un nodo útil cuando combinamos tablas de datos de diferentes fuentes, y hay columnas que queremos unir en una sola. Podemos especificar los nombres de las dos columnas a unir, y el modo de unión (reemplazar primera columna, segunda, ambas, crear una columna aparte con la unión...)
- Normalizer nos permitirá normalizar el valor de las columnas (numéricas reales) que escojamos, indicando el rango de normalización
- Category To Number permite asignar una codificación numérica a valores categorizados. Podemos elegir el rango de valores numéricos a asignar (por ejemplo, de 0 al total de categorías encontradas).
- Statistics muestra unos datos estadísticos por columna: valor máximo, mínimo, número de nulos...
Ejercicio 1
Utiliza el dataset del Titanic en un workflow llamado Titanic_Analisis. Se pide hacer los siguientes pasos, enlazando cada uno con el siguiente.
- Cargar el fichero CSV con un CSV Reader, desde una ruta relativa al workflow, en su subcarpeta data.
- Convertir la columna Survived a string
- Convertir la columna Sex a entero (Category To Number), y sobreescribir la propia columna
- Eliminar columna Cabin, porque tiene demasiados nulos
- Reemplazar las edades nulas por la media de edad y los Embarked nulos por el valor más frecuente de esa columna (puedes hacerlo todo junto con un solo Missing Value, configurándolo desde la pestaña Column Settings)
- Guarda el resultado procesado con un CSV Writer en un fichero llamado titanic_procesado.csv, en la misma carpeta que el original
- Paralelamente, desde el penúltimo nodo, filtra los supervivientes, y quédate con la columna Pclass. Convierte este dato a string y saca un gráfico de barras de cuántos supervivientes hubo por clase.
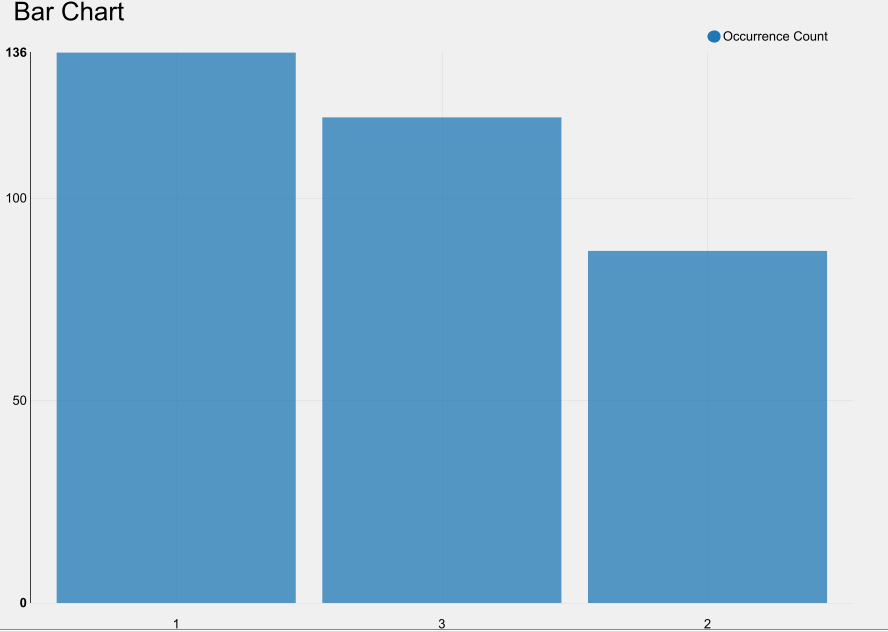
Solución Ejercicio 1
Aquí tienes un vídeo completo de todo lo explicado hasta este punto, incluyendo este último ejercicio.
3. Un ejemplo completo¶
Vamos ahora a construir un proyecto completo paso a paso desde el principio: recopilaremos datos de diferentes fuentes, los limpiaremos y combinaremos para producir un resultado final, todo desde KNIME. Comenzaremos descargando este archivo comprimido. En él veremos varios archivos:
- Product Info es un archivo Excel con información de los productos en venta de una compañía. En este caso son bebidas energéticas, y en este archivo se indican precios de venta y coste de fabricación en cada país donde se venden.
- Sales Rep es otro archivo Excel con información sobre las diferentes regiones de venta, junto con los productos que se venden en cada región y quién es el responsable o jefe de ventas de ese producto en esa región
- Hay algún archivo Excel más, cuya utilidad explicaremos más adelante.
- Finalmente, disponemos de un conjunto de archivos CSV con las ventas realizadas en diversos meses. Se indican en cada registro su ID, la región donde se vendió (cotejable con las que hay en Sales Rep), el nombre de producto que se vendió (también cotejable), país y estado, cantidad, fecha y precio que se pagó.
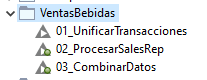
Crearemos para empezar un nuevo workflow group llamado VentasBebidas donde iremos añadiendo diferentes workflows para las tareas que haremos:
- 01_UnificarTransacciones: donde cargaremos todos los ficheros de transacciones y los unificaremos en uno solo
- 02_ProcesarSalesRep: donde cargaremos el fichero Sales Rep y haremos una pequeña limpieza de datos inicial
- 03_CombinarDatos: donde enlazaremos los datos de las tres partes (transacciones, ventas e información de productos), haciendo una limpieza y preparación de datos final
3.1. Unificar transacciones en un solo archivo¶
Como primer paso, vamos a recopilar la información de todos los archivos CSV con transacciones y a agruparlos en un único archivo para su mejor tratamiento. Lo haremos dentro del workflow 01_UnificarTransacciones.
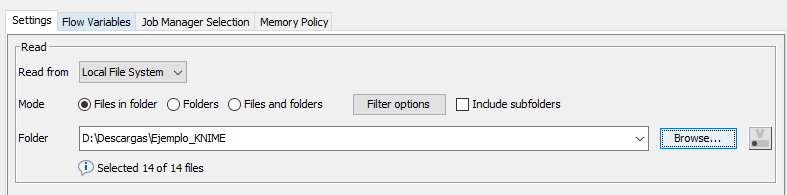
Usaremos un nodo del repositorio de nodos llamado List Files/Folders, dentro de la sección IO > File Folder Utility. Arrastramos el nodo, hacemos doble clic en él y especificamos la carpeta cuyos archivos queremos listar (aquella donde se encuentran descomprimidos los archivos del paquete anterior).
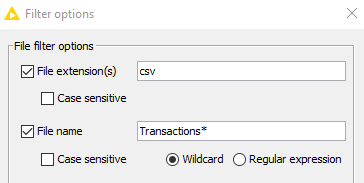
Además, en ese panel, debemos acudir a Filter options y especificar unas opciones de filtrado:
- Buscamos archivos con extensión csv
- Nos interesan sólo los archivos que empiezan por Transactions, que son los que contienen las transacciones mensuales.
