Redes recurrentes¶
En este documento abordaremos el estudio de las redes neuronales recurrentes (RNN, Recurrent Neural Networks), útiles cuando interviene el factor tiempo en el estudio de los datos, o cuando queremos procesar una secuencia de datos de entrada donde el orden entre ellos es un elemento a tener en cuenta.
1. Presentando el problema a resolver¶
Para ilustrar el tipo de problema que pretenden resolver las redes recurrentes, veamos un ejemplo sencillo. Imaginemos una secuencia de los números del 1 al 5 (es decir: 1, 2, 3, 4, 5) que se repite consecutivamente en el tiempo:
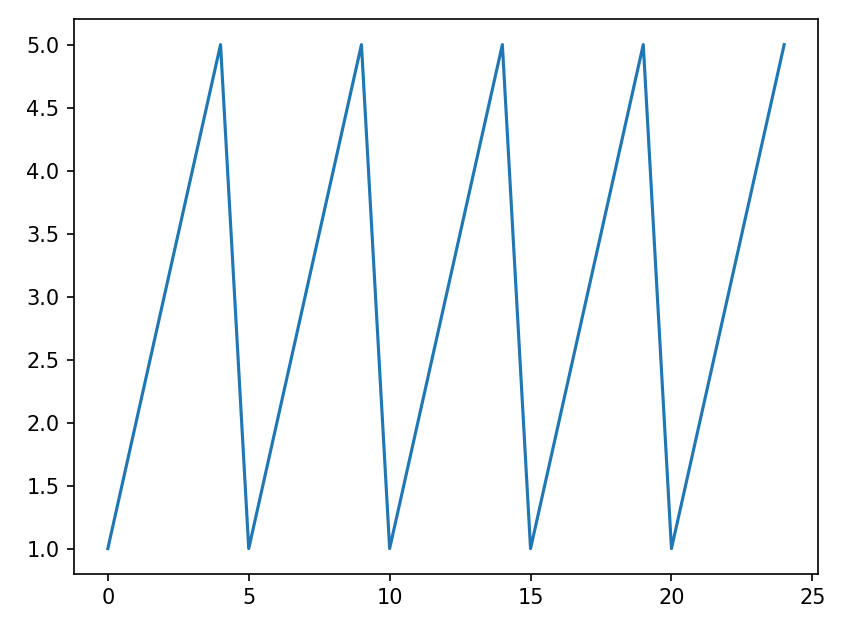
Vamos a plantear una red neuronal convencional a la que le pasemos una secuencia consecutiva de 1000 de estos valores, e intente aprender a predecir el siguiente valor. Construimos primero el conjunto de valores objetivo y como una secuencia 1-5 repetida 1000 veces. Las x correspondientes serán los números de orden de cada valor, del 0 en adelante (o del 1 en adelante, como prefiramos):
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
y = np.array(list(np.arange(1, 6))*1000)
# y = [1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 1, 2, 3 ...]
x = np.arange(0, len(y))
# x = [0, 1, 2, 3, 4, 5, 6, 7, 8...]
Ahora vamos a construir todo un perceptrón multicapa, con varias capas densas, que intente predecir, para un valor de x, su correspondiente y:
modelo = Sequential()
# Un solo dato de entrada (cada valor de la secuencia)
modelo.add(Input(shape=(1,)))
modelo.add(Dense(25, activation='linear', kernel_initializer='uniform'))
modelo.add(Dense(25, activation='linear', kernel_initializer='uniform'))
modelo.add(Dense(25, activation='linear', kernel_initializer='uniform'))
modelo.add(Dense(1, activation='linear', kernel_initializer='uniform'))
Compilamos el modelo y lo entrenamos con el conjunto de datos inicial:
modelo.compile(loss='mae')
modelo.fit(x, y, epochs=100)
Ahora vamos a pedirle que nos prediga cuáles son los siguientes 3 números de la secuencia:
print("Predicción de siguientes números:")
x_test = np.array([len(y), len(y)+1, len(y)+2])
y_pred = modelo.predict(x_test).flatten()
print(y_pred)
Obtendremos como resultado algo parecido a esto:
[2.9656572 2.9656527 2.965648 ]
¿Qué es lo que ha ocurrido? Básicamente hemos planteado un problema de regresión lineal. La red ha distribuido los puntos, ha calculado la recta que mejor se aproxima a ellos y la ha prolongado en el tiempo, permitiendo así calcular los puntos siguientes. El problema es que la recta es una línea horizontal en este caso, que pasa cerca de la media de valores que estamos introduciendo, que es 3.
