Introducción al machine learning¶
En documentos anteriores ya hemos dado algunas nociones del machine learning o aprendizaje automático. En este documento veremos más en profundidad en qué consiste, diferentes tipologías, aplicaciones prácticas, etc.
1. Definición y conceptos asociados¶
Si buscamos en Internet una definición para machine learning o aprendizaje automático, podemos encontrar varias muy parecidas. En general, podemos definirlo como la rama de la inteligencia artificial que engloba un conjunto de técnicas por las que una máquina aprende a modificar su comportamiento para resolver mejor un problema. Es importante el término aprende, ya que esto implica que nosotros no tenemos que decirle cómo tiene que resolver el problema, sino los datos con los que va a trabajar y (en muchas ocasiones) los resultados que debe producir con esos datos. Así, el propio sistema aprenderá a ajustarse para, a partir de los datos recibidos, dar una respuesta lo más acertada posible.
Los datos de entrada que proporcionamos al sistema para que aprenda a ajustarse se denominan conjunto de entrenamiento (training set), y cada uno de esos datos es una muestra del conjunto. El sistema que aprende a procesar esos datos para dar una respuesta es (o será) nuestro modelo. Lo bien o mal que el modelo hace su trabajo se mide en base a su exactitud (accuracy).
1.1. Elementos habituales¶
En (casi) cualquier proceso de machine learning intervienen una serie de elementos que conviene conocer.
1.1.1. Entradas y salidas¶
Cualquier modelo de inteligencia artificial está basado en entradas y salidas: al sistema se le proporcionan una serie de datos de entrada (una imagen, una serie de valores numéricos, el estado de un tablero de juego, etc) y produce una salida (identificación de un objeto en la imagen, predicción de un futuro valor numérico, valoración de la siguiente jugada a realizar...)
Consideremos, por ejemplo, un sistema de identificación de objetos en imágenes. La entrada (también llamada estado) sería cada una de las imágenes que proporcionamos al sistema, y la salida sería un texto o código que identifique cada uno de los posibles objetos para los que el sistema está preparado. Por ejemplo: 1 = coche, 2 = semáforo, 3 = peatón...
1.1.2. El feedback o recompensa¶
Un segundo elemento importante en la mayoría de modelos de machine learning es el feedback que el modelo recibe, o la recompensa o castigo que obtiene por haber identificado correcta o incorrectamente el objeto, en el caso anterior.
Esta recompensa o feedback va a variar mucho dependiendo del sistema a desarrollar. En un sistema de identificación como el anterior podemos proporcionar un feedback de 0 o 1, dependiendo de si el sistema ha identificado correctamente el objeto o no. En un sistema que aprenda a jugar a un videojuego, la recompensa quizá no debería ser tan limitada, y ser mayor cuanta mayor puntuación haya obtenido el sistema en el juego, por ejemplo.
Este feedback, junto con las entradas y salidas comentadas anteriormente, conforman lo que se conoce como el entorno de IA, la base sobre la que vamos a desarrollar lo demás.
1.1.3. El proceso de decisión¶
El proceso de decisión define cómo interactúa la IA con el entorno definido anteriormente. El proceso comienza con un estado inicial y se basa en una serie de iteraciones. Cada iteración consta de los siguientes pasos:
- Se observa el estado actual (entrada)
- Se realiza alguna acción (emitir una salida)
- Se obtiene un feedback o recompensa
- Se pasa al siguiente estado
El objetivo siempre es maximizar las recompensas a lo largo del tiempo.
1.1.4. Entrenamiento e inferencia¶
En muchos procesos machine learning existen dos fases:
- La fase de entrenamiento, en la que el sistema aprende a realizar su trabajo. En esta fase es donde entran en juego los elementos anteriores, y el proceso de decisión ayuda, iteración tras iteración, a ir moldeando el sistema para perfeccionarlo.
- La fase de inferencia donde, con el sistema ya "maduro" y entrenado, se infieren nuevos datos. En nuestro ejemplo anterior de identificación de objetos, la fase de entrenamiento consistiría en ir confirmando o desmintiendo si cada objeto que identifica el sistema es correcto o no. La fase de inferencia ya no suele tener feedback, y simplemente dejamos que el sistema deduzca objetos a partir de imágenes no supervisadas, que no ha visto aún.
2. Tipos de machine learning¶
Se pueden clasificar los tipos de machine learning atendiendo a distintos criterios.
2.1. Por la supervisión del modelo¶
Según el grado de supervisión del modelo a desarrollar, distinguimos entre:
- Aprendizaje supervisado: se parte de un conjunto de datos etiquetados, es decir, un conjunto de datos junto con la respuesta correcta que se debe emitir para cada uno. De este modo, el sistema recogerá unos datos, emitirá una respuesta, la cotejará con la correcta y esto le permitirá reajustar sus parámetros para futuras operaciones. Esto puede usarse, por ejemplo, para predecir el precio de venta de un inmueble en base a sus datos (año de construcción, superficie, número de habitaciones, etc), o para clasificar imágenes de animales, entre otras cosas.