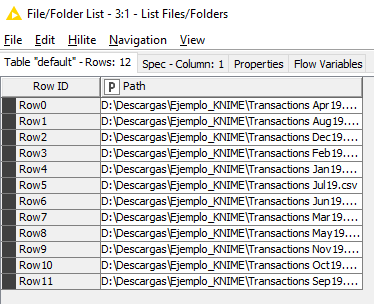
Podemos seleccionar el nodo actual y con clic derecho o F7 elegir Execute para lanzarlo. Luego hacemos clic derecho de nuevo sobre el nodo y vamos a la última opción (File/Folder list) para ver el resultado de ficheros seleccionados:
Ahora vamos a iterar sobre esos ficheros usando el nodo Table Row to Variable Loop Start
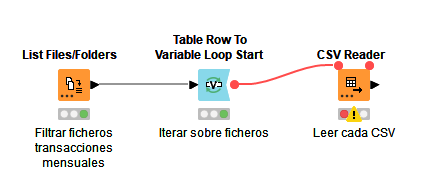
Lo arrastramos al área de trabajo y conectamos la salida anterior con la entrada del nuevo nodo. Después, ejecutamos (F7) el nuevo nodo seleccionándolo previamente. Si echamos un vistazo (clic derecho) a las propiedades de este nodo, veremos las variables que se crean para gestionar la lista de ficheros extraída. Nos interesará la propiedad Path, que usaremos ahora con un CSV Reader para ir leyendo cada archivo. Notar que este nodo no admite flecha de entrada (en teoría es un nodo de inicio), pero sí admite variables conectadas. Podemos mostrar los puntos de conexión de variables del CSV Reader haciendo clic derecho sobre el nodo y eligiendo Show Flow Variable Ports. Después, conectamos la salida de variable del nodo anterior (punto rojo) con este:
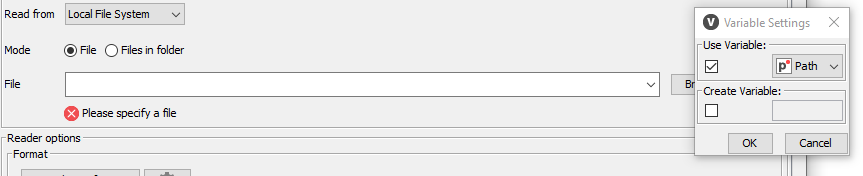
Para indicar qué archivo leer, hacemos doble clic en el nodo, y en el campo File hacemos clic en el icono del borde derecho, y elegimos la variable Path que nos proporciona el nodo anterior.
Para que lea todos los archivos filtrados, necesitamos conectar este último nodo a otro de fin de bucle (Loop End).
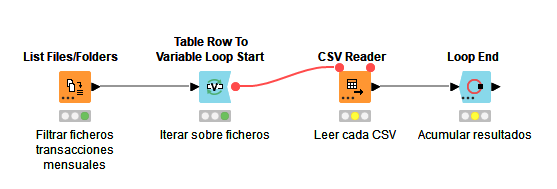
Como la estructura de los ficheros es la misma, KNIME simplemente va añadiendo nuevas filas a continuación de las que ya ha procesado. Podemos ver el resultado final global en la salida del último nodo (tras ejecutarlo). Veremos que se añade una columna Iteration indicando qué registros se han añadido en cada iteración.
Vamos ahora a guardar en un fichero CSV todas estas transacciones. Añadimos para ello un nodo CSV Writer conectado al Loop End del flujo de CSV. Podemos llamar al fichero de salida FinalTransactions.csv, y marcamos en la configuración del nodo que incluya las cabeceras de columna, y que sobreescriba (overwrite) el fichero si ya existía previamente. Ubicamos el fichero de salida en la misma carpeta que los de entrada.
3.2. Procesar fichero Sales Rep¶
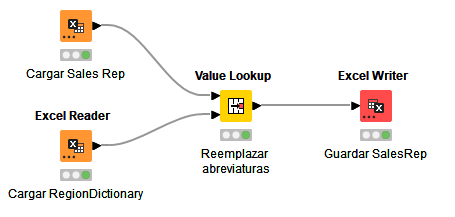
Vamos ahora a procesar el fichero de ventas Sales Rep, dentro del workflow 02_ProcesarSalesRep. En dicho fichero de ventas, los valores de la columna Sales Area deberían corresponderse con los de las columnas Sales Area de los ficheros de transacciones, para poder establecer relaciones entre registros, y no lo hacen, ya que en Sales Rep están abreviados. RC debería renombrarse a Region Central, y así sucesivamente con el resto.
Añadimos para ello un nodo Excel Reader en el proyecto, y le especificamos como fichero Sales Rep.xlsx. Además, marcamos la casilla indicando que la primera fila del fichero contiene los nombres de columna, para que no la considere un dato más:
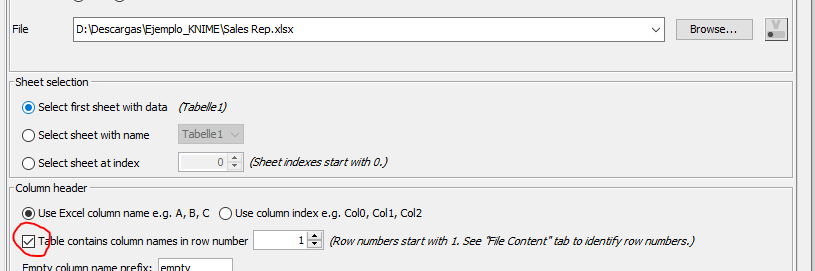
Ahora añadimos otro Excel Reader para cargar el fichero RegionDictionary.xlsx. Este archivo contiene una tabla con los emparejamientos entre las abreviaturas de área y los nombres completos. Ejecutamos ambos nodos para que carguen los datos respectivos.
Ahora vamos a reemplazar los valores abreviados por los completos, usando el nodo Value Lookup. Si miramos la descripción de este nodo, veremos que se encarga de reemplazar valores en una columna según un diccionario que se le debe pasar como segunda entrada. Así que conectamos los dos nodos anteriores a éste, de forma que el diccionario sea la segunda entrada (conexión inferior).
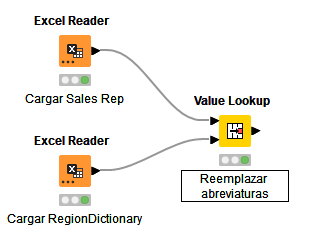
Hacemos doble clic en el nodo para configurarlo y elegimos en la sección de Matching las siguientes opciones: - Lookup column, columna de la tabla principal cuyos valores queremos reemplazar: (Sales Area) - Key column, columna del diccionario asociada: (Misspelled)
Y en la sección Output: - Lookup column output: indicamos la acción que queremos realizar, (Replace) - Replacement column, columna del diccionario que contiene los nuevos valores: (Regions)
El resto de opciones podemos dejarlas como están.
Finalmente, ejecutamos el nodo Value Lookup y podremos consultar el resultado final:
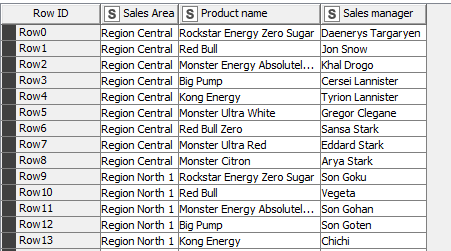
Para terminar este apartado, vamos a guardar los datos procesados en un fichero Sales Rep Clean.xlsx usando un Excel Writer. Adicionalmente, indicamos que se añadan las cabeceras de columna (Write column headers) y que se sobreescriba el fichero si ya existe. Ubicamos los ficheros de salida en la misma carpeta que los de entrada.
Así quedará el proyecto finalmente:
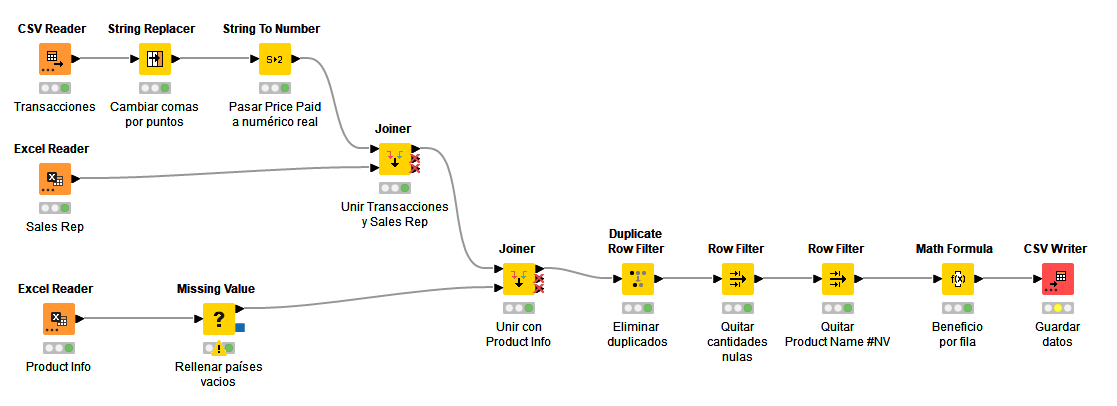
3.3. Combinar los datos procesados¶
Vamos ahora a unificar los contenidos del fichero global de transacciones, el de ventas que hemos procesado antes y el de información de los productos (Product Info), en un solo archivo gigante. Lo haremos en el workflow 03_CombinarDatos.
