Despliegue de modelos propios en Azure¶
En este documento explicaremos cómo utilizar la nube de Azure para desarrollar nuestros propios modelos, a través del recurso Azure Machine Learning.
Advertencia
El uso de Azure Machine Learning y el despliegue de modelos propios conlleva unos gastos asociados, por almacenamiento de los modelos y de los datos de entrenamiento, entre otras cosas, y por la puesta en marcha de las máquinas sobre las que se ejecutarán. Revisa periódicamente tu saldo en cuenta y elimina o desactiva los recursos que hayas creado, en el caso de que consuman demasiado.
1. Azure Machine Learning y área de trabajo¶
Lo primero que debemos hacer es acceder al portal con nuestro usuario (ya se explicó cómo aquí), y buscar el recurso Azure Machine Learning en el buscador superior, si no lo tenemos disponible en nuestros recursos más utilizados.

Si nos da a elegir, elegiremos crear un nuevo espacio o área de trabajo (workspace) para nuestro proyecto. En el formulario para definir las propiedades del recurso, seleccionamos como es habitual el grupo de recursos al que lo asignaremos (podemos crear uno nuevo para el recurso, si queremos) y le pondremos un nombre. El resto de campos se generan automáticamente, y hacen referencia al almacén de datos para el espacio de trabajo (por defecto se crea uno con el nombre auto-asignado), el almacén de claves (key vault, útil para no tener que poner las claves a mano en el código, y recuperarlas de dicho almacén), y el sistema de monitoreo (insights), para detectar y mostrar posibles fallos o caídas del espacio de trabajo, cuellos de botella, etc.
Después, pulsamos en el paso Siguiente hasta que se cree el workspace.
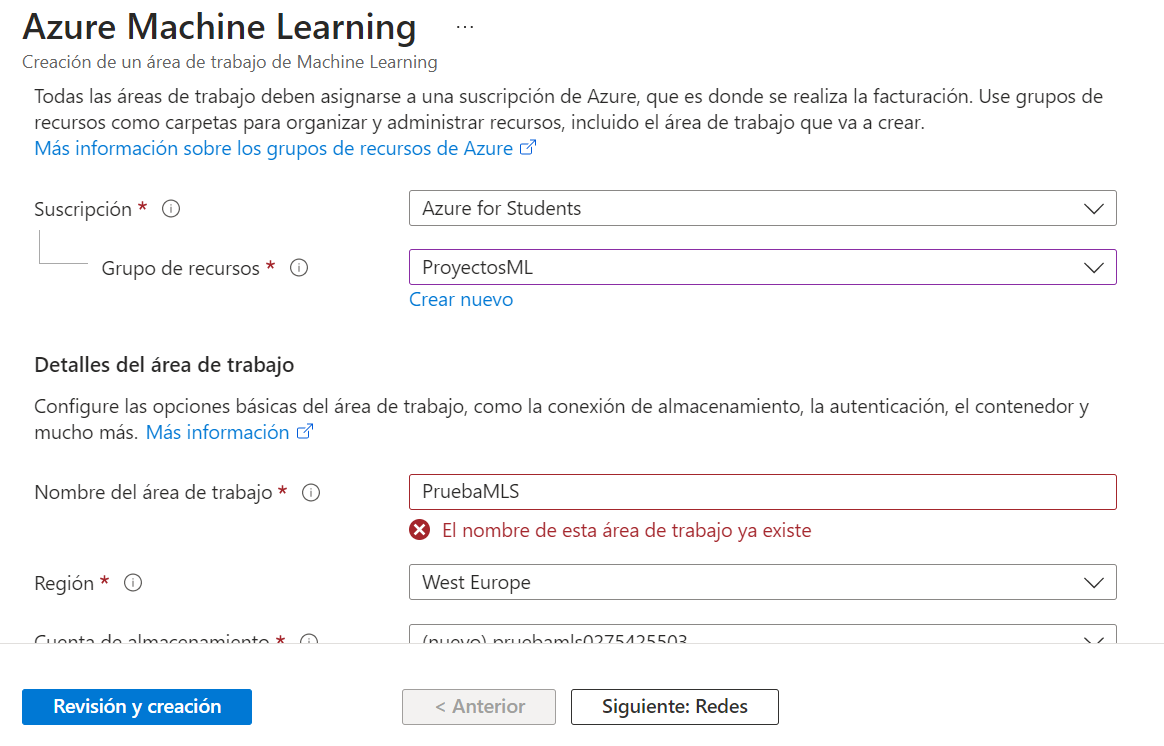
Si vamos a la página principal del portal de Azure y buscamos todos nuestros recursos podremos ver el workspace creado, junto con algunos recursos más vinculados, para almacenar las claves, los datos, etc.

En la propia página del Workspace tenemos información importante en cuanto a los elementos que se han creado: código del almacén de claves (key vault), del sistema de almacenamiento, etc. También en el menú izquierdo tenemos opciones para gestionar el control de acceso, ver las cuotas de consumo de recursos, etc.
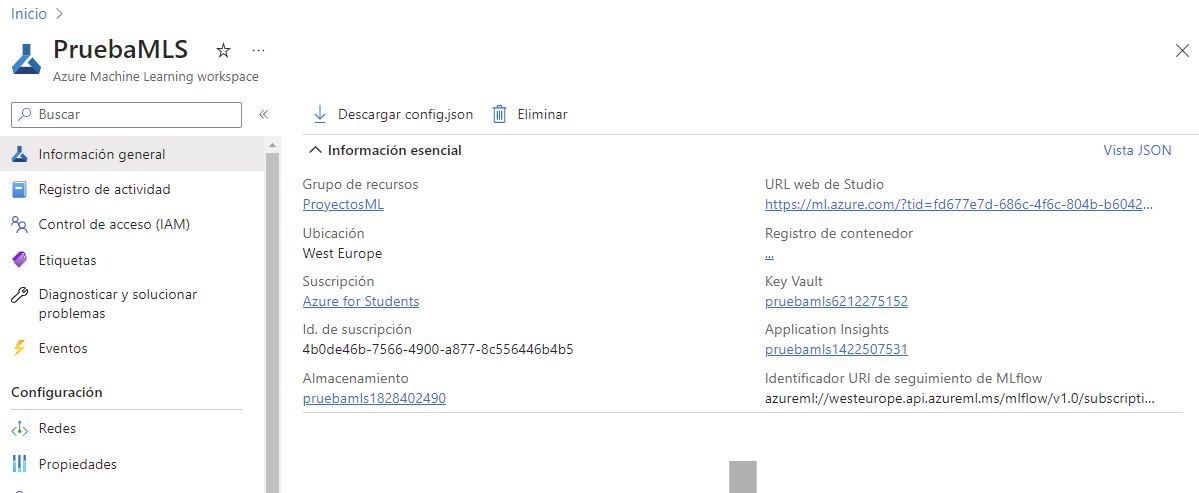
Para las pruebas que haremos a continuación, vamos a crear un área de trabajo Azure Machine Learning llamada PruebasMLS. Vayamos ahora al área de trabajo que hemos creado, y pulsemos en el botón Iniciar Studio de la misma.
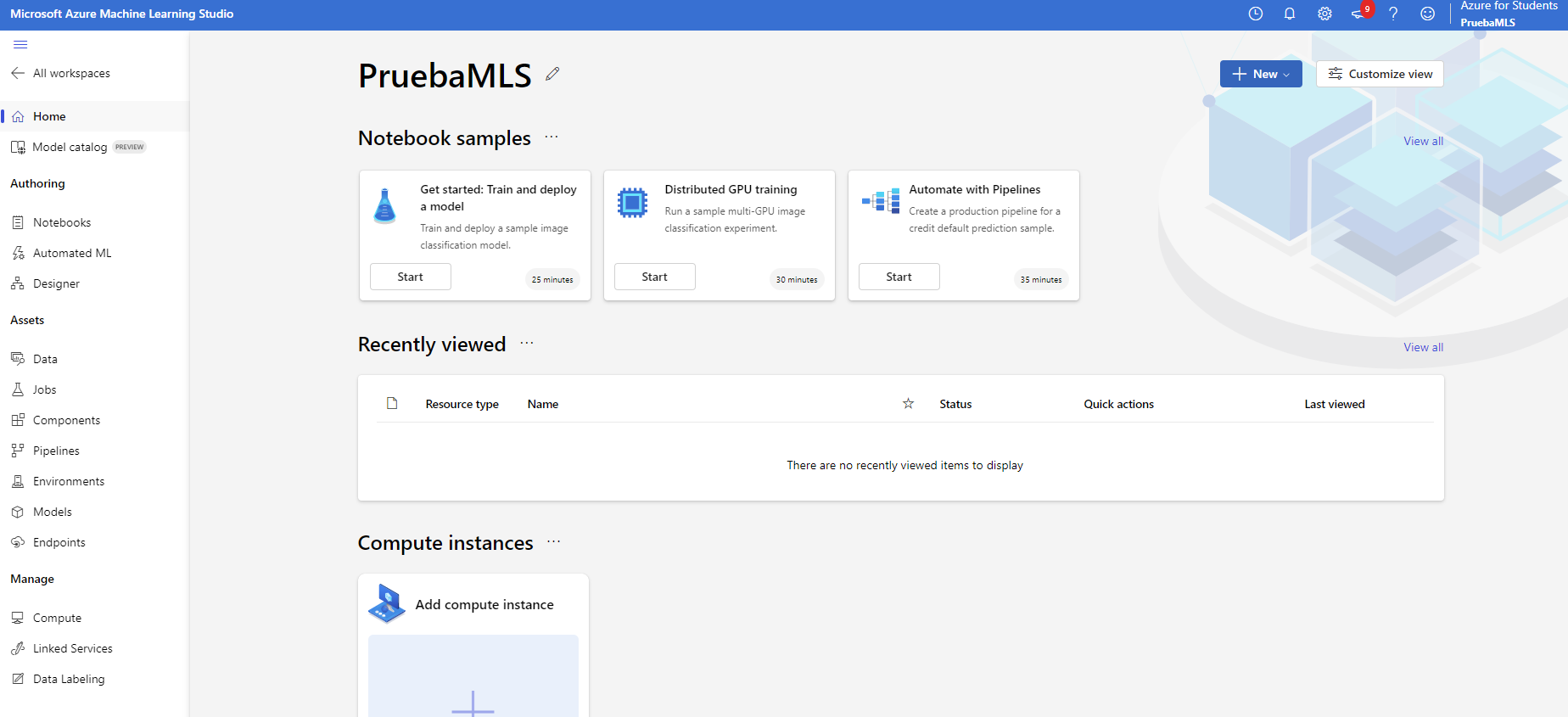
En el menú izquierdo vemos distintas opciones. Comentamos a continuación algunas de ellas:
- Podemos ver que nos ofrecen la posibilidad de crear cuadernos (Notebooks), al estilo de los que hay en Google Colab o Jupyter Notebook.