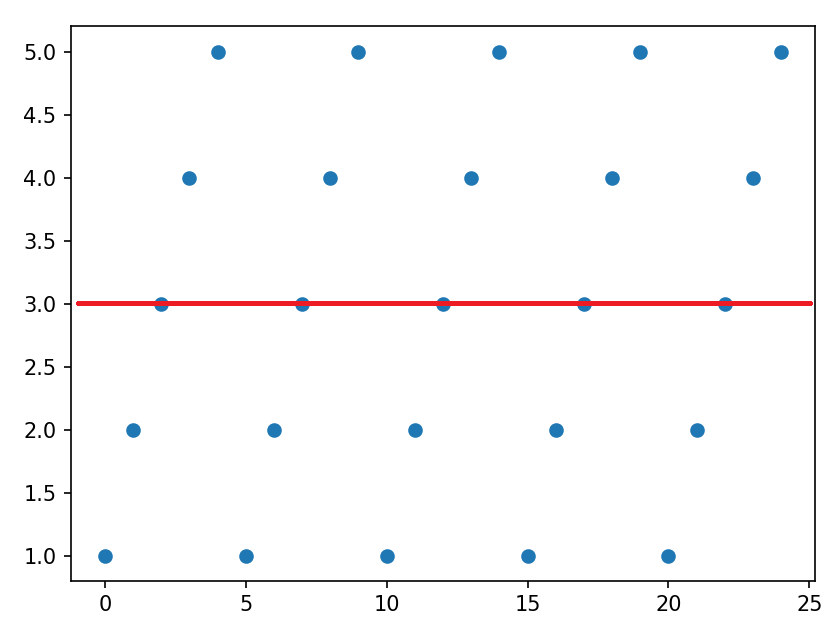
Dicho de otro modo, esta red convencional, por muchas capas y neuronas que pongamos, es incapaz de predecir un valor teniendo en cuenta la secuencia previa de valores que hay. Además, hemos planteado mal el enfoque de entradas y salidas. Intentamos que la red prediga cuál va a ser el n-ésimo elemento de la serie, dados los n valores previos, cuando en realidad deberíamos preguntarle qué número sigue a una secuencia dada como entrada. Por ejemplo, "para la secuencia [2 3 4 5 1 2 3 4], ¿cuál es el siguiente número?". Veremos a continuación cómo podemos reformular el problema.
1.1. Los timesteps¶
Un paso importante en la configuración de redes que deban predecir un valor futuro en una secuencia es la definición de los timesteps. Este parámetro hace referencia a cuántos instantes o pasos atrás necesitamos tener en cuenta, o será capaz de recordar la red. Es un parámetro que puede calcularse de forma empírica, haciendo pruebas con varios valores (1, 10, 20...). La idea es, dado un timestep T tomar el conjunto de entrenamiento e ir haciendo grupos de T valores e intentar predecir con ellos el T+1. Por ejemplo, si T = 10, tomaríamos los 10 primeros valores e intentaríamos predecir el 11, y luego tomaríamos los valores del 2 al 11 e intentaríamos predecir el 12, y así sucesivamente.
El código podría quedar así, partiendo una variable df (dataframe de Pandas) con los datos de entrada ya preparados:
T = 10
df = ... # Preparar dataframe
X_train = []
y_train = []
# Añadimos los T valores correspondientes
# y el valor a predecir
# Ponemos columna 0 suponiendo que el dataframe
# sólo tiene una columna a estudiar
for i in range(T, len(df)):
X_train.append(df[i-T:i, 0])
y_train.append(df[i, 0])
# Convertirmos las listas a arrays de NumPy
X_train, y_train = np.array(X_train), np.array(y_train)
Note
El conjunto X_train en el ejemplo anterior es un array bidimensional de datos, donde en cada fila tenemos una secuencia de T valores. En algunos casos podría interesar tener un array tridimensional, donde podamos almacenar en paralelo varias secuencias de un mismo valor, o secuencias de distintos valores para un mismo fenómeno o punto de partida. Podemos usar algo como X_train = np.reshape(X_train.shape[0], X_train.shape[1], N), siendo N el número de capas paralelas que queramos añadir.