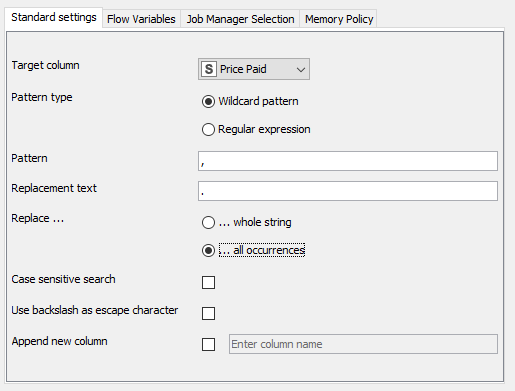
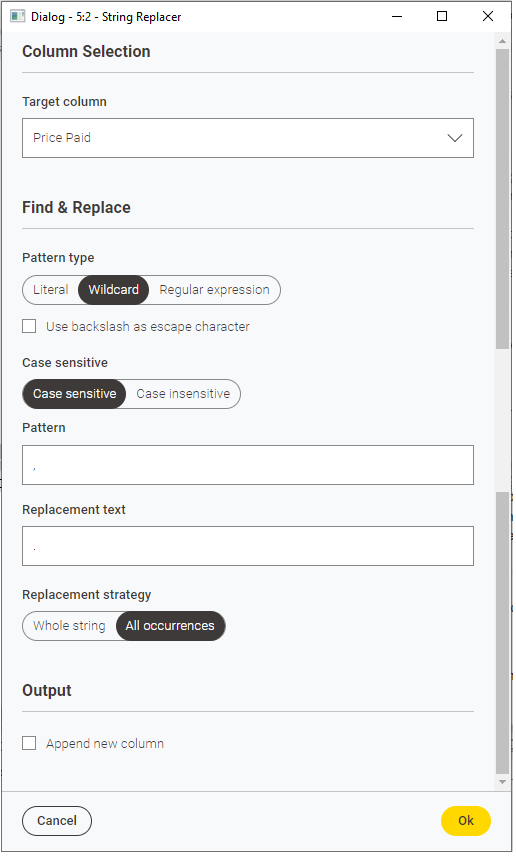
Para empezar, usaremos un CSV Reader para cargar el fichero FinalTransactions.csv que hemos generado en el paso anterior. Vamos a hacer algo de limpieza de datos: la columna Price Paid figura como tipo String (S) y nos interesa que sea numérica. Pero, para ello, debemos reemplazar las comas decimales por puntos. Usaremos un nodo String Replacer conectado al anterior para esta tarea. Lo configuramos para reemplazar comas por puntos.
Ahora vamos a cambiar el tipo de dato de esa columna, de cadena a número, usando el nodo String To Number. Configuramos el resultado como tipo double, y en la sección Includes dejamos sólo la(s) columna(s) que queramos convertir. Después, ejecutamos para dejarlo convertido.
Nota
Observa que en la configuración de este nodo también podemos especificar cuál es el separador decimal que hay, con lo que podríamos haber omitido el paso del String Replacer y usar sólo este nodo para hacerlo todo junto. Pero así exploramos cómo funcionan otros nodos de KNIME.
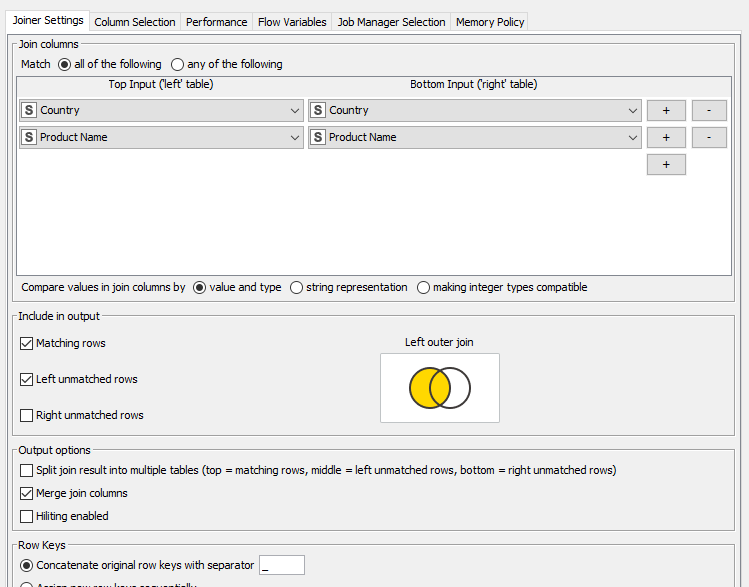
Ahora vamos a añadir un Excel Reader para cargar el archivo Sales Rep Clean.xlsx que también hemos generado en el paso anterior. Añadimos un nodo Joiner para enlazar los datos de ambos archivos, a través de las columnas Sales Area y Product Name comunes en los dos:
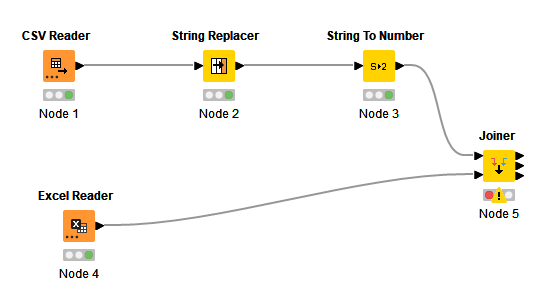
En la configuración del Joiner indicamos que queremos una relación Left Outer Join para preservar los datos de las transacciones, y especificamos el nombre de la(s) columna(s) de unión de ambos ficheros. En nuestro caso son las columnas de Sales Area y Product Name, que son comunes en ambos. También marcamos que se mezclen (Merge) las columnas de unión, para que no se dupliquen. Debe quedar así:
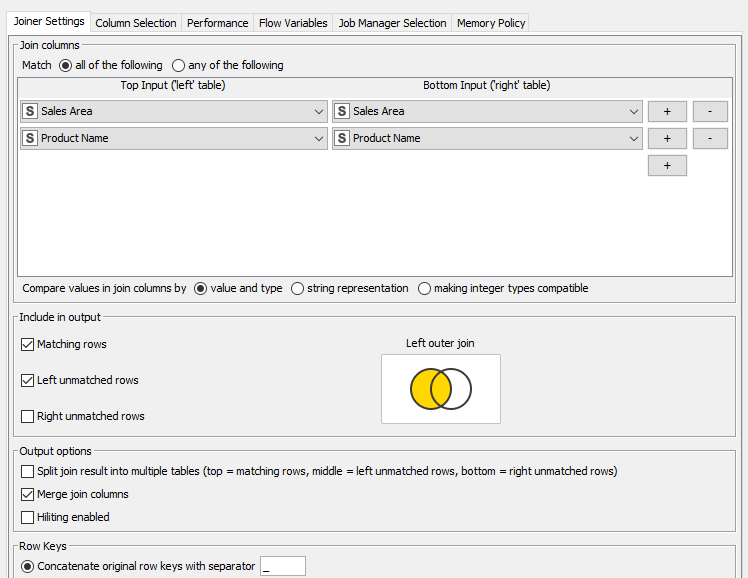
Podemos configurar algunas cosas más en el Joiner, como elegir concretamente qué columnas queremos tener en el resultado (pestaña Column Selection, donde por defecto se seleccionan todas). En nuestro caso será suficiente con lo que hemos hecho hasta ahora. Ejecutamos para obtener la tabla resultado, que será igual que la tabla inicial de transacciones, con la nueva columna Sales manager incluida desde la segunda tabla.