- También nos ofrecen la opción de lanzar un proyecto ML automatizado con Automated ML, lo que permite definir modelos de IA en pocos minutos, con pocas nociones de programación. Basta con proporcionar el dataset, indicar las etiquetas o columnas relevantes y el sistema se entrena y despliega.
- Por otra parte, también podemos hacer uso de un diseñador (Designer), para diseñar nuestros modelos de forma visual, al estilo de otras herramientas parecidas como KNIME.
- Además de todo lo anterior, en la sección inferior disponemos de otras opciones para, de forma más manual, crear nuestro entorno de trabajo y subir nuestras propias aplicaciones.
1.1. Instancias de cómputo¶
Para que nuestro proyecto pueda ejecutarse necesitamos asociarlo a una instancia de cómputo (compute instance). Podemos ir a la sección Compute o Proceso del menú izquierdo de Azure Machine Learning Studio y crear una instancia de cómputo acorde a nuestras necesidades:
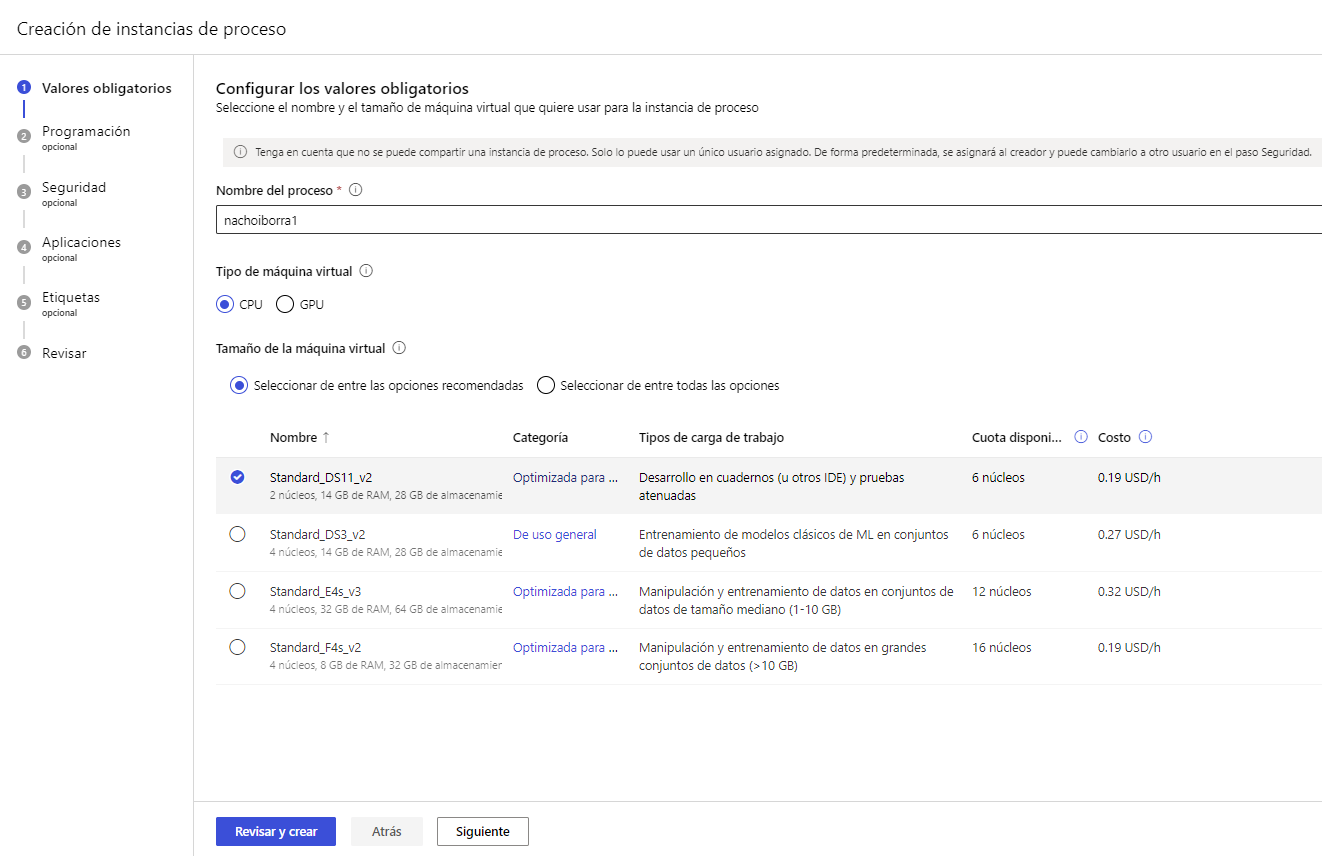
Podemos también indicar un tiempo de apagado por inactividad (recomendable para no dejar por olvido la instancia encendida y descontando saldo):
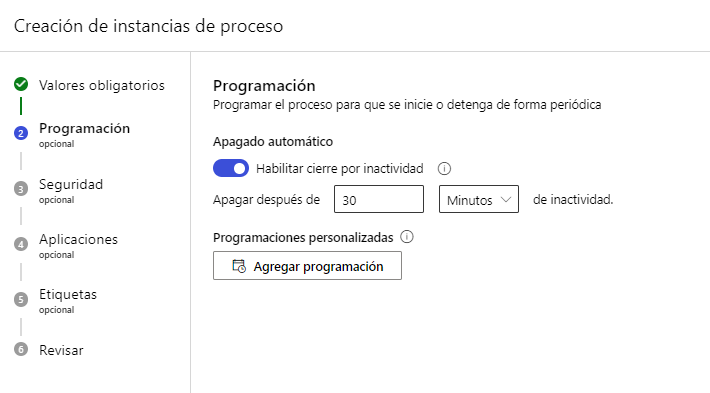
Otras opciones adicionales incluyen habilitar acceso por SSH, definir redes virtuales... no entraremos en esos detalles aquí. Después de finalizar los demás pasos del asistente podremos ver nuestra instancia de cómputo en la página principal de la sección Compute (o Proceso). Es IMPORTANTE ponerlas en marcha cuando vayamos a probar algún modelo que hagamos, y detenerlas después para que no siga descontando saldo.
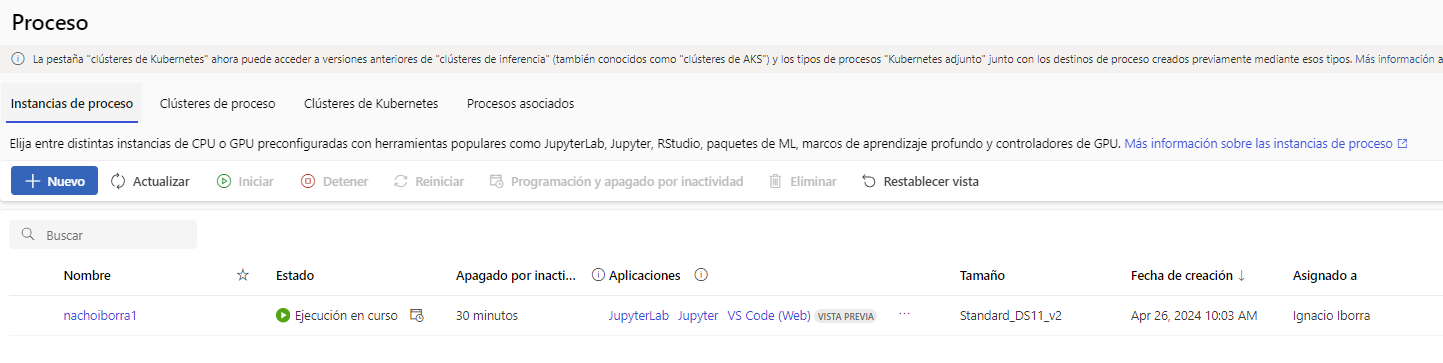
Por tanto, cada proyecto de Machine Learning que creemos irá en su área de trabajo específica, con su instancia de cómputo específica.
Nota
Como se puede ver en las imágenes anteriores, el uso de instancias de cómputo no es gratuito. Dependiendo de nuestras necesidades, elegiremos una u otra y se cargará en nuestra cuenta la tarifa por hora indicada. En nuestro caso, para las pruebas que vamos a hacer aquí, nos puede bastar con una de propósito general como la que hay seleccionada en las imágenes anteriores.
2. Edición de cuadernos online y uso de ML automático¶
Como hemos comentado, desde Azure Machine Learning Studio podemos gestionar cuadernos online, al estilo de otras plataformas como Google Colab. Deberemos crear el recurso Machine Learning correspondiente (o usar uno que ya tengamos), junto con su correspondiente instancia de cómputo, siguiendo los pasos anteriores. Abrimos Studio y accedemos al menú Notebooks de la parte izquierda. Después, podemos crear uno o varios Notebooks; para poderlos ejecutar debemos asociar una instancia de cómputo en la propia página del cuaderno. También debemos asociar un kernel desde el desplegable derecho.