- Aprendizaje no supervisado: no existe ninguna información etiquetada de entrada. Se proporcionan datos sin una "respuesta correcta", por así decirlo, y el mismo sistema se dedica a elaborar un resultado en base a los datos de entrada que recibe. Por ejemplo, para agrupar los elementos de un conjunto de datos en categorías.
- Aprendizaje semi-supervisado: hay una parte del proceso supervisada y otra que no. Puede ser útil en los casos en los que obtener una gran cantidad de datos etiquetados sea difícil, y con unos pocos el sistema sea capaz de extrapolar y deducir el resto. O para etiquetar en bloque elementos que el sistema haya agrupado en categorías. Por ejemplo, dado un conjunto de fotos familiares, el sistema puede agruparlas de forma no supervisada según la gente que aparece en ellas, y luego nosotros etiquetar esos grupos para que el sistema ya pueda clasificar nuevas fotos.
- Aprendizaje por refuerzo: el sistema aprende a realizar una tarea recibiendo una recompensa o feedback cada vez que la finaliza, indicándole lo bien o mal que lo ha hecho. Esta técnica es útil, por ejemplo, para que las máquinas aprendan a jugar a videojuegos.
2.2. Clasificación en base a la duración del aprendizaje¶
Algunos sistemas se desarrollan o entrenan durante un tiempo y, cuando están listos, finaliza su entrenamiento y se ponen en producción para resolver el problema para el que se diseñaron. Por ejemplo, un sistema que detecte tumores en imágenes, una vez que alcanza un grado de exactitud (accuracy) satisfactorio, se puede dejar de entrenar y ponerlo en funcionamiento para ayudar al equipo de oncología de un hospital. Esto es lo que se conoce como batch learning (aprendizaje por lotes). Tiene el inconveniente de que, si en un futuro aparecieran nuevos tipos de tumores en las imágenes, necesitaríamos volver a entrenar de nuevo al modelo.
Sin embargo, en otros casos el sistema necesita estar constantemente aprendiendo, con cada nuevo dato de entrada. Por ejemplo, un sistema que detecte mensajes malsonantes o hirientes tiene que poder captar nuevas tendencias en esos mensajes, y estar alerta a la frecuencia con que se producen para etiquetarlos como malos. Esto se conoce como online learning (aprendizaje en línea) y permite al sistema estar constantemente aprendiendo y emitiendo respuestas. En estos casos el aprendizaje se hace por muestras o pequeños lotes de datos, de modo que cada paso en el aprendizaje es más rápido que en el caso del batch learning.
2.3. Clasificación en base al modo de generalización¶
Cuando desarrollamos un modelo de machine learning nos interesa no sólo que funcione bien con los datos que proporcionamos en el entrenamiento sino que (y sobre todo) funcione bien con nuevos datos que puedan llegar en un futuro. Es lo que se denomina inferencia o generalización: a partir del modelo entrenado, los nuevos datos que lleguen deben seguir produciendo respuestas satisfactorias.
En algunos sistemas esta generalización se realiza por comparación o similitud entre casos. Por ejemplo, un sistema que descarte mensajes hirientes puede basarse en descartarlos por palabras similares con otros mensajes hirientes que ya ha aprendido. Es lo que se llama aprendizaje basado en instancias, porque se cotejan nuevas instancias con otras que ya se han examinado.
Sin embargo, en otros casos puede interesar definir un patrón o fórmula que automáticamente emita una respuesta. Por ejemplo, dados los datos de un piso (habitaciones, año de construcción, estado general...), ¿a qué precio se podría vender? Podemos establecer una correlación entre estos datos y el precio de venta, para pisos que ya se hayan vendido, y elaborar así un modelo que, a partir de los datos de un nuevo piso, establezca qué precio le correspondería. En estos casos hablamos de un aprendizaje basado en modelo, ya que construimos un modelo que nos ayuda a establecer las conexiones entre los diferentes parámetros de entrada.
3. Machine learning y datos¶
En todo modelo basado en machine learning hará falta una (gran) cantidad de datos con los que entrenar o ajustar el modelo, para que sea capaz de inferir nuevos resultados para nuevos datos de entrada. Es muy habitual que esa cantidad de datos se divida en dos grupos: conjunto de entrenamiento y conjunto de test.
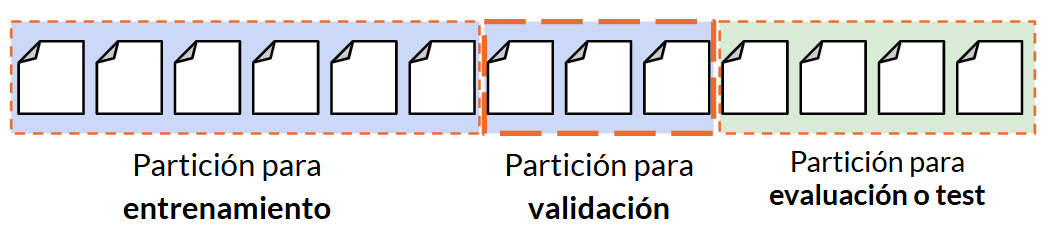
El conjunto de entrenamiento suele ser una parte grande de los datos disponibles (en torno al 80% habitualmente), y constituirán la fuente con la que el modelo va a entrenarse y a perfeccionar su funcionamiento. El conjunto de test (el otro 20% restante, normalmente) se reserva para que, una vez el modelo se haya entrenado, comprobar con otros datos que aún no ha visto cómo de bueno es en sus predicciones. Es lo que se conoce como inferencia.
