Introducción a los modelos pre-entrenados¶
En la actualidad existen multitud de modelos ya entrenados con grandes cantidades de datos. Muchos de ellos son públicos, con lo que podemos descargarlos y/o utilizarlos para nuestros propios intereses. Veremos a continuación algunos ejemplos de ello, y cómo podemos utilizarlos. Sin embargo, antes de comenzar es necesario acotar el ámbito en que vamos a movernos. La mayoría de modelos que podemos encontrar en Internet para utilizar se centran en cuatro áreas principales:
- Clasificación/Segmentación de imágenes
- Procesamiento de vídeo (segmentación, clasificación...)
- Procesamiento de textos (lenguaje natural)
- Procesamiento de audio (identificación de voz, clasificación...)
1. Kaggle¶
Kaggle es un sitio web con multitud de recursos para inteligencia artificial, desde datasets de distintas temáticas hasta distintos concursos para poner a prueba los modelos que desarrollamos. Y, desde hace poco tiempo, también dispone de un repositorio donde poder acceder y utilizar distintos modelos desarrollados. Aquí podemos acceder al buscador general.
Como podemos ver en el buscador, se permite filtrar por diferentes criterios:
- Por la tarea a realizar: clasificación de imágenes, generación de textos...
- Por el tipo de datos a manejar: imágenes, textos, audios...
- Por el framework a utilizar: Keras, TensorFlow, PyTorch...
- Por la empresa que lo ha publicado
- ... etc.
Dependiendo del modelo a usar, las instrucciones para acceder a él variarán. Vamos a echar un vistazo a este modelo de detección de objetos y clasificación de imágenes. Se trata del modelo MobileNet, que entrena sobre la base de datos ImageNet. ImageNet es una enorme base de datos con más de 14 millones de imágenes y más de 20.000 categorías disponibles. Varios modelos de redes se han creado sobre esta base de datos, y son públicos y descargables. En concreto MobileNet es capaz de distinguir 1.000 categorías distintas de imágenes del catálogo.
El modelo en cuestión está hecho bajo TensorFlow, y necesitaremos tener instalados los paquetes tensorflow y tensorflow_hub, ya que antiguamente correspondía a un modelo hubicado en un hub de modelos propio de TensorFlow. También puede ser necesaria la librería tf_keras, que compatibiliza las clases de Keras con las del hub de TensorFlow.
Aquí podemos descargar un ejemplo de documento Colab que utiliza este modelo para clasificar la imagen que le facilitemos. Podemos ejecutarlo y probarlo con alguna imagen que subáis de ejemplo, como las que se proporcionan en el propio ZIP.
Observemos algunas características relevantes del código. Por ejemplo, así cargamos el modelo en una red Keras:
# La URL podría variar en un futuro si llegan nuevas versiones
url_modelo = 'https://www.kaggle.com/models/google/mobilenet-v2/TensorFlow2/035-224-classification/2'
# El modelo seleccionado admite imágenes de entrada de 224x224
tam_imagenes = (224, 224)
# Añadimos una tercera dimensión para indicar imágenes a color
modelo = tf_keras.Sequential([
hub.KerasLayer(url_modelo, input_shape = tam_imagenes + (3,))
])
En el resto del código del documento Colab se procesa la imagen que facilitemos, se escala al tamaño de entrada (224x224), se normalizan los valores a un rango de 0 a 1 y se le pasa al modelo para que la prediga.
Ejercicio 1
Descarga y prueba el modelo del documento Colab. Utiliza algunas imágenes de prueba (que correspondan a algunas de las categorías disponibles) y comprueba si es capaz de clasificarlas correctamente.
2. OpenAI¶
OpenAI es, a día de hoy, una de las empresas más punteras en el desarrollo de modelos de Deep Learning. Es muy conocida por algunos de sus "productos estrella", como Chat-GPT o DALL-E, y permite que utilicemos de forma gratuita (aunque limitada) sus productos vía API. Debemos acceder a la web y crear una cuenta. Una vez creada, en el menú izquierdo podemos crear una API Key, y también gestionar los límites de consumo, ampliarlos, etc, a través de la sección Usage.
Advertencia
En el momento en que se han actualizado estos apuntes, OpenAI no dispone de un programa gratuito de prueba de sus modelos. En años anteriores, los nuevos usuarios recibían 18 USD de crédito gratuito para gastar los 3 primeros meses de prueba, pero ese programa desapareció. A falta de que aparezca una política de prueba similar, se ofrece a continuación un ejemplo de código de cómo probar estos servicios, en caso de ser posible hacerlo sin ofrecer datos de pago.