1.2. Reformulando el ejemplo anterior¶
Volvamos al ejemplo anterior donde intentamos predecir cuál será el siguiente valor en una secuencia continua de números del 1 al 5. Vamos a intentar resolver el problema ahora usando una red convencional y timesteps.
Comenzamos igual que antes, definiendo la secuencia de valores repetidos 1, 2, 3, 4, 5... En este caso no serán necesarios los valores de x:
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
y = np.array(list(np.arange(1, 6))*1000)
El siguiente paso será configurar los conjuntos de entrada con el correspondiente timestep. Por ejemplo, vamos a tomar un T = 5, que coincide con la secuencia de 5 dígitos que se repite.
T = 5
X_train = []
y_train = []
for i in range(T, len(y)):
X_train.append(y[i-T:i])
y_train.append(y[i])
X_train, y_train = np.array(X_train), np.array(y_train)
Así quedarán los vectores que hemos definido:
| Elemento | Secuencia (5 números) | Elemento | Resultado |
|---|---|---|---|
X_train[0] |
[1 2 3 4 5] |
y_train[0] |
1 |
X_train[1] |
[2 3 4 5 1] |
y_train[1] |
2 |
X_train[2] |
[3 4 5 1 2] |
y_train[2] |
3 |
| ... | ... | ... | ... |
Ahora construimos la red. Añadiremos tres capas ocultas de 5 neuronas cada una, por ejemplo, y una capa de salida de una neurona que emitirá cuál es el valor que seguirá a la secuencia de entrada:
modelo = Sequential()
modelo.add(Input(shape=(X_train.shape[1],)))
modelo.add(Dense(5, activation='linear', kernel_initializer='uniform'))
modelo.add(Dense(5, activation='linear', kernel_initializer='uniform'))
modelo.add(Dense(5, activation='linear', kernel_initializer='uniform'))
modelo.add(Dense(1, activation='linear', kernel_initializer='uniform'))
Compilamos y entrenamos la red con los datos de entrada X_train e y_train.
modelo.compile(optimizer='adam', loss='mae')
# Con un número bajo de epochs nos bastará para
# comprobar los resultados en este caso
modelo.fit(X_train, y_train, epochs=10)
Note
Podemos comprobar cómo, en este caso, la función de pérdida va disminuyendo, mientras que en el ejemplo anterior no bajaba de un cierto valor de loss, cuando ya había ajustado la recta de regresión.
Ahora vamos a pedirle a la red que nos prediga cuál va a ser el siguiente valor dadas unas secuencias de números de entrada (tenemos que respetar el mismo formato de entrada de datos que en el entrenamiento):
print("Predicción de siguientes números:")
x_test = np.array([np.array(list(np.arange(1, 6))),
np.array([3, 4, 5, 1, 2]),
np.array([5, 1, 2, 3, 4])])
y_pred = modelo.predict(x_test).flatten()
print(y_pred)
Como secuencias de prueba le hemos pasado tres distintas:
- Una con los números 1, 2, 3, 4, 5 (el siguiente número sería el 1)
- Otra con los números 3, 4, 5, 1, 2 (el siguiente número sería el 3)
- Otra con los números 5, 1, 2, 3, 4 (el siguiente número sería el 5)
El resultado que obtendremos es muy aproximado al real (mejoraría si añadimos más epochs al entrenamiento):
[0.9957801 2.9836855 5.048282 ]
Como vemos, el incluir el factor tiempo mejora mucho la predicción de resultados basados en secuencias temporales. Sin embargo, el uso de una red neuronal convencional se quedará corto en muchos casos, o se limitará a "memorizar" las secuencias de entrenamiento para saber qué dato va a continuación en cada caso. Necesitamos un paso más para poder predecir mejor el resultado en series temporales. Echemos un vistazo a las redes recurrentes.