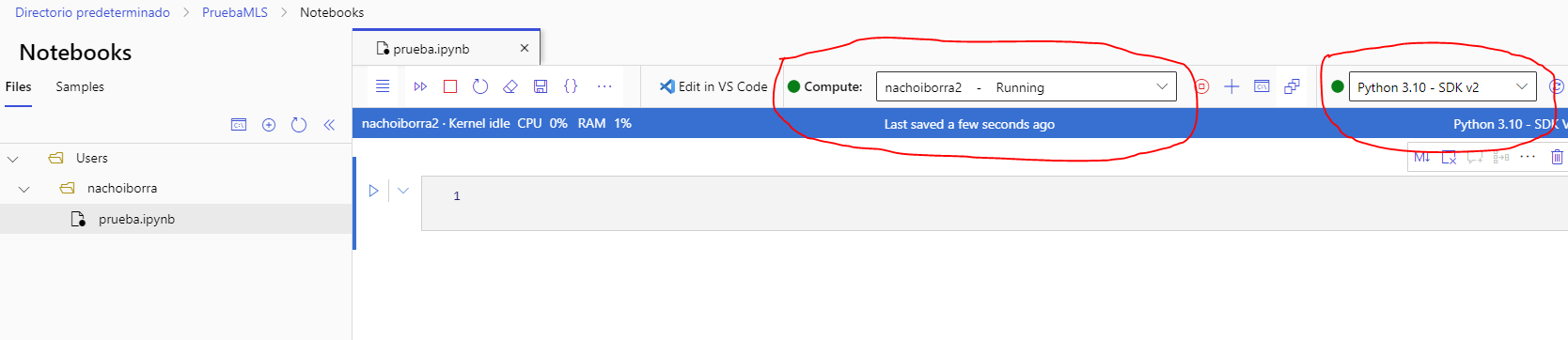
Respecto al kernel a elegir, depende en gran parte de lo que vayamos a hacer. Si vamos a trabajar con librerías de Azure Machine Learning, podemos elegir un kernel de Azure ML para que las tenga ya preinstaladas. Si vamos a trabajar con PyTorch o TensorFlow, también tenemos un kernel específico para eso. En otros casos, podemos usar un kernel normal con el SDK correspondiente. De todas formas, podemos instalar en cualquiera de los kernels las librerías que necesitemos.
Desde el panel izquierdo podemos crear nuevos cuadernos, o subir archivos, con el botón de +. El funcionamiento de los cuadernos es similar al de otras herramientas como Google Colab: podemos intercalar fragmentos de código y texto, y ejecutar cada fragmento por separado.
Tenemos la opción de crear un modelo usando un cuaderno y publicarlo con un endpoint para acceder a él. En la sección Muestras o Samples del menú izquierdo del Notebook tenemos unos cuantos cuadernos de muestra que podemos clonar (con clic derecho) en nuestro espacio de trabajo y seguirlos paso a paso para desplegarlos y probarlos.
2.1. Ejemplo de cuaderno¶
Para ver un pequeño ejemplo, utilizaremos este dataset disponible en este link de Kaggle. Contiene precios de ventas de coches usados en una empresa de Barcelona.
Usaremos este cuaderno, que podéis subir directamente a vuestro espacio de cuadernos de Azure (sube el archivo del cuaderno que hay en el ZIP, junto con el CSV anterior). Iniciamos nuestra instancia de cómputo, y elegimos un kernel de tipo Azure ML.
El cuaderno en cuestión importa las librerías necesarias (incluyendo algunas del ecosistema Azure para machine learning), carga el CSV en Azure e inicia un proceso de entrenamiento automatizado para regresión lineal, con el fin de predecir el precio de venta de un coche usado dados los parámetros de entrada. Deberemos ajustar algunos datos en el código antes de ejecutar ciertas celdas, como el nombre de la instancia de cómputo donde ejecutar:
automl_config = AutoMLConfig(task='regression',
debug_log='automl_errors.log',
training_data=dataset,
label_column_name="price (eur)",
compute_target="nachoiborra1", # CAMBIAR
**automl_settings)
Durante la ejecución del proceso de entrenamiento, en la sección de Trabajos(Jobs) del menú izquierdo veremos la progresión.
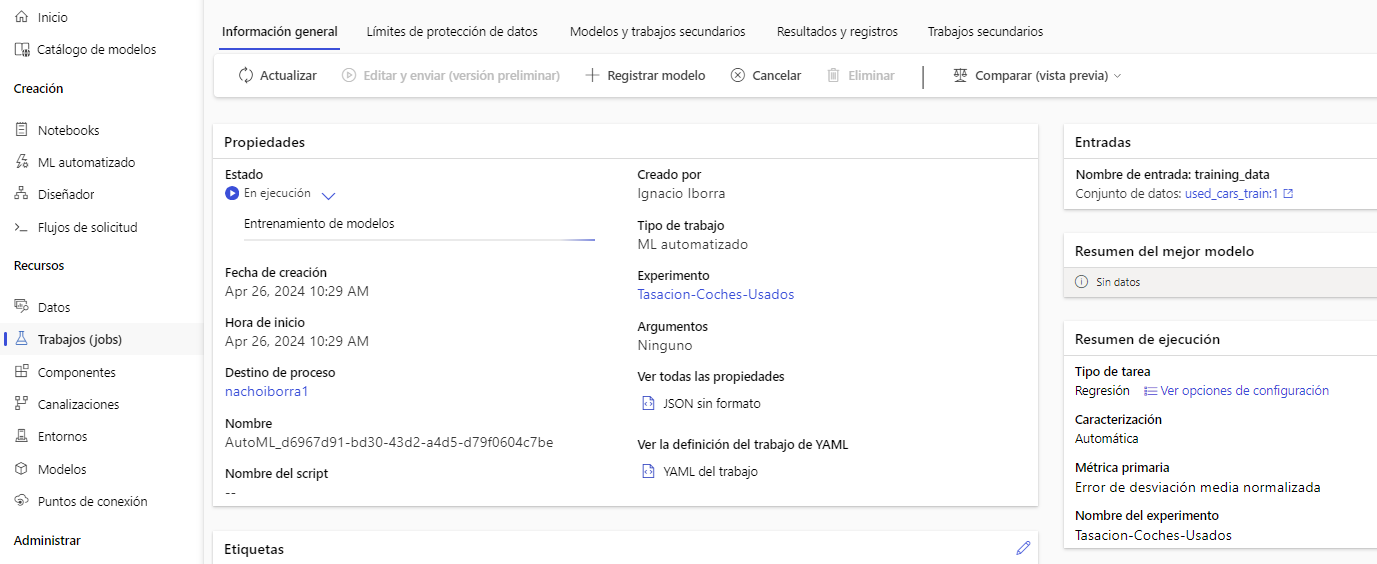
Al finalizar, en la sección de Modelos podemos ver el detalle del entrenamiento y resultado (Ver explicación o View explanation)
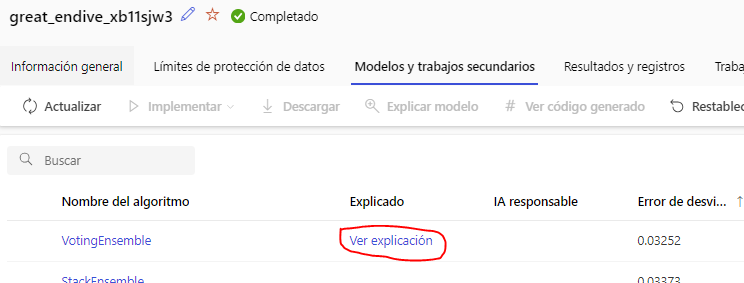
Entre otras cosas, podemos ver cuáles son los X parámetros más relevantes para el entrenamiento, y tenemos un botón Implementar o Deploy para desplegar el modelo y poder acceder a él vía API REST.
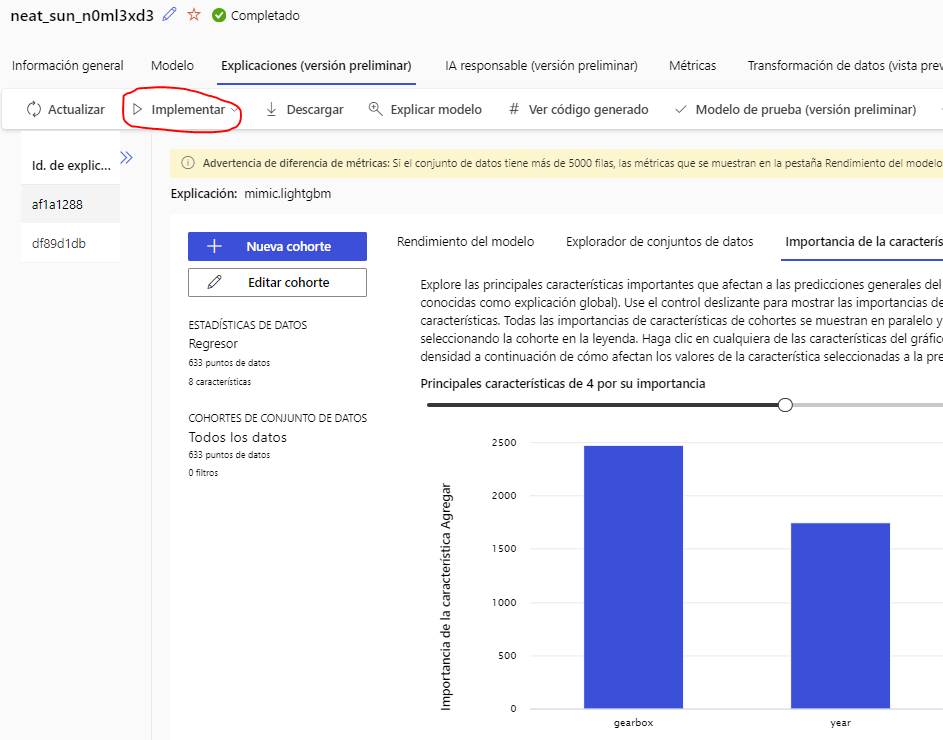
Podemos desplegarlo como un modelo en tiempo real o como un servicio (elegiremos esto último, en este caso). Le tendremos que poner un nombre y elegir el tipo de cómputo que usaremos (en nuestro caso, el propio servicio contenedor de Azure, ya que no necesitamos ningún cluster). También podemos habilitar la autenticación para que sólo las personas autorizadas puedan acceder a nuestro servicio.
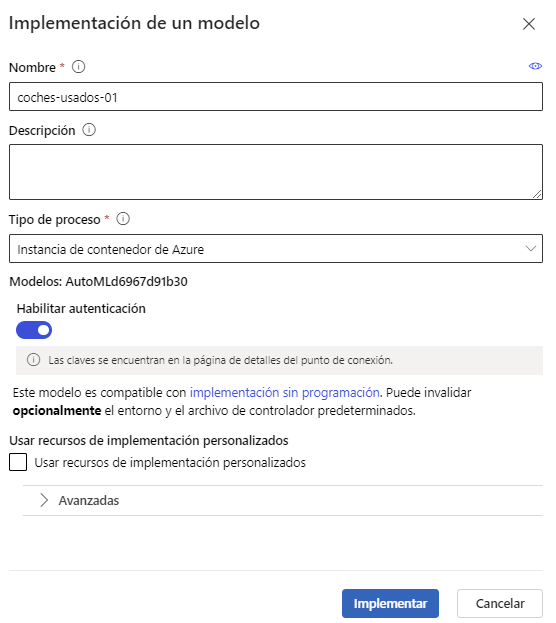
Después de unos minutos, podemos ir al menú Puntos de conexión o Endpoints de la sección izquierda y veremos el endpoint creado para nuestro modelo. En la pestaña Consumir o Consume tenemos ejemplos de cómo acceder a él en distintos lenguajes, que podemos utilizar directamente (bien desde otro cuaderno, o desde nuestro ordenador local).