Después, en la sección de documentación podemos consultar los modelos disponibles. En esta sección vamos a centrarnos en dos de ellos:
- Generación de texto (GPT), siguiendo los pasos indicados en la documentacion
- Generación de imágenes (DALL-E), siguiendo también la documentación correspondiente.
Por ejemplo, vamos a utilizar GPT. Antes de nada, debemos instalar la librería openai en nuestro sistema con el correspondiente comando:
pip install openai
Incorporamos la librería en nuestro programa, y en la propiedad api_key deberemos indicar la clave que hayamos generado previamente en la web:
from openai import OpenAI
cliente = OpenAI(
api_key= 'XXXXXXXX' # Añadir aquí nuestra API Key
)
Después, para hacer uso de GPT, debemos indicar cuál será nuestro motor de generación de texto en el parámetro model. Si accedemos a la documentación podemos ver que hay varias opciones disponibles, algunas más obsoletas y limitadas y otras más actuales. Por ejemplo, usaremos como motor gpt-5-mini, y le lanzamos una pregunta en español. En la respuesta tendremos el texto de la respuesta enviada:
pregunta = input("Escribe tu pregunta:\n")
respuesta = cliente.responses.create(
model="gpt-5-mini",
input=pregunta
)
print(respuesta.output_text)
Ejercicio 2
Vamos a utilizar ahora el modelo de generación de imágenes de OpenAI para generar imágenes a partir de texto. Aquí tienes una guía de cómo utilizarlo. Escribe un programa donde el usuario indique lo que quiere que tenga la imagen, y nos devuelva los bytes de la imagen generada.
3. Google AI Studio¶
De un modo similar a OpenAI, Google también pone a disposición de los desarrolladores sus modelos para poderlos usar y probar, a través de Google AI Studio.
Lo primero que tendremos que hacer es obtener una API Key desde el menú correspondiente del panel izquierdo. Podemos comprobar que tenemos el nivel gratuito de uso, y copiar la API Key al portapapeles para usarla en nuestros programas:
Una vez tengamos configurada la cuenta, debemos instalar la librería oficial en nuestro sistema o entorno:
pip install google-genai
Vamos a echar un vistazo a los modelos disponibles. Haremos una prueba de generación de texto con Gemini.
from google import genai
cliente = genai.Client(api_key='...')
response = cliente.models.generate_content(
model="gemini-2.5-flash", contents="Dime cuántos son 2+2"
)
print(response.text)
Aquí puedes consultar más información sobre la generación de texto. Como podrás comprobar, no todos los modelos están disponibles en el plan gratuito, y muchos de ellos tienen restricciones de peticiones por minuto (Requests Per Minute, RPM), tokens por minuto (TPM) o peticiones por día (RPD). Puedes consultarlas aquí
Ejercicio 3
Echa un vistazo a la API de text-to-speech (generación de audio), y haz un programa que le pida al usuario una pregunta y le diga la respuesta con voz. Aquí puedes encontrar información sobre generación de voz.
Pista
El modelo de text-to-speech en su uso gratuito tiene limitaciones importantes. Asegúrate, antes de invocarlo, de que el texto que va a reproducir es el que tú quieres. Puedes configurar distintas voces seleccionables (listado aquí).
También puedes indicar, cuando te den la respuesta, que el modelo sea conciso para que no se generen demasiados tokens.
respuesta = cliente.models.generate_content(
model="gemini-2.5-flash", contents=pregunta,
config=types.GenerateContentConfig(
system_instruction="""Eres un asistente ultra-conciso.
Tus respuestas deben tener un máximo de 2 frases.
Asegúrate siempre de terminar la idea y cerrar todas las oraciones.
No uses introducciones innecesarias como 'Claro, aquí tienes'."""
)
)
4. Hugging Face¶
Hugging Face es una empresa y plataforma de inteligencia artificial y aprendizaje automático, especializada en el desarrollo y distribución de modelos. Proporciona una biblioteca de código abierto llamada Transformers que facilita el uso de modelos avanzados, permitiendo a los desarrolladores integrar IA en sus proyectos de manera sencilla. Además, ofrece un repositorio donde la comunidad puede compartir modelos, datasets y herramientas para la investigación y el desarrollo en inteligencia artificial. En general, podemos acceder a todos estos modelos a través de una API. Como paso previo inicial, deberemos registrarnos en la web de forma gratuita.
Aunque la documentación al respecto ha ido variando en estos últimos años, y en ocasiones es difícil consultar la forma correcta de usar un modelo determinado, podemos decir que existe una forma común de acceder a muchos de ellos. La URL de acceso tiene siempre el prefijo https://router.huggingface.co/hf-inference/models/, seguido del endpoint específico del modelo a probar.