Añadiremos ahora otro Excel Reader para procesar el fichero Product Info.xlsx que tenemos desde el principio del proyecto, con información de los productos. En este caso, la columna Country tiene varios valores vacíos, ya que se supone que se repite el mismo país para datos de filas contiguas, hasta que cambiamos el país. Añadimos un nodo Missing Value y lo configuramos para que en las columnas de tipo String donde falten valores, los reemplace por el valor de la fila anterior:
Notar que, respecto a los valores numéricos, KNIME nos permite reemplazar los valores omitidos por un valor fijo, el máximo de columna, mínimo, media, etc.
Ahora añadimos un nuevo Joiner para unir todos los datos anteriores con éstos nuevos. Los campos de unión en este caso, compartidos en ambas tablas, son Country y Product Name.
Así es como debe quedar de momento este workflow:
3.4. Limpieza y presentación final de los datos¶
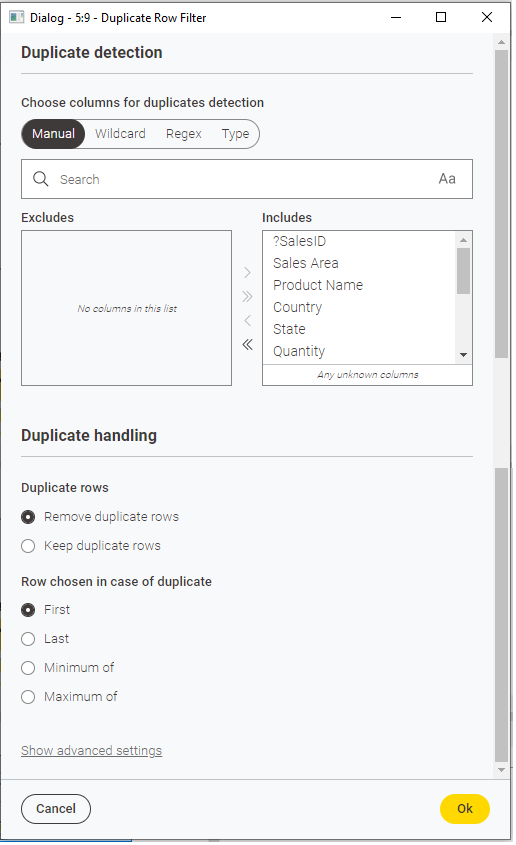
Sobre el proyecto anterior vamos a realizar ciertas operaciones finales de limpieza y presentación. En primer lugar, eliminamos filas duplicadas con el nodo Duplicate Row Filter, enlazándolo con el último Joiner anterior. En la sección Include añadimos todas las columnas, para que sólo considere duplicadas las filas que coincidan en todas las columnas. En la configuración avanzada (Advanced) podemos elegir si queremos eliminar duplicados (opción por defecto) o etiquetar filas duplicadas en una nueva columna (marcarlas como duplicadas, sin borrarlas).
Si ejecutamos el nodo, veremos que se eliminan unas 500 filas duplicadas de las más de 430.000 existentes.
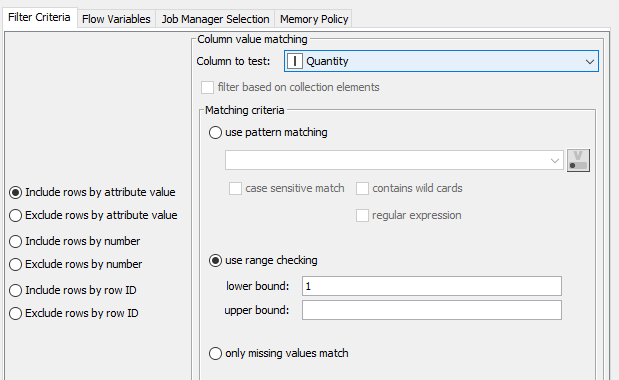
Ahora vamos a eliminar las filas que tengan cantidades negativas o 0 (columna Quantity), usando un Row Filter. O, dicho de otro modo, nos quedamos con las filas que tengan como cantidad 1 o más. Con esto eliminaremos unos 6.000 registros.
Eliminamos ahora las filas que tengan el Product Name a #NV (no disponible), por si hubiera alguno, usando otro Row Filter a continuación del anterior. En este caso esta operación no tiene resultados, pero vemos cómo podemos enlazar filtrados de inclusión/exclusión en el proceso.
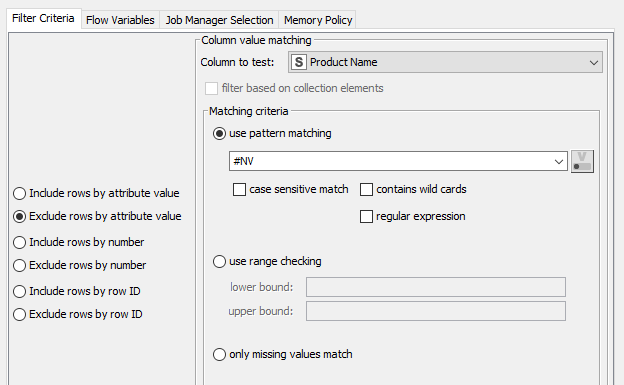
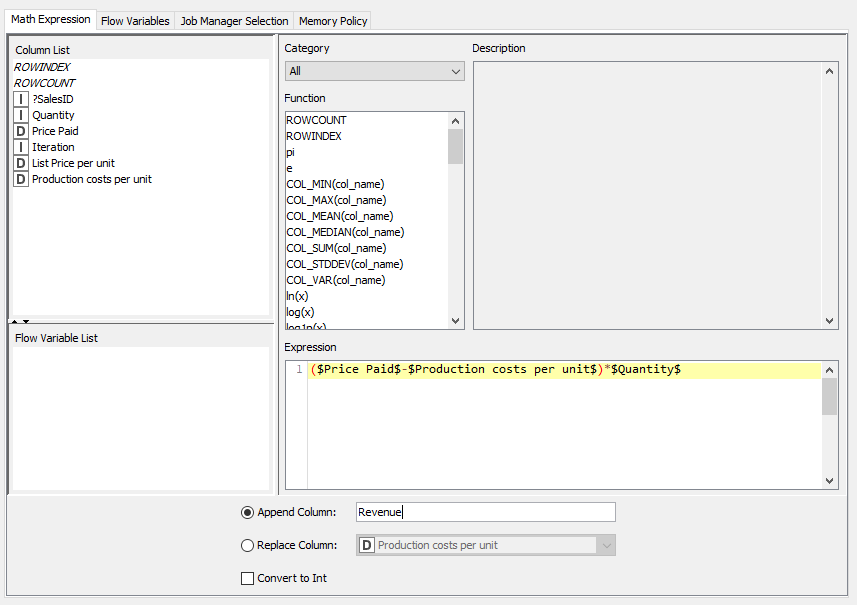
A continuación calcularemos el beneficio por fila. Lo haremos restando en cada fila o registro el precio pagado (Price Paid) menos el coste de producción (Production costs per unit) y multiplicando esa diferencia por la cantidad (Quantity). Emplearemos para este cálculo el nodo Math Formula, y especificaremos en su configuración la fórmula a emplear (haciendo doble clic sobre cada campo lo añadimos a la fórmula inferior):
Notar que especificamos también que todo esto lo calcule en una nueva columna que llamaremos Revenue ("Beneficio" en inglés).