Nota
Hasta que el despliegue se complete de forma efectiva, el estado de nuestro endpoint puede que sea Unhealthy, lo que significa que todavía no puede ser accedido desde fuera.
Ejercicio 1
Sigue los pasos dados hasta aquí y accede a tu propio modelo (o al que se te proporciona como ejemplo en el ZIP anterior), para inferir el precio de un vehículo usado con las siguientes características:
- Marca: SEAT
- Modelo: Ibiza
- Motor: 1.2 TSI 90cv Style
- Año: 2018
- Kilometraje: 54000
- Combustible: Gasolina
- Caja de cambios: Manual
- Ubicación: Gavá
2.2. Ejemplo de asistente de ML automático¶
Vamos ahora a probar el asistente para crear un proyecto de machine learning automático. Vamos a la sección Automated ML del menú izquierdo de Studio, y emplearemos este dataset para predecir si una persona tendrá o no problemas cardíacos con sus datos de salud.
En la sección de Automated ML elegimos crear uno nuevo (New Automated ML Job). Tendremos que elegir el nombre de la tarea y una breve descripción(por ejemplo, AutoML-Salud).
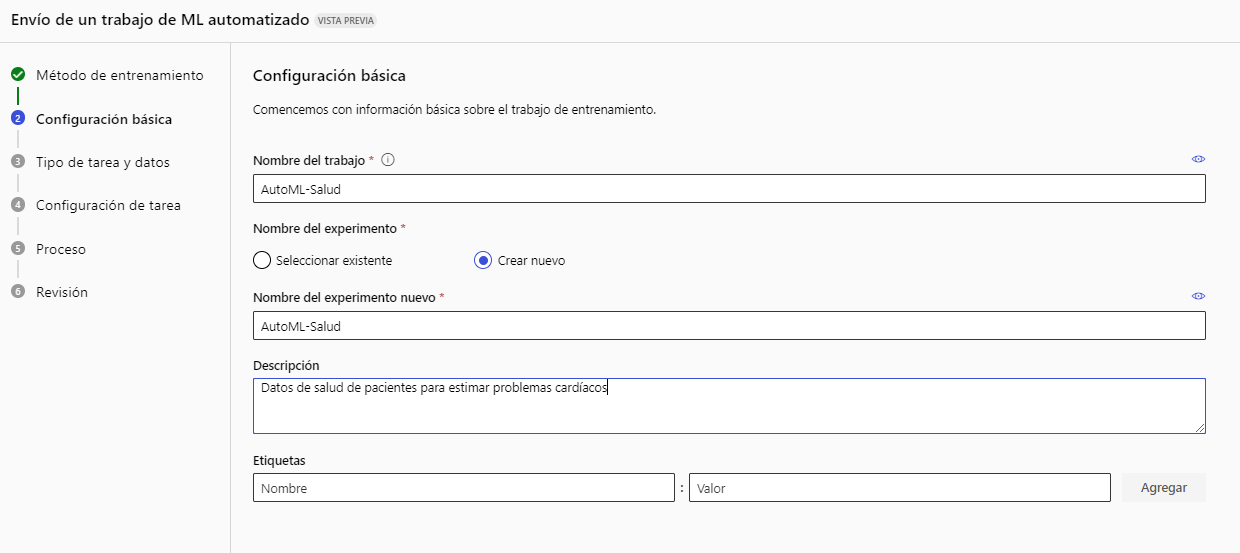
A continuación elegimos el tipo de trabajo que vamos a hacer (en nuestro caso, Clasificación) y creamos un nuevo origen de datos pulsando en el botón de Crear.
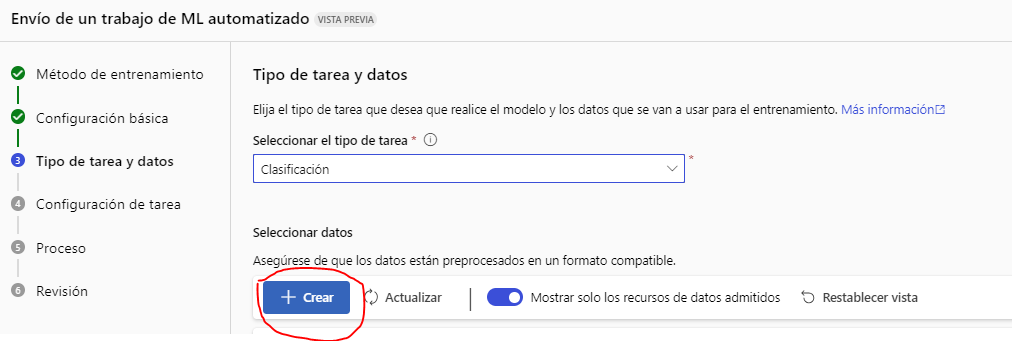
Elegimos un nombre para el origen de datos (por ejemplo, salud):
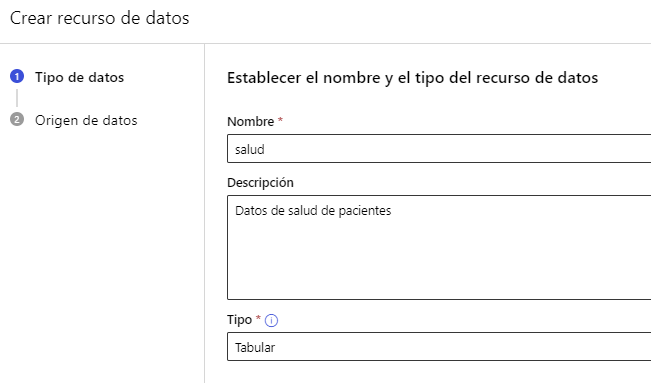
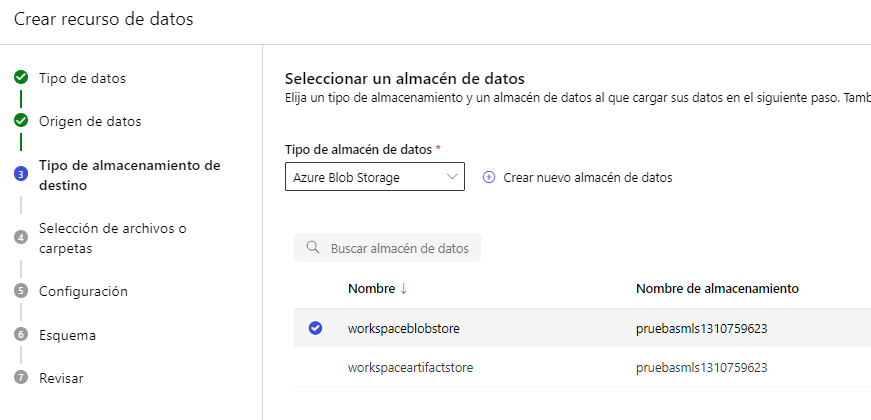
En el paso siguiente elegimos subir un fichero local, y luego elegimos el almacenamiento donde lo ubicaremos (el que viene por defecto Azure Blob Storage puede ser adecuado):
Elegimos el fichero CSV local para subir:
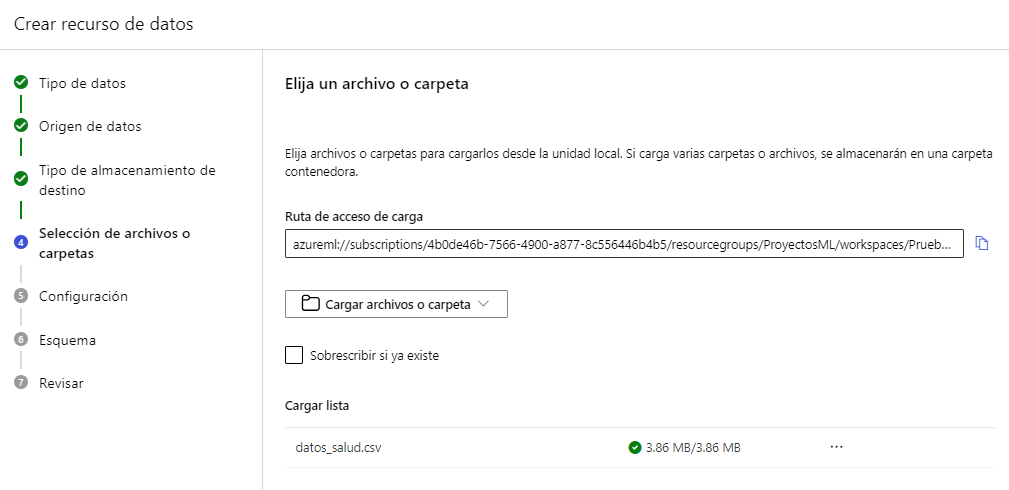
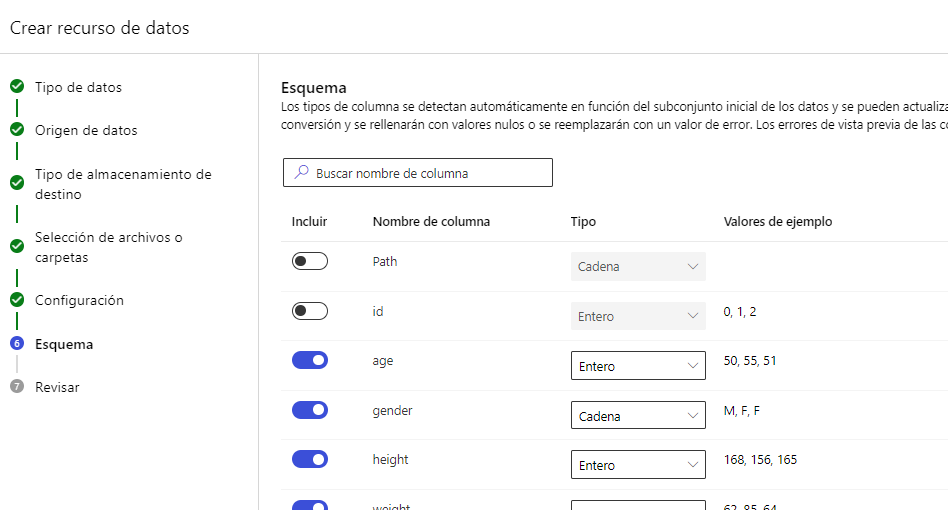
En este siguiente apartado tendremos una vista previa del CSV, y podemos configurar algunas cosas si no son correctas, como el delimitador de columnas. Si todo es correcto podemos pasar al siguiente paso, donde definiremos el Esquema. Podemos desactivar las columnas que no consideremos importantes, si es el caso. En nuestro caso desactivaremos la columna id:
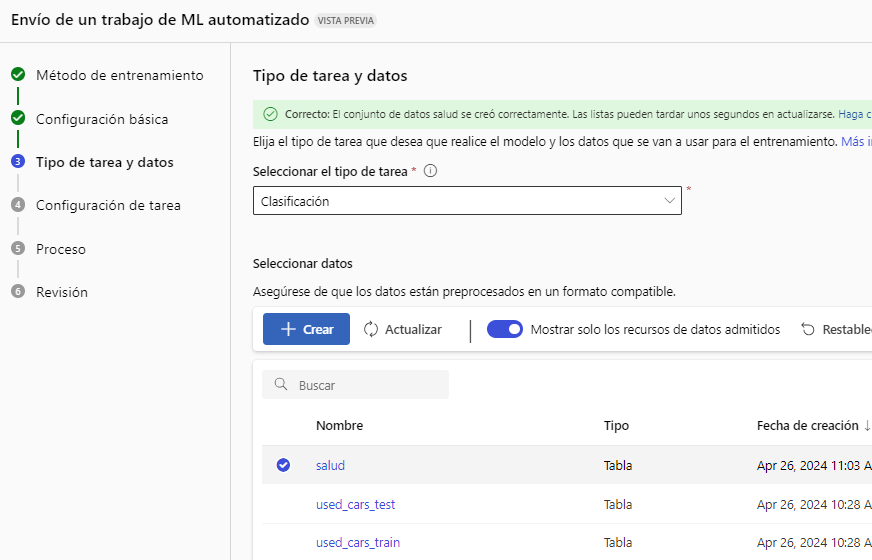
Ya tenemos configurado el origen de datos, terminamos con este sub-asistente y elegimos los datos creados en el listado:
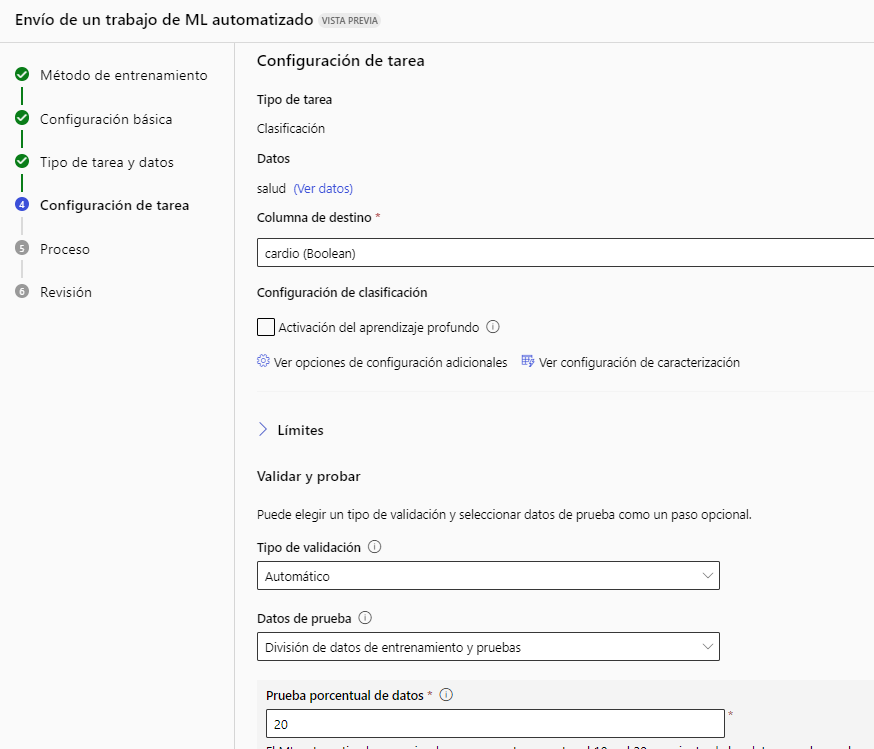