Además, necesitaremos tener un token de acceso para probar los modelos. Podemos conseguir uno desde el apartado de tokens de nuestro perfil.
Ahora ya tenemos todo lo necesario para acceder a un servicio determinado. Podemos emplear la librería requests y construir la petición de este modo:
import requests
# Completar con el endpoint del servicio solicitado
API_URL = "https://router.huggingface.co/hf-inference/models/...."
# Completar con nuestro token de acceso
headers = {"Authorization": "Bearer hf_xxxxxxxxxxxxxxxxxxxxxxxx"}
# Función que se ejecutará para hacer la petición
# El parámetro "payload" es un objeto JSON con los datos que necesita el modelo
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.json()
respuesta = query({ ... })
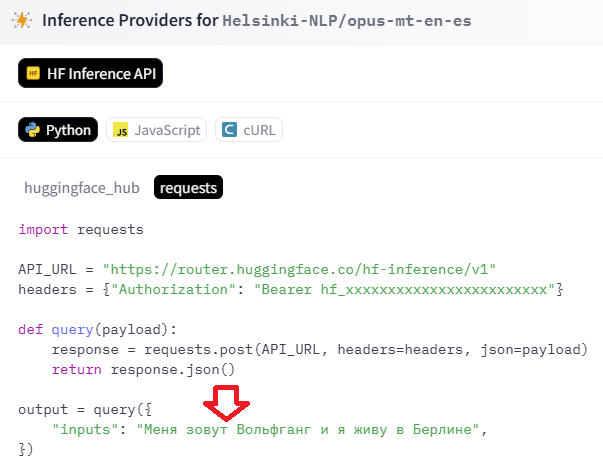
Para saber qué datos hay que pasarle al modelo en cuestión, podemos ir a la sección Deploy del modelo (parte superior derecha) y elegir Inference Providers. En la sección de Python podemos ver un ejemplo de código con la librería requests, y averiguar la información que se le pasa a la función query que hemos definido.
Nota
Como puede verse en la imagen anterior, también es posible acceder a los modelos a través del SDK propio de Hugging Face (pestaña huggingface_hub). Practicaremos con un ejercicio de cada tipo, aunque esta segunda opción puede requerir para cada modelo de la instalación de paquetes adicionales.
Ejercicio 4
Vamos a probar un modelo de Hugging Face. En concreto este traductor de inglés a español. Así, el endpoint que deberás añadir a la URL base será Helsinki-NLP/opus-mt-en-es. Prueba a enviar un texto en inglés y ver la estructura de la respuesta para poder sacar la traducción del campo adecuado
Nota
En algunos servicios de Hugging Face es posible que, la primera vez que los invoquemos, al estar inactivos, obtengamos un mensaje de error como respuesta JSON. Pasados unos segundos, cuando el modelo ya se haya puesto en marcha, podremos obtener una respuesta correcta.
Ejercicio 5
Vamos a probar ahora un modelo de análisis de imágenes que permita determinar la edad y el género de las personas que aparecen en una foto. En concreto usaremos el modelo ViT-Age-Gender-Prediction, cuya documentación se puede consultar aquí. Como puedes comprobar, se trata de un Vision Transformer, y en la web pone la forma recomendada de uso, y aquí puedes descargar el modelo (model.py). Elige una foto donde aparezca una persona y pásala al modelo para que determine su edad.
Es posible que necesites añadir este cambio al fichero model.py que descargues:
processor = AutoImageProcessor.from_pretrained(
"abhilash88/age-gender-prediction",
# Añadir esto
do_center_crop=False
)
5. Otros recursos¶
Además de los recursos vistos anteriormente, existen otros sitios en Internet donde utilizar modelos pre-entrenados. Aquí mostramos un listado de algunos de los más populares:
- Model Zoo, un repositorio de modelos al estilo de Kaggle o Hugging Face, aunque para descargar el modelo entero y adaptarlo a nuestro sistema a desarrollar. Dispone de modelos de diferentes categorías (procesamiento de imágenes, textos, etc.)
- PyTorch Hub, un repositorio realizado por y para la librería PyTorch de Facebook. Algunos de los modelos están también disponibles en Kaggle.
- Papers with code
- También existen librerías específicas descargables con modelos pre-entrenados incorporados.
Ejercicio 6
Descarga la librería textblob (comando pip install textblob). Dispone de un conjunto de modelos pre-entrenados para procesamiento de lenguaje natural, con tareas como análisis de sentimiento, extracción de palabras clave, etc. Utilízala para análisis de sentimiento con la frase que le pidamos al usuario. Aquí tienes información sobre cómo usarla, y aquí en concreto sobre el análisis de sentimiento.