Para finalizar este apartado, vamos a guardar los datos en un fichero CSV usando CSV Writer. Llamaremos al fichero FinalOutput.csv. Así quedará entonces el flujo de este workflow:
Ejercicio 2
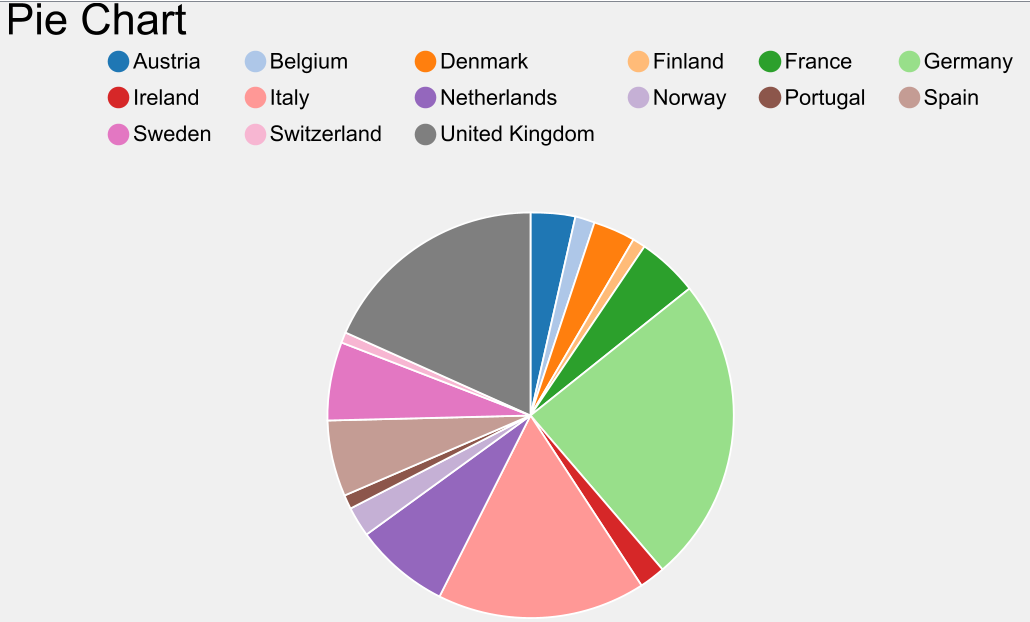
Sigue los pasos indicados en este apartado para completar todo el proyecto explicado paso a paso. Una vez lo tengas terminado obtén un gráfico circular de los beneficios acumulados por país. Deberás para ello quedarte con las columnas de Country y Revenue y hacer un GroupBy por país, sumando los beneficios de cada país. Finalmente, calcula también el beneficio total (puedes usar Math Formula y calcularlo en una columna aparte).
Solución Ejercicio 2
Aquí tienes un vídeo explicando el ejercicio de este apartado paso a paso.
4. Técnicas de machine learning en KNIME¶
KNIME no es sólo una herramienta de análisis y tratamiento de datos. También permite generar modelos relativamente complejos de machine learning. Evidentemente, sin tantas opciones de configuración y ajuste como podríamos tener usando SciKit Learn o Keras/TensorFlow. Pero constituye todo un "plus" el poder gestionar también el apartado de machine learning junto al de data science en la misma herramienta.
Si echamos un vistazo al repositorio de nodos (categoría Analytics, subcategoría Mining), podremos ver que KNIME incorpora ciertos nodos específicos para ciertas técnicas de machine/deep learning, tales como perceptrones multicapa (MLP), random forests, árboles de decisión, regresiones lineales... No dispone de toda la variedad de herramientas que podríamos usar, pero podemos elegir el que pensemos que puede sernos más útil, de entre el abanico que ofrece.
En la mayoría de los casos, la técnica consistirá en elegir un nodo para entrenar el modelo y otro para hacer predicciones sobre el modelo ya entrenado. Vamos a retomar por ejemplo el Ejercicio 1 planteado anteriormente, y vamos a definir una máquina de soporte vectorial (SVM) sobre el dataset del Titanic para predecir los supervivientes. El objetivo de esta técnica es encontrar un hiperplano en un espacio N-dimensional (N es el número de características) que clasifique claramente los puntos de datos en diferentes clases.
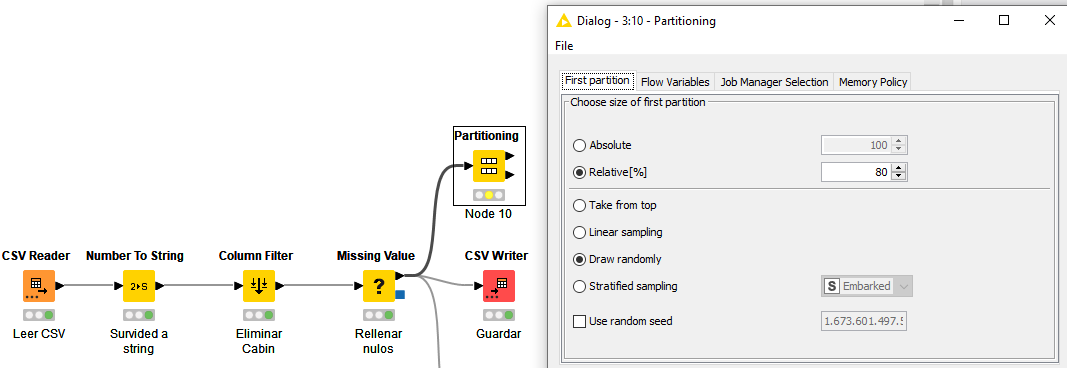
En primer lugar, conectaremos la salida del proceso de limpieza de datos de ese ejercicio con un nodo llamado Partitioning (o Table Partitioner en versiones más recientes), que se va a encargar de realizar las particiones de entrenamiento y test. Definiremos un 80% para entrenamiento y el resto para test.
Ahora vamos a usar un SVM Learner para entrenar el modelo. Conectamos la rama de entrenamiento (salida superior del nodo Partitioning) con este nuevo nodo, y lo configuramos para que prediga la columna Survived. Observa que admite varios tipos de núcleos, como Hiper Tangente, Polinómico y RBF (Radial Basis Function). Para el caso que nos ocupa, elegiremos el núcleo Polinómico porque permite modelar relaciones complejas entre las características. Nos dirá en un warning que se descartan las columnas categóricas en el proceso, puesto que no puede operar con ellas. Lo podemos ejecutar para que vaya entrenando, y mientras añadimos un nodo SVM Predictor, y lo conectamos con la salida del modelo (cuadro azul del Learner), y con la segunda salida del nodo Partitioning (conjunto de test). Conectamos finalmente el SVM Predictor con un Scorer para ver los resultados.
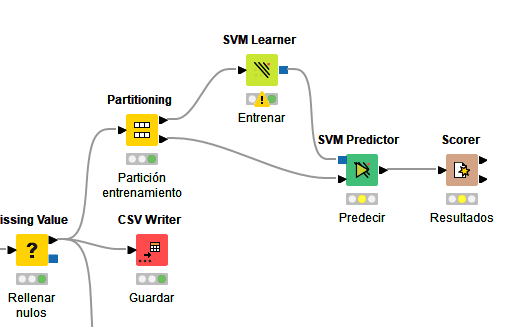
Configuramos el Scorer para que coteje la columna Survived con la estimación Prediction (Survived).

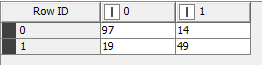
Al finalizar el proceso, en el Scorer podremos ver tanto la matriz de confusión con los resultados (cuántos falsos positivos o negativos ha habido) como otras estadísticas, como la exactitud (accuracy), sensibilidad (recall) o especificidad (specificity) .
- Precisión: proporción de predicciones positivas correctas respecto al total de predicciones positivas realizadas por el modelo.
- Sensibilidad: proporción de positivos reales que fueron identificados correctamente por el modelo.