Ahora vamos a configurar la tarea de machine learning. Elegimos la columna objetivo (cardio), el tipo de validación que queramos y la división en conjunto de entrenamiento y test deseada. En cuanto a la validación, tenemos varias opciones, como la validación automática, o la K-fold cross validation, donde podemos elegir el número de validaciones (por ejemplo, 2).
Después elegimos la instancia de ejecución, que puede ser la que ya hemos definido en etapas anteriores:
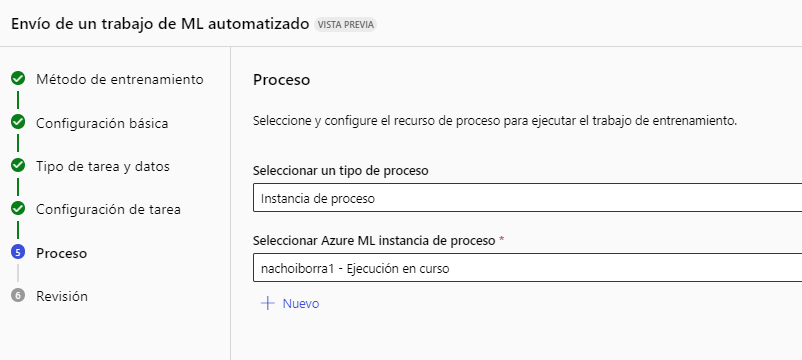
Finalmente revisamos los datos y enviamos la tarea a ejecución. Igual que ocurre con los modelos probados en Notebooks, en la sección izquierda Trabajos(Jobs) podemos ver el listado y su estado de ejecución:
Cuando finalice el proceso, de nuevo en la pestaña de Modelos podemos ver la información del modelo seleccionado, desde su enlace View explanation. Por ejemplo, en la pestaña Model performance o Rendimiento del modelo podemos ver los datos del entrenamiento, con la exactitud final alcanzada y otros datos.
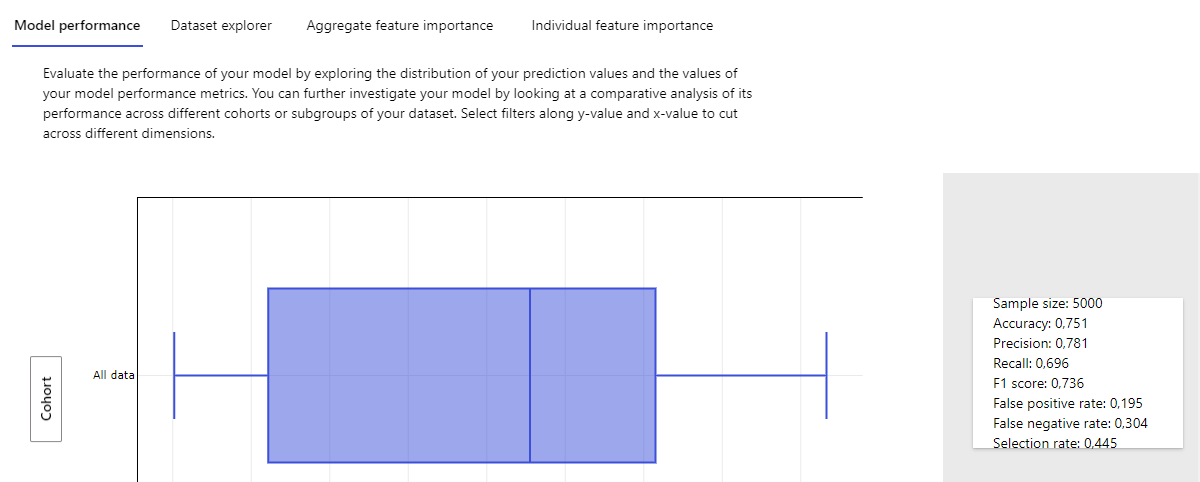
En la sección Overview de la tarea veremos un resumen general del proceso. En la parte derecha veremos el modelo que ha sido elegido y la métrica conseguida. Desde ese panel también podemos ver las demás métricas que se han hecho
Finalmente desde la pestaña Models haremos Deploy para desplegarlo en un endpoint, como en el caso anterior. Le damos un nombre, un tipo de cómputo y habilitamos la autenticación. Pasados unos minutos, tendremos el endpoint disponible en la sección Endpoints del menú izquierdo, junto con el código para acceder en su pestaña Compute, como hemos visto para el ejemplo del cuaderno anterior.
Ejercicio 2
Completa los pasos anteriores para desplegar tu propio modelo para clasificación, y pruébalo con los siguientes datos de entrada:
- Edad: 45
- Género: M
- Altura: 180
- Peso: 90
- Presión alta: 110
- Presión baja: 80
- Colesterol: por encima de lo normal
- Glucosa: normal
- Tabaco: no
- Alcohol: no
- Activo: no
2.3. Despliegue y contenedores¶
Cuando desplegamos (Deploy) uno de estos modelos, le asociamos un contenedor. En estos ejemplos hemos usado un contenedor básico de Azure, aunque tenemos la opción de usar un cluster de Kubernetes también, para tener más capacidad de cómputo. En cualquier caso, ese contenedor se queda en ejecución (y facturando en nuestra cuenta).