2. Fundamentos de las RNR¶
Como decimos, ciertos problemas no pueden resolverse con los datos tomados en un instante determinado. Por ejemplo:
- ¿Cómo podríamos predecir el valor de una acción en el futuro? Necesitamos conocer la secuencia de valores que ha ido tomando dicha acción a lo largo de los días.
- ¿Cómo podemos determinar si una reseña o crítica a un restaurante es positiva o negativa? No nos basta con una sola palabra, necesitamos saber la frase entera que se ha escrito, y el orden en que se han indicado las palabras.
- ¿Cómo podemos predecir qué va a pasar en una película? No basta con el fotograma actual, necesitamos saber la trama que ha ido ocurriendo hasta este momento en la película.
Una red neuronal tradicional no serviría para este tipo de problemas, puesto que su salida únicamente está condicionada por una entrada (un valor, una imagen), pero no tenemos forma de proporcionarle una secuencia de datos y que los tenga todos en cuenta para tomar su decisión final. Para solucionar este problema surgieron las redes neuronales recurrentes. La primera idea fue propuesta por Jordan en 1986, y más tarde, en 1997, Hochreiter y Schmidhuber propusieron las neuronas LSTM que, como veremos, ayudaron a mejorar el funcionamiento general de este tipo de redes.
2.1. Las neuronas recurrentes¶
Las redes neuronales recurrentes están compuestas por neuronas recurrentes. Una neurona recurrente se diferencia de la neurona o perceptrón tradicional en que dispone de un bucle recurrente, que les permiten mantener un estado en el tiempo. Así, la salida en un instante de tiempo t de una neurona (llamemos a esa salida yt), vendrá dada por la entrada a la neurona en ese instante xt y la salida en el instante anterior yt-1. También podemos ver esto como una secuencia de pasos en una neurona, donde cada paso conecta su estado al siguiente paso.

Una red recurrente estará formada por muchas neuronas de este tipo, cada una recibiendo su(s) entrada(s) x y produciendo su(s) salida(s) y.
2.2. Ámbitos de aplicación¶
El hecho de disponer de neuronas recurrentes permite aplicar las RNR en diferentes tipos de problemas:

- Uno a uno: serían los problemas convencionales que se pueden resolver con perceptrones multicapa clásicos: a una entrada determinada le corresponde una salida.
- Muchos a uno: se reciben muchos datos de entrada secuencialmente para producir una salida. Por ejemplo, a partir de una reseña en un restaurante (secuencia de muchas palabras) concluir si es una reseña positiva o negativa (un único resultado final). Es lo que se denomina análisis de sentimiento.
- Uno a muchos: se recibe un único dato de entrada a partir del cual la salida debe constar de una secuencia de datos. Por ejemplo, a partir de una imagen, emitir una descripción de lo que contiene dicha imagen (secuencia de palabras).
- Muchos a muchos: se recibe una secuencia de varios datos como entrada y se emite una secuencia de varios datos como salida. Ejemplos típicos son los sistemas de traducción automática (caso 1 del esquema anterior, donde necesitamos algo de contexto previo para empezar a traducir), o los subtítulos automáticos en vídeos (caso 2, donde se subtitula sobre la marcha cada entrada que se recibe).
2.3. El problema del gradiente. Las neuronas LSTM.¶
Como hemos visto, una red neuronal recurrente puede acudir a datos de estados anteriores para ayudar a predecir la salida del instante actual. En ocasiones sólo es necesario un contexto cercano al estado actual para poder deducir la salida. Por ejemplo, si decimos "El perro dice X", podemos concluir analizando tres o cuatro palabras previas que la palabra X debería ser "guau".
Pero en algunas ocasiones hace falta irse más atrás para poder deducir adecuadamente el resultado que se tiene que generar, y esto es un problema para las redes recurrentes ya que, a medida que aumenta la distancia temporal, se diluye más la información que se había recibido. También a la hora de propagar el error cometido desde un instante t, se debe propagar a instantes anteriores.