- Especificidad: proporción de negativos reales que fueron identificados correctamente.
4.1. Algunos ejemplos disponibles¶
Además de la SVM que hemos utilizado en el ejemplo anterior, dentro de KNIME podemos hacer uso de otras técnicas de machine/deep learning, tales como:
- Regresiones lineales o polinómicas con Linear Regression Learner o Polynomial Regression Learner. Luego podemos ver las predicciones con el Regression Predictor
- Random Forests con Random Forest Learner y Random Forest Predictor
- Perceptrones multicapa con RProp MLP Learner y MultiLayer Perceptron Predictor
- ... etc.
Ejercicio 3
Utiliza este dataset sobre datos de tumores mamarios. Carga el CSV, elimina la primera columna (y la última si aparece vacía) y construye un Random Forest que prediga la columna objetivo diagnosis en función de las demás.
5. Otras opciones de KNIME¶
Además de las posibilidades que hemos visto en el ejemplo completo anterior, KNIME ofrece muchas otras opciones que pueden sernos de mucha utilidad. Vamos a repasar ahora algunas de ellas.
5.1. Consulta a APIs externas¶
Una de las opciones más potentes que ofrece KNIME es la posibilidad de consultar una API externa, obtener los resultados y utilizarlos junto con los datos de entrada. Por ejemplo, supongamos que, para el ejemplo anterior de ventas de productos energéticos, queremos hacer un cambio de divisa. Los precios de venta de la columna Price Paid en las transacciones están dados en euros (por ejemplo), pero queremos convertirlos a dólares.
Emplearemos una API REST, de forma que obtendremos los datos actualizados en formato JSON. En esta web podemos registrarnos y realizar una suscripción gratuita a esta API, lo que nos permitirá consultarla un número limitado de veces al mes. Esto nos dará una API Key, que deberemos utilizar cada vez que queramos consultar la API en cuestión.
Para realizar las peticiones a la web desde KNIME usaremos el nodo GET Request. En la configuración especificaremos la URL a la que acceder (https://api.apilayer.com/exchangerates_data/latest en nuestro caso).
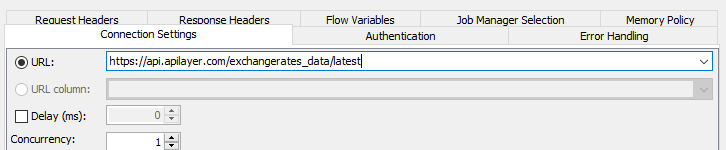
En la pestaña de Request Headers especificaremos la API Key que nos habrán facilitado en la suscripción gratuita (se oculta en este ejemplo por motivos de privacidad).
Si ejecutamos el nodo, podremos ver el resultado con los datos devueltos, en formato JSON. Se toma como moneda base el euro (EUR), el resto de divisas indican el cambio respecto a esta base.
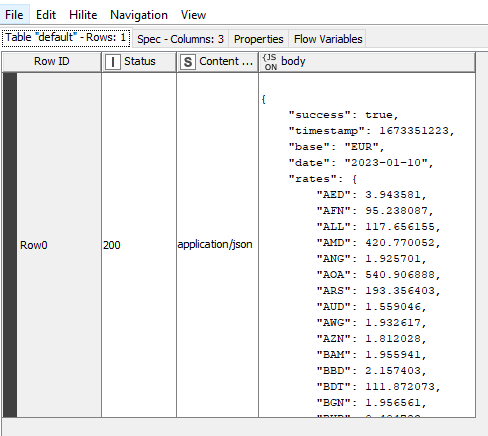
Hay que tener en cuenta que el resultado que obtenemos vendrá en formato JSON. Usaremos ahora el nodo JSON Path para extraer la información que nos interese. Conectamos este nodo con el anterior, y lo configuramos. En nuestro caso, vamos a quedarnos con los cambios de la(s) divisa(s) que nos interesen, como el dólar (USD). Hacemos clic en cada línea de divisa que nos interese y hacemos clic en el botón Add single query, para añadirlas a la sección de Output. Notar además que estamos tomando los datos del campo body de la petición anterior, tal y como se ve en la parte superior del panel.
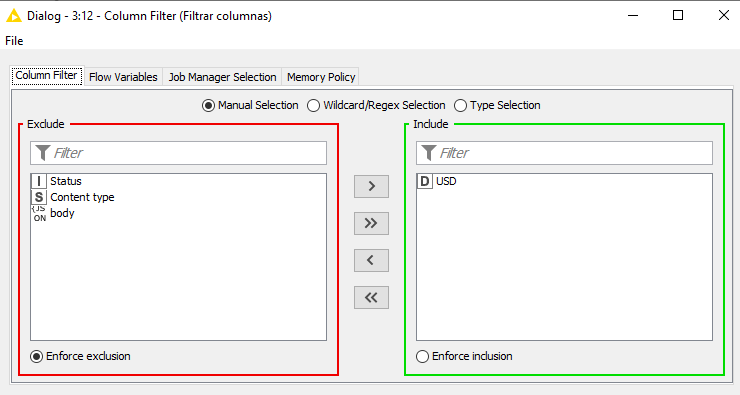
Ejecutamos ahora este nodo, y lo que obtendremos como resultado será una tabla, donde cada columna tiene uno de los cambios que hemos seleccionado. Vamos a conectarlo ahora con un Column Filter para quitar las otras columnas del resultado que no nos interesan, y quedarnos sólo con las de las monedas.
Este es el aspecto que tendrá esta nueva parte de nuestro proyecto:
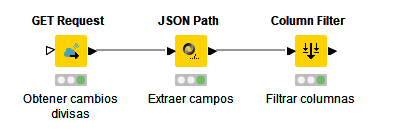
A partir de aquí, podemos guardar esta tabla en un archivo Excel o CSV, y utilizar los campos para crear nuevas columnas en el fichero de transacciones, convirtiendo la moneda original en otra.
Ejercicio 4
Partiendo del Ejercicio 2 sobre los estudios sobre ventas de bebidas, y suponiendo que los precios están dados en euros (EUR), accede a la API del ejemplo anterior para calcular el beneficio total en dólares (USD).
Pista
Utiliza el nodo Table Column To Variable para guardar el una variable el cambio euro-dolar que consigas a través de la llamada a la API, y luego un Math Formula para aplicarlo sobre la columna del beneficio total.