Desde el portal de Azure podemos visualizar Todos los recursos (podemos buscar esta opción en el buscador superior si no la tenemos a mano en la página de inicio del portal):
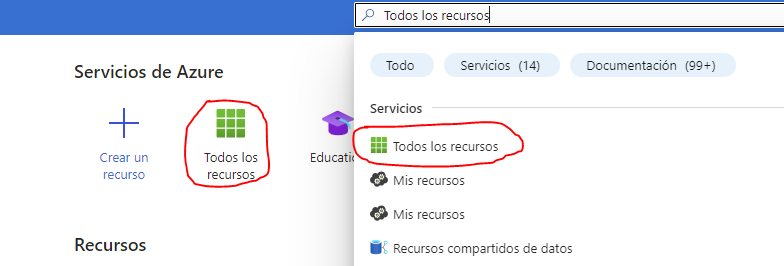
Desde esta opción podemos identificar los contenedores que hemos definido hasta ahora en cada grupo de recursos:
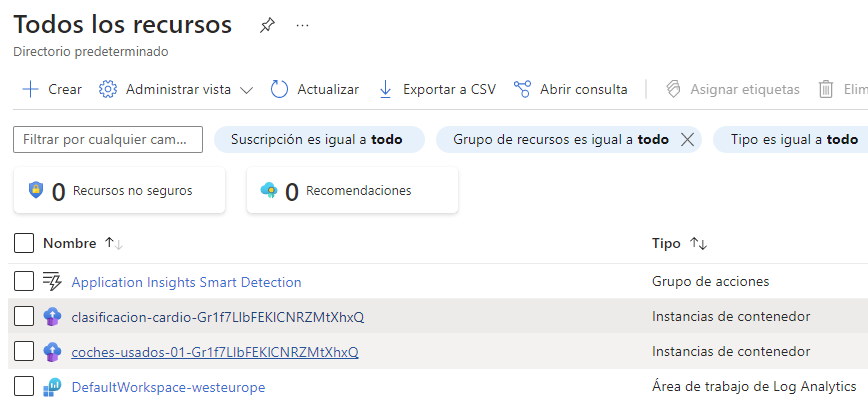
Podemos hacer clic en cualquier contenedor y cambiar su estado (detenerlo o reiniciarlo), dependiendo de cuándo queramos probar o dejar en ejecución cada modelo.
Ejercicio 3
Descarga este ejercicio paso a paso sobre Azure Automated ML y síguelo para construir un modelo de regresión que prediga los alquileres de una empresa de alquiler de bicicletas. Se proporciona el archivo CSV también, aunque en el enunciado indica que se facilite la URL pública donde se encuentra alojado. Los pasos 1 (Create an Azure Machine Learning workspace) y 2 (Create compute) puedes omitirlos, y utilizar el workspace e instancia de cómputo creados para los ejercicios previos. Continúa en el paso 3 (Create a data asset). En el último paso (Clean-up), no es necesario que borres la instancia de cómputo, si la estás usando en otros ejemplos. Pero recuerda detenerla, junto con los contenedores que puedas tener activos, para no agotar tu saldo.
3. Otras opciones de despliegue¶
Además de poder usar los cuadernos y el machine learning automatizado de Azure (y todos los servicios pre-entrenados de Azure Cognitive Services explicados en este documento), existen algunas alternativas más para desplegar modelos de IA en la nube de Azure. Aquí veremos, más de pasada, algunas de ellas.
3.1. Uso del diseñador (Designer)¶
El diseñador (Designer) del menú izquierdo de Azure Machine Learning Studio nos permite desarrollar un modelo en nuestra área de trabajo a través de una herramienta visual, sin necesidad de programar. Cada proyecto que creamos se denomina pipeline
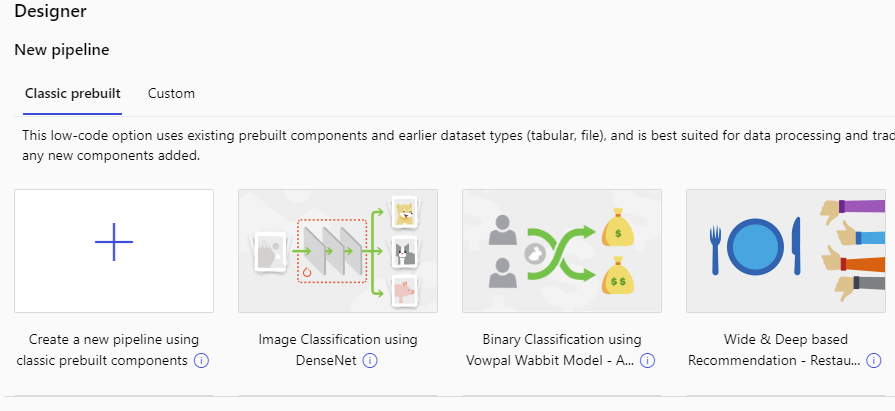
Como vemos, tenemos ciertos diseños prefabricados para algunas tareas habituales (clasificación de imágenes, sistemas de recomendación), y podemos crear un nuevo pipeline desde cero. Al crearlo podemos editar su nombre.
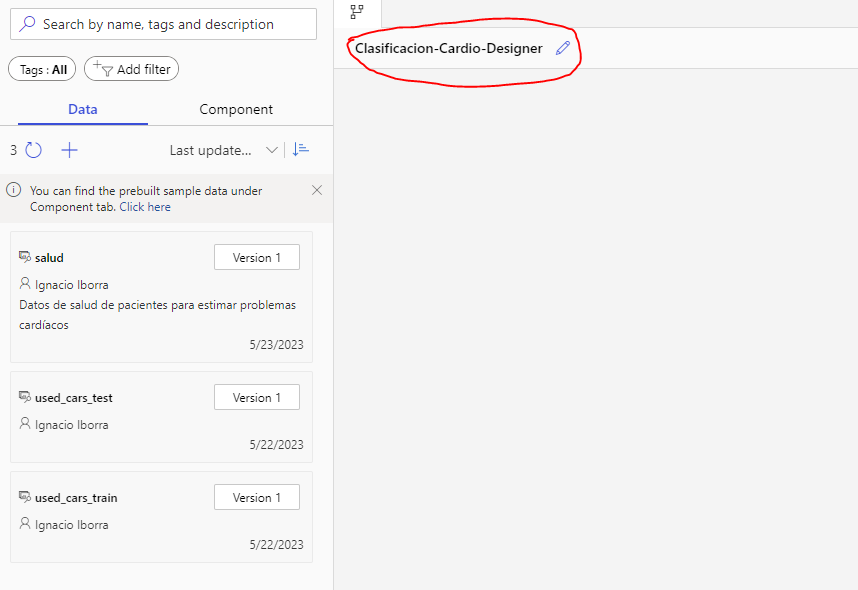
Cada pipeline comienza especificando los datos con que vamos a trabajar. En la pestaña izquierda Data proporcionaremos los datos que usaremos en nuestro modelo, y en la pestaña Components tenemos los componentes visuales que podemos utilizar para procesar los datos y construir un modelo de machine/deep learning. Para los datos, podemos usar algún data asset ya creado (aparecerán en el listado izquierdo), o crear uno nuevo de forma similar a como lo hemos hecho antes para el modelo de ML automatizado: elegir el tipo de recurso (fichero local, URL, etc), sistema de almacenamiento, etc.
Lo primero que tendremos que hacer será arrastrar de ese panel izquierdo el data asset que queramos a la zona de trabajo. Con clic derecho podemos elegir Preview data para previsualizarlo.
A continuación del nodo de datos podemos ir enlazando otros componentes de la sección Components. Existen diferentes tipos; resaltamos a continuación algunas de las categorías más habituales:
- Data Transformation: para transformar los datos con que se trabaja. Disponemos de componentes para añadir filas/columnas, eliminar duplicados, limpiar valores nulos, filtrar columnas...
- Machine Learning Algorithms: para aplicar diferentes algoritmos de machine learning, tales como regresiones lineales, árboles de decisión, etc.
- Data Input and Output: para aplicar diferentes formatos de entrada o salida, como por ejemplo exportar los datos a un formato específico, o leerlos desde un formato específico
- ...
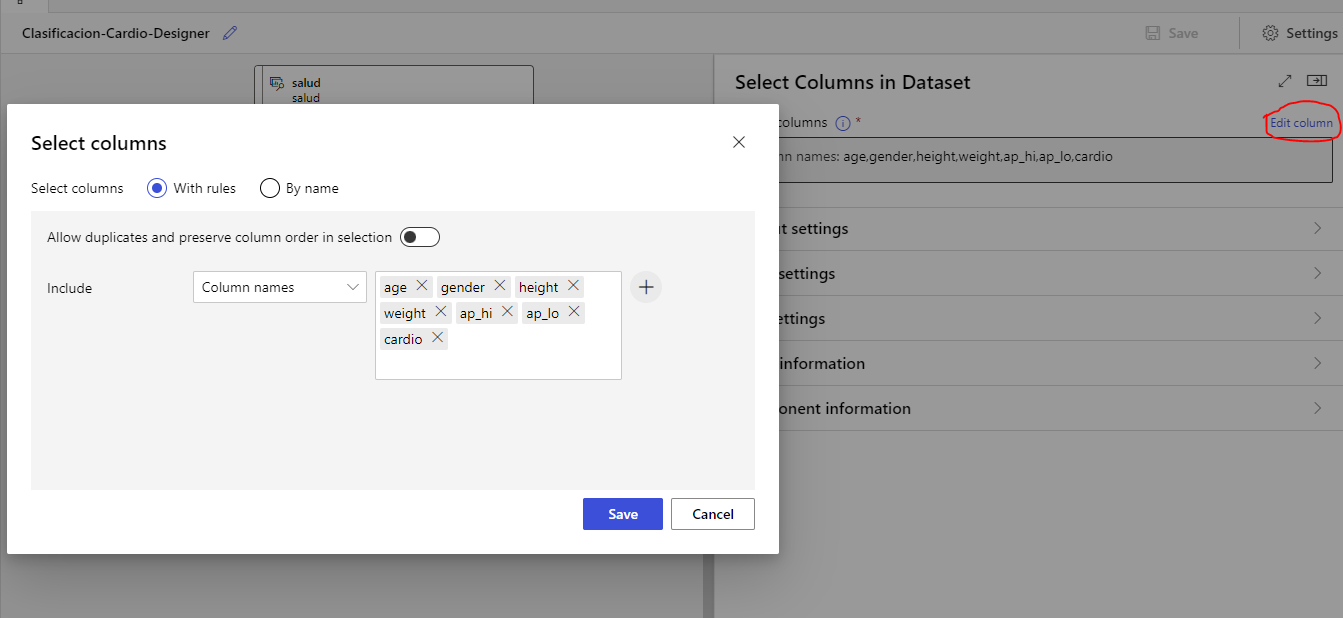
Por ejemplo, sobre nuestro dataset de datos de salud que hemos utilizado en un ejemplo anterior, vamos a seleccionar ciertas columnas. Arrastramos el nodo de Select Columns in Dataset, hacemos doble clic en él y, en el panel derecho, elegimos Edit column para seleccionar las columnas que nos interesan.