En algunos sistemas, como por ejemplo aquellos basados en redes neuronales, la fase de inferencia se puede dividir en dos etapas:
- La etapa de validación consiste en aislar un conjunto de datos de muestra con los que se entrena al sistema y no utilizarlos en la fase de entrenamiento para, cuando el sistema ya está entrenado, usarlos para ver lo bien o mal ajustado que está. Por ejemplo, en un modelo para identificar objetos en imágenes, es posible que el sistema sólo haya aprendido a memorizar las miles de imágenes de entrenamiento que se le han enseñado (fenómeno conocido como overfitting, o sobre-ajuste). El conjunto de validación nos ayuda a determinar si sólo ha estado memorizando, o si realmente ha aprendido a identificar objetos. En el primer caso, se puede volver a la etapa de entrenamiento y reajustar algunos parámetros para ver si mejora.
- La etapa de test consiste en tomar otro conjunto de datos distinto al de entrenamiento (y validación) y pasarlos al sistema para saber si también se comporta correctamente con esos datos externos.
Gráficamente lo podríamos ver así:
Nota
El subconjunto de validación sólo será necesario en aquellos modelos donde haya que reajustar los parámetros hasta conseguir el comportamiento deseado. Para redes sencillas o donde se consigan fácilmente buenos resultados no será necesaria esta división.
3.1. Limitaciones en los datos¶
Dado que los datos son un aspecto esencial en un proceso de machine learning, tenemos que ser conscientes de qué limitaciones ocasiona no disponer del conjunto de datos adecuado. Estas limitaciones pueden ser de distintos tipos:
- Cantidad de datos insuficientes. Si no disponemos de la cantidad suficiente de datos para hacer un entrenamiento del modelo en condiciones, la exactitud final alcanzada tampoco será satisfactoria
- Datos no representativos. Los datos de entrenamiento de que se disponga deben abarcar todos los posibles casos que queremos estudiar. Así, por ejemplo, si desarrollamos un sistema que clasifique imágenes de animales pero no tenemos imágenes disponibles de un determinado animal, el sistema no va a poder identificarlo.
- Datos de baja calidad. Si los datos de que disponemos están llenos de errores, campos vacíos, etc, será difícil entrenar un modelo que aprenda a inferir resultados correctos.
- Datos irrelevantes. Asimismo, es importante que la información que proporcionemos al modelo sea relevante para producir el resultado deseado. Por ejemplo, en un modelo que prediga el valor de venta de un coche usado, probablemente el color del coche no sea un dato relevante para establecer dicho precio.
Para paliar estas limitaciones entran en juego diferentes estrategias del campo del data science. En concreto de la limpieza de datos (data cleaning), para asegurar datos correctamente formateados y de calidad, y el data engineering, para determinar cuáles son los datos relevantes para nuestro estudio. Puedes obtener más información sobre estos aspectos en este documento.
4. Etapas del machine learning¶
En todo proceso de machine learning podemos identificar estas etapas:
- Recolección de datos. Como hemos comentado anteriormente, los datos son un elemento fundamental en todo proceso de aprendizaje automático.
- Preparación de datos. Para que los datos sean útiles para el modelo que queremos desarrollar deben estar correctamente preparados. Para ello, deben contener información completa y relevante para la tarea a desarrollar. En esta etapa entrarán en juego tareas como la limpieza de datos, análisis exploratorio, etc, que hemos comentado en el apartado anterior.
- Elegir el modelo. Debemos elegir el modelo más adecuado para la tarea a desarrollar. Si estamos realizando una tarea de regresión, por ejemplo, podremos elegir entre una regresión lineal, un árbol de decisión, etc.
- Entrenar el modelo. Una vez elegido el modelo y preparados los datos, entrenaremos el modelo con los datos (con el conjunto de entrenamiento elegido).
- Evaluación del modelo. Tras el entrenamiento evaluamos lo bien o mal que el modelo ha entrenado, midiendo los errores que comete o la exactitud que alcanza. En este paso suele ser habitual emplear un conjunto de datos adicional (conjunto de validación o de test) para medir el grado de inferencia del modelo.
- Ajuste de hiperparámetros. Si la etapa de validación anterior no es satisfactoria, se deben reajustar ciertos parámetros del modelo para intentar mejorar los resultados. Esto nos llevaría de vuelta al paso 4 para probar un nuevo entrenamiento y re-evaluar.
- Predicción. Con el modelo ya ajustado y entrenado, podemos ponerlo en funcionamiento para predecir nuevos datos en base a nuevas entradas que reciba, pudiendo utilizar en este paso el conjunto de datos de test como prueba.