5.2. Integración con otras herramientas¶
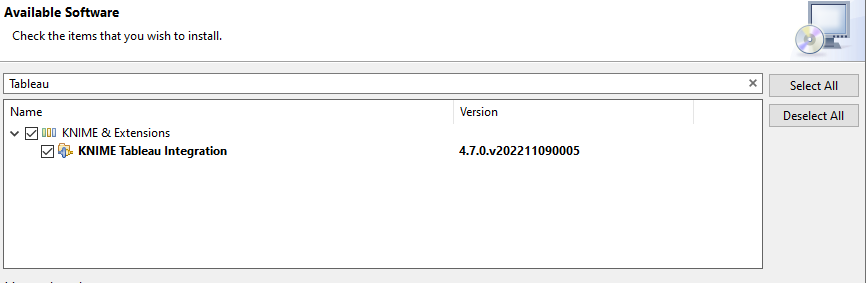
KNIME puede generar contenido compatible con herramientas externas. Por un lado, podemos emplear herramientas de visualización de datos, tales como Tableau o Power BI. Desde el menú File > Install KNIME Extensions podemos instalar extensiones relacionadas con Tableau:
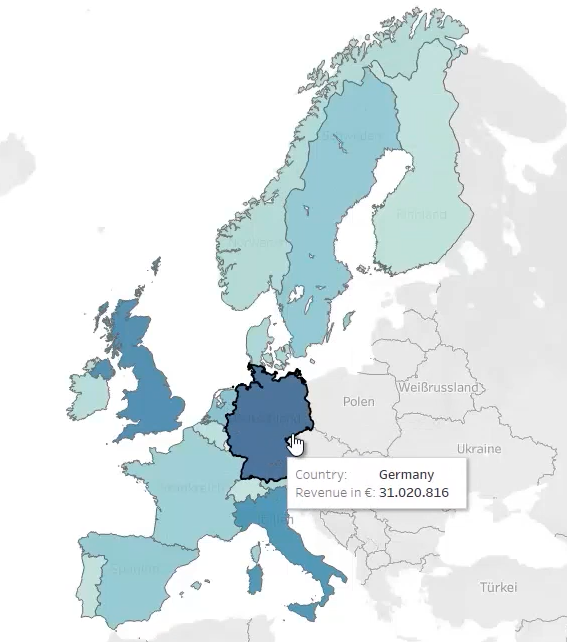
Después, se puede generar la información en un formato de fichero compatible con Tableau y usarla en esa herramienta. Aquí podéis consultar más información al respecto, ya que es algo que no haremos en este documento. Pero utilizando herramientas de este tipo se pueden visualizar los datos de muchas formas. Por ejemplo, podemos ver un mapa con las ventas por países (usando la columna Country y las ventas ya calculadas)
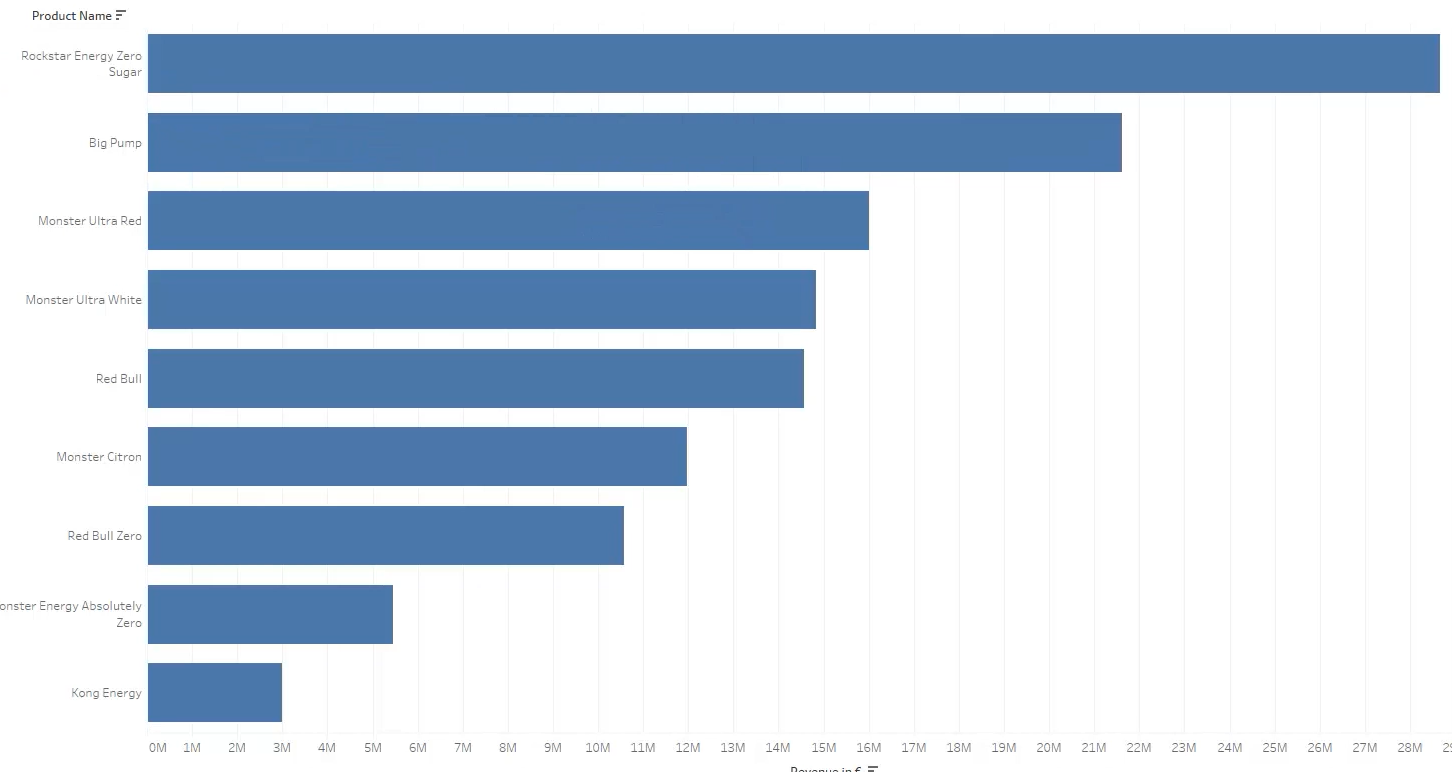
También podemos sacar los productos más vendidos, ordenados de mayor a menor
O las ventas de productos por regiones:
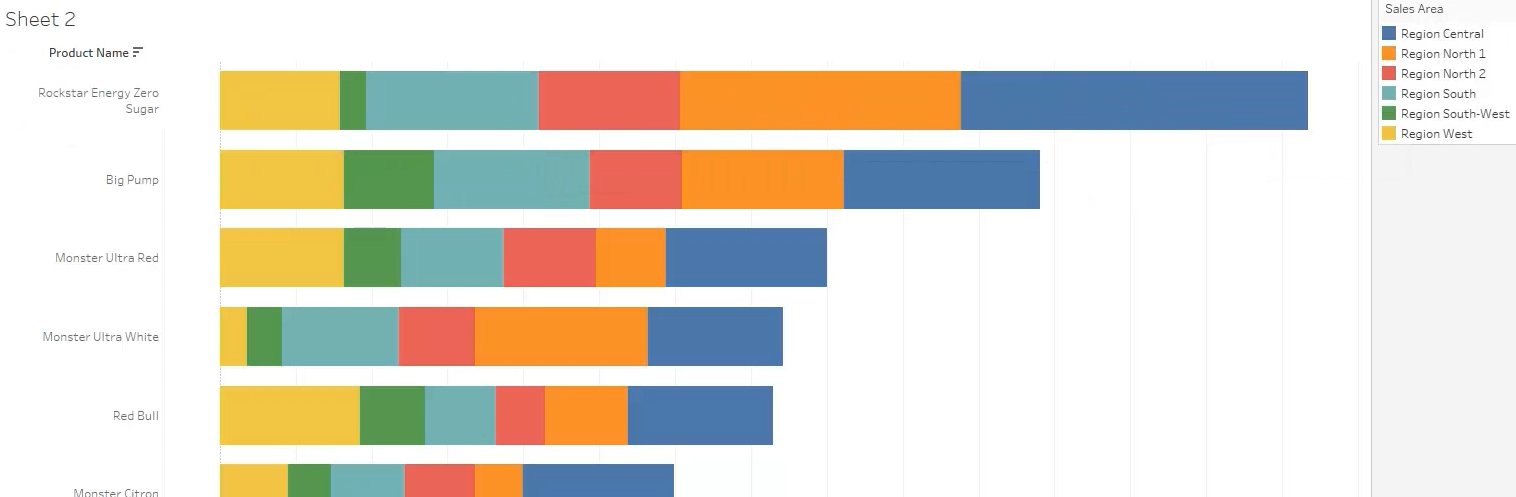
En lo que respecta a Power BI, podemos tomar como fuente de entrada el archivo CSV final que hemos creado con todos los datos. Desde esta herramienta podemos obtener visualizaciones similares a las de Tableau.