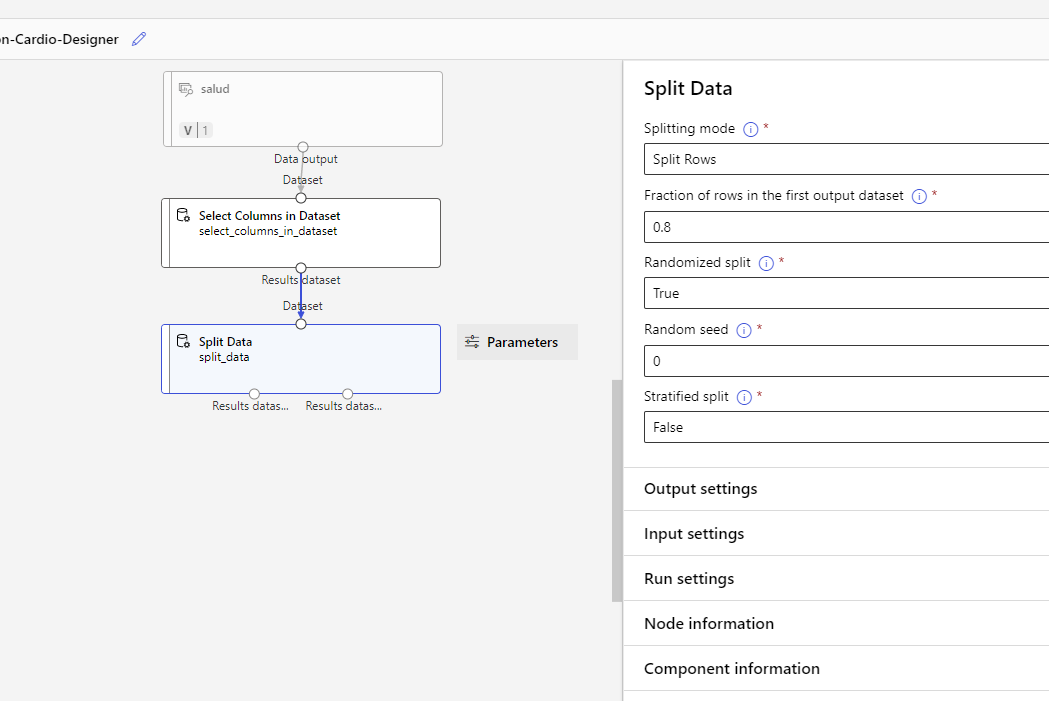
Ahora vamos a dividir los datos en un conjunto de entrenamiento y otro de test, usando el nodo Split Data. Lo conectamos con el anterior, hacemos doble clic en él y lo configuramos para dejar un 80% de muestras en la primera partición y un 20% en la segunda:
Aplicaremos ahora algún proceso de machine learning, como por ejemplo un random forest. Elegimos el componente Two-Class Decision Forest, y también el componente Train Model. Conectamos el forest al componente de entrenamiento, junto con el primer conjunto de datos dividido del nodo anterior, de esta forma:
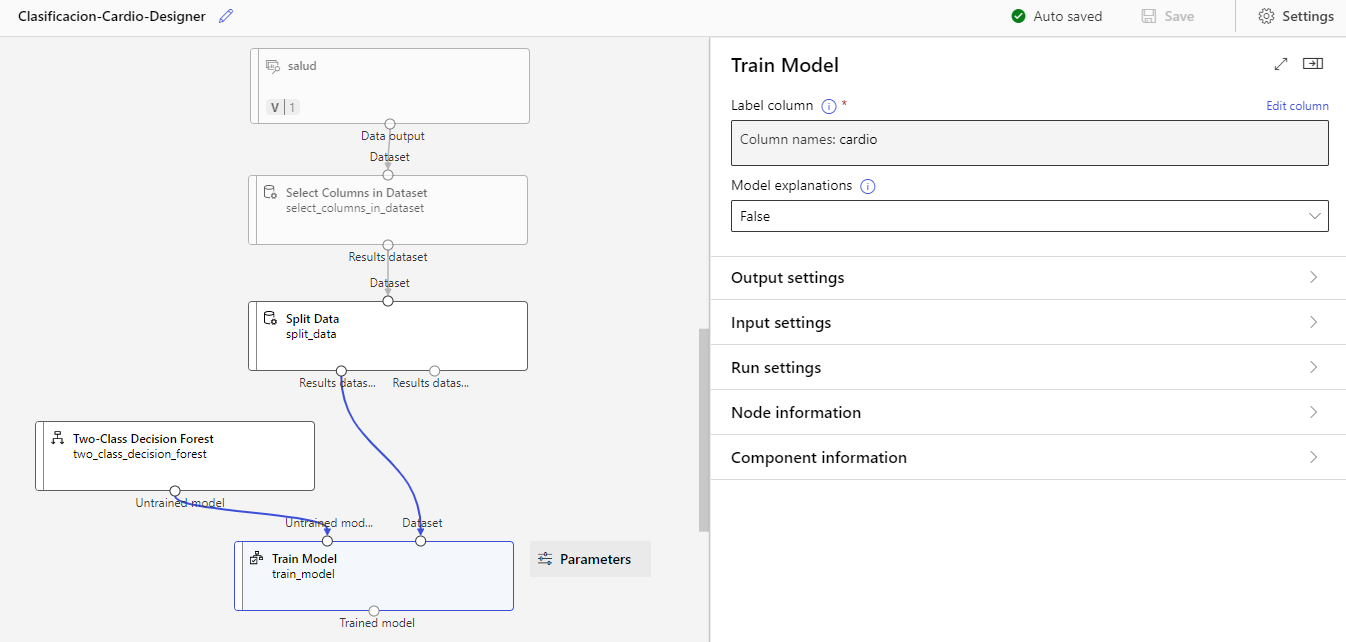
Hacemos doble clic en el nodo Train Model y elegimos como columna objetivo (Label column) la que queremos aprender a predecir (cardio).
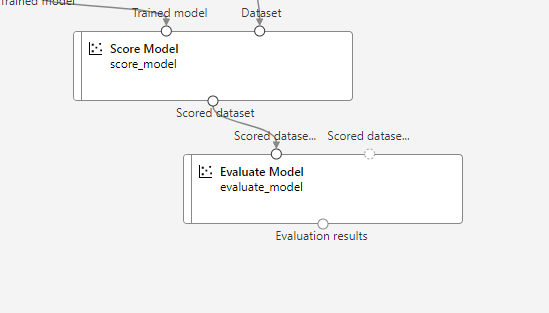
Tras el entrenamiento, conviene medir el funcionamiento del modelo con los datos de test que hemos separado previamente. Usaremos el componente Score Model, conectándolo con la salida del entrenamiento anterior, y con el subconjunto de test:
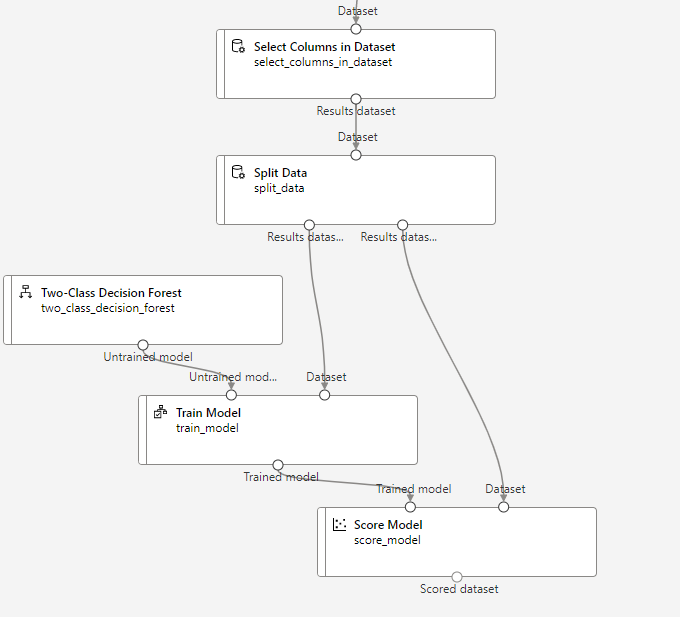
Finalmente, conectamos el nodo anterior con otro llamado Evaluate Model para evaluar los resultados finales.
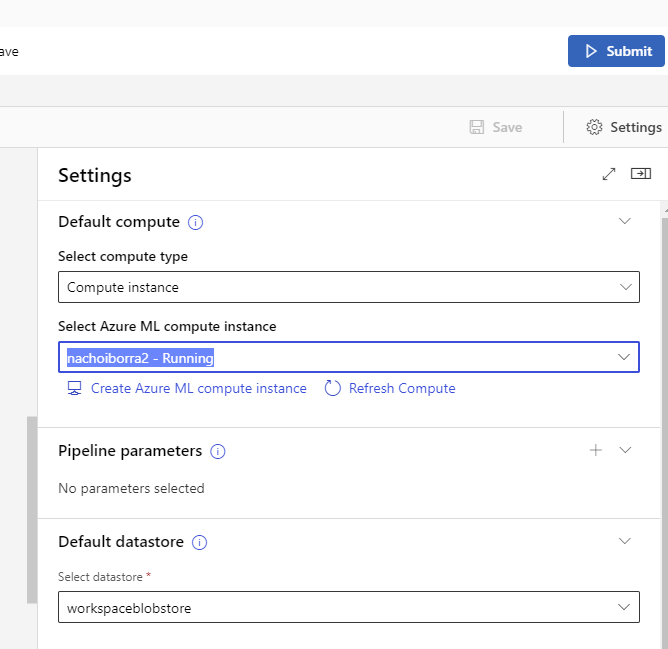
Ahora que ya tenemos todo el proceso conectado, falta ponerlo en marcha y desplegar el modelo resultante. Antes de eso, en los Settings del diseñador (parte superior derecha), debemos elegir la instancia de cómputo que usaremos para entrenar el modelo (la debemos dejar iniciada previamente):
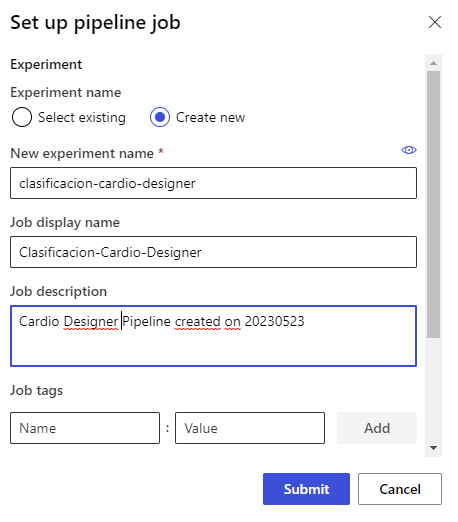
Después pulsamos el botón Submit de esa parte superior derecha para iniciar el proceso. Creamos un nuevo experimento (experiment) con el nombre que queramos
Una vez iniciado, en el propio job del Designer podremos ver qué nodos están en funcionamiento en un momento determinado. En la sección Pipelines del menú izquierdo de Studio podremos ver los pipelines en ejecución, y su estado actual.