A medida que el error viaja hacia atrás, o necesitamos acudir a instantes más lejanos en la secuencia, la información de que se dispone sobre esos instantes es más remota, y la medida del error cometido entonces se distorsiona, dependiendo del valor del gradiente. Para valores bajos hará que poco a poco se vaya diluyendo en el tiempo hacia atrás (vanishing gradient, desvanecimiento del gradiente), y para valores altos hará que se vaya agrandando hacia atrás (exploding gradient). Esto constituye un problema grave en el desarrollo de las redes recurrentes ya que, si los estados anteriores están mal calibrados, afectarán a las predicciones futuras de nuevas entradas.
Afortunadamente, en 1997 Hochreiter y Schmidhuber encontraron una solución al problema a través de las neuronas LSTM (Long Short-Term Memory), que permiten dotar a las neuronas no sólo de memoria a corto plazo, sino también a largo plazo. La diferencia principal entre una neurona LSTM y una neurona recurrente es que las primeras incluyen una celda o bucle de memoria. El mecanismo por el que se definen estas neuronas es bastante complejo de explicar, y no profundizaremos mucho en él en este documento. Aquí tenéis un artículo que explica en detalle los mecanismos de las neuronas LSTM, y aquí otro artículo alternativo o complementario.
Básicamente, la idea consiste en añadir un canal adicional c, que atraviesa los estados, y al que se le pueden añadir a través de ciertas válvulas los datos de la información siguiente. De esta manera, modulando las nuevas entradas, se decide qué parte de la información se conserva, y cuál dejamos pasar a los siguientes estados.

Fuente: colah.github.io
Así, las neuronas LSTM incluyen una serie de puertas que permiten controlar la información que entra y sale de la celda de memoria:
- Puerta de entrada: controla los valores de entrada que se van a utilizar para actualizar el estado de la memoria. Viene dada por una combinación de funciones sigmoide y tangente hiperbólica. En la figura anterior correspondería a la puerta central de la figura.
- Puerta de salida: decide qué parte de la memoria de la celda se usará para el estado siguiente. La función es una combinación de sigmoide y tangente hiperbólica. Corresponde a la puerta derecha en la figura anterior
- Puerta de olvido: controla el mantenimiento del contenido de la memoria, y decide cuánta información del estado anterior debe olvidarse. Viene definida por una función sigmoide sobre la entrada y el estado anterior, de modo que si es cercano a 0 la información se olvida y si es cercano a 1 se mantiene. Corresponde a la puerta izquierda en la figura anterior.
En las neuronas recurrentes se tiene una función de activación convencional para producir un nuevo resultado, y una función de activación recurrente para modular la salida que retroalimentará a la neurona. La función de activación convencional normalmente es una tangente hiperbólica (tanh), y la función de activación recurrente suele ser una sigmoide.
2.4. Recurrencia bidireccional¶
En algunas ocasiones interesa no sólo el contexto previo, sino el contexto posterior, a la hora de tomar una decisión o emitir un resultado acertado. Por ejemplo, si estamos analizando si una reseña es positiva o negativa, puede que al principio pueda parecer negativa si identificamos alguna palabra suelta ("horrible", "desastre"...). Pero, si vamos mas allá, puede que la propia reseña luego matice ese resultado y tengamos que descartar esa palabra.
Para facilitar esto, las neuronas recurrentes pueden tener dos conexiones, en direcciones opuestas:

3. Redes recurrentes con Keras/TensorFlow¶
Veamos ahora cómo se definen redes recurrentes en Keras/TensorFlow.
3.1. Elementos necesarios y construcción de la red¶
Para construir redes recurrentes necesitaremos algunos viejos conocidos de otros documentos, como la clase Sequential del paquete keras.models, o las capas Input, Dense y Dropout de keras.layers. A esto último añadiremos ahora la clase LSTM, también de keras.layers, para definir las capas recurrentes.
Respecto al constructor de LSTM, recibe estos parámetros:
units: número de neuronas recurrentes en la capa. Podemos ajustarlo de forma experimental, aunque en general interesarán valores altos para añadir complejidad a la red y que sea capaz de aprender secuencias más o menos complejas. También podemos variar el número de unidades en las distintas capas recurrentes.return_sequences: booleano que indica si queremos ir apilando los valores de retorno. Será True si queremos conectar esta capa recurrente con otra posterior, y normalmente se pone a False en la última (salvo algunos casos de muchas salidas).input_shape: en el caso de omitir la capa de entrada, en