Además, KNIME también incorpora integración con herramientas de machine learning, como la librería Keras. Podemos instalar la extensión de integración con Keras desde File > Install KNIME Extensions también:
Con esta extensión tendremos disponibles una serie de nodos para construir redes neuronales usando las distintas capas y opciones de Keras:
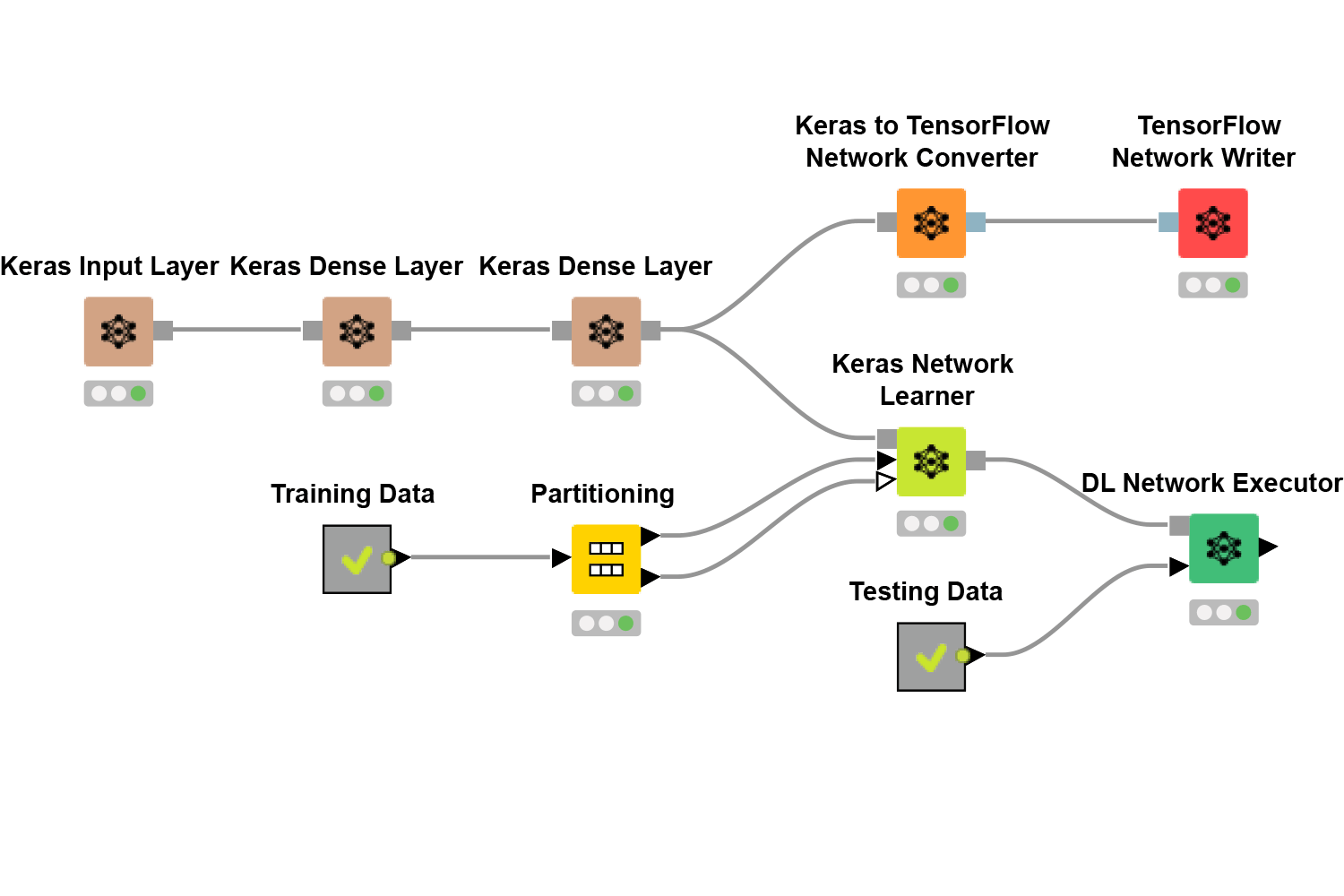
A continuación se detalla el workflow anterior:
- Keras Input Layer, Keras Dense Layer: representa la construcción de una red neuronal en Keras, iniciando con una capa de entrada y seguida de dos capas densas.
- Keras to TensorFlow Network Converter: convierte la red construida en Keras a un formato compatible con TensorFlow, facilitando su ejecución en este entorno.
- TensorFlow Network Writer: guarda la red convertida en un formato que puede ser utilizado posteriormente o exportado.
- Partitioning: divide los datos en un conjunto de entrenamiento, que alimenta al aprendizaje, y un conjunto de prueba, que se utiliza para evaluar el modelo.
- Keras Network Learner: entrena la red neuronal utilizando los datos proporcionados.
- DL Network Executor: evalúa la red neuronal ya entrenada usando los datos de prueba.
5.3. El KNIME Hub¶
Además de la herramienta analítica offline (y gratuita), KNIME proporciona un hub para poder gestionar nuestros proyectos de forma online. Hay una suscripción gratuita a dicho hub, para tener un espacio limitado donde dejar nuestros trabajos, y luego hay una suscripción comercial para poder trabajar en grupo o compartir y acceder al trabajo dejado por otras personas en dicho hub. También se pueden descargar extensiones o nodos nuevos realizados por esas terceras partes.
Aquí se puede consultar más información acerca del funcionamiento, contenidos y precio de dicho hub.
6. Alternativas a KNIME¶
Existen en el mercado algunas herramientas alternativas a KNIME para trabajar el modelado de datos, e incluso definir también nuestros propios modelos de machine/deep learning. Algunas de las más populares son:
- IBM SPSS Modeler: herramienta comercial de IBM. Tiene una versión de prueba y para estudiantes con una validez de 30 días al año. Dispone de una interfaz para definir de manera gráfica el procesamiento de los datos y la generación de modelos de IA, de forma similar a KNIME.
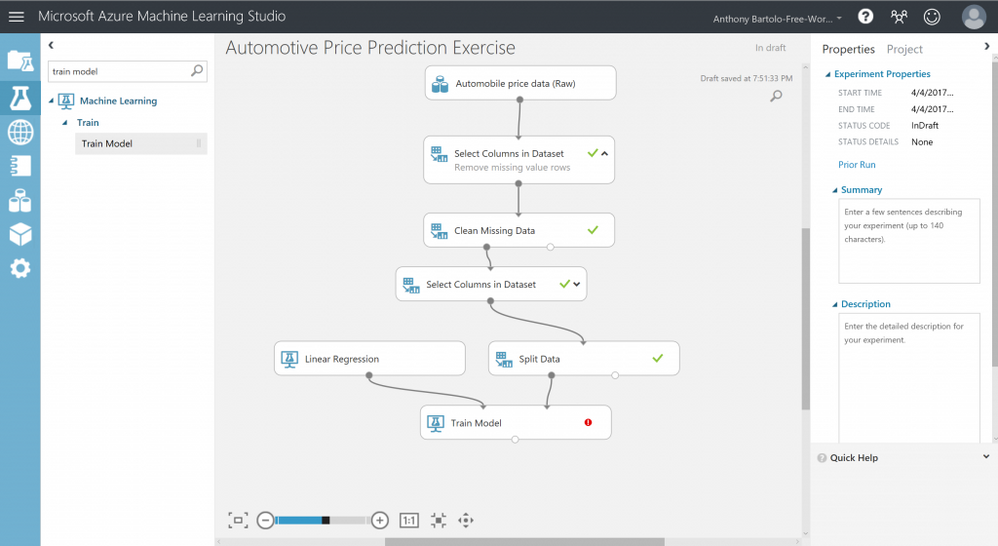
- Azure Machine Learning Studio: herramienta similar a las anteriores, perteneciente al universo Azure. Se ejecuta en la nube de la plataforma, integrada con el resto de elementos de Azure.
Ayuda
Aquí tienes un vídeo resumen de explicación de estos últimos apartados.