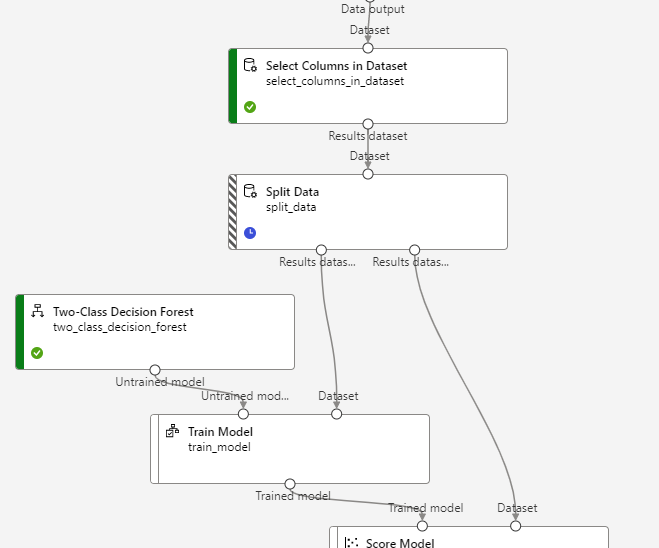
Al finalizar el proceso de Submit tendremos el pipeline listo. Debemos ir al menú superior y elegir Create inference pipeline, y dentro elegir Real-time inference pipeline.
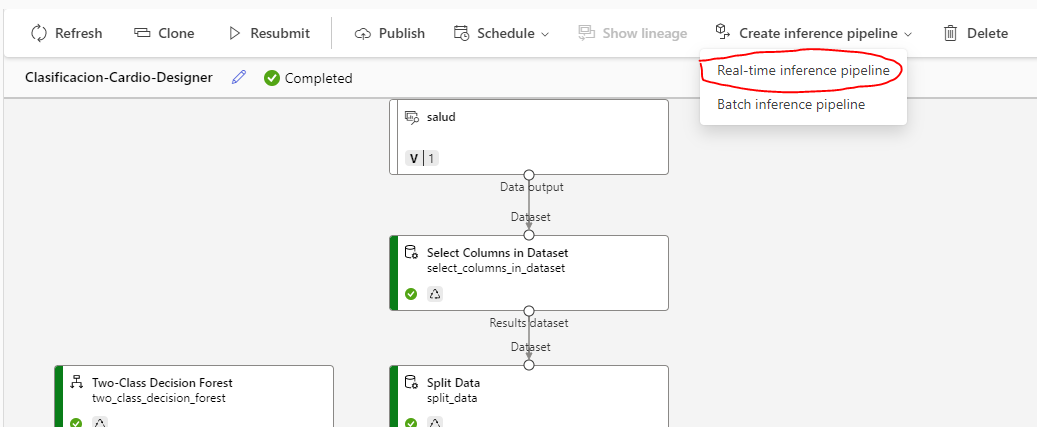
Esto eliminará los nodos de entrenamiento del modelo (ya no hacen falta) y añadirá nodos de servicios web. Si falta alguno, podemos añadirlo nosotros manualmente, para que quede algo así:
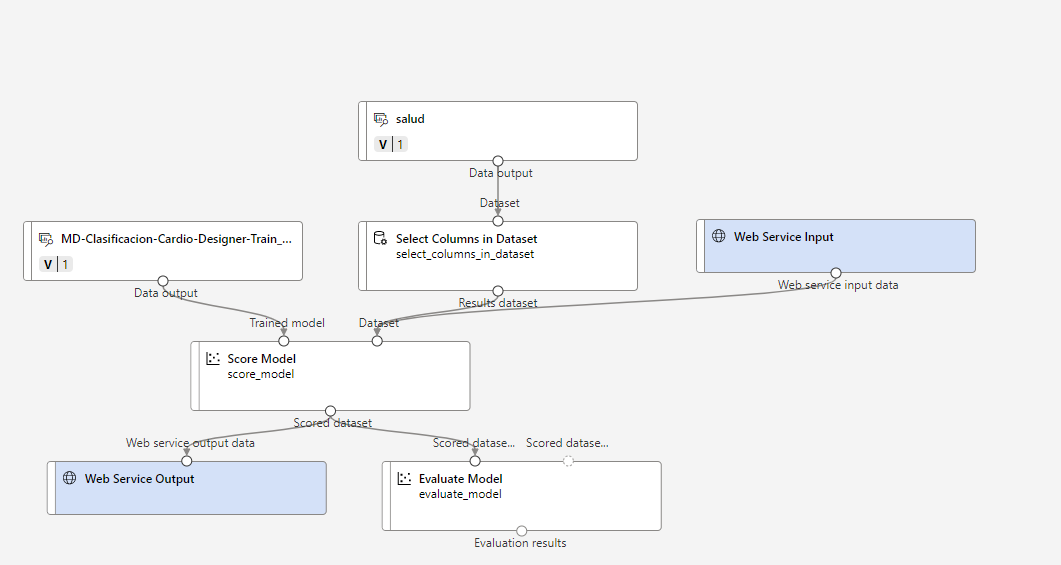
Pulsamos nuevamente en Submit y elegimos el mismo experimento y entorno de ejecución que antes y, cuando termine, en el Job detail de la tarea podremos desplegar el modelo concluido:
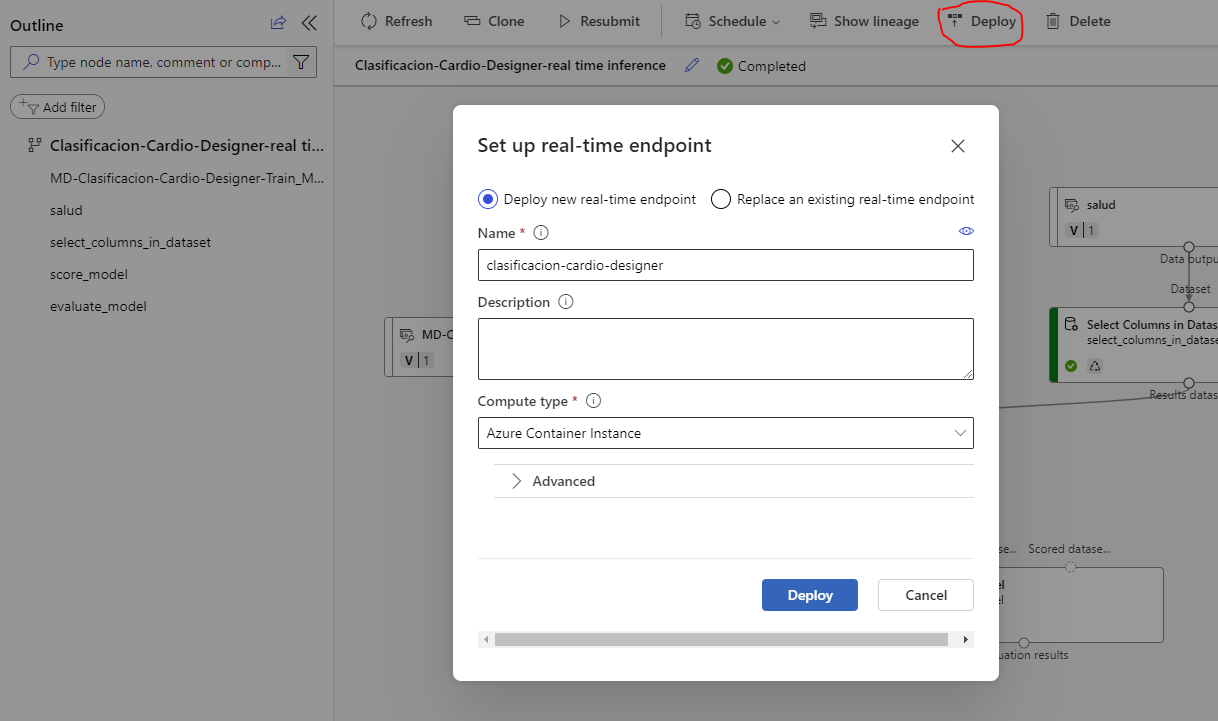
En la sección Endpoints del menú izquierdo de Studio, como en los casos anteriores, podremos ver el estado del endpoint, y el código necesario para consumirlo.
Ejercicio 4
Sigue este ejercicio paso a paso para construir un modelo de regresión usando el designer de Azure.
Ejercicio 5
Sigue este ejercicio paso a paso para construir un modelo de clasificación usando el designer de Azure.
Ejercicio 6
Sigue este ejercicio paso a paso para construir un modelo de aprendizaje no supervisado para dividir en categorías un conjunto de datos de entrada (clustering).
3.2. Despliegue de una aplicación propia en Azure¶
Además de poder ejecutar y probar modelos en los cuadernos disponibles desde Azure Machine Learning Studio, también podemos desplegar y poner a disposición nuestros propios modelos en la nube.
Esta tarea es algo más tediosa, ya que, además de entrenar el modelo, debemos configurar un entorno de ejecución de forma algo más manual, definiendo las características del contenedor (típicamente Docker) donde desplegar la aplicación, etc. En esta web disponéis de un ejemplo paso a paso de cómo completar esta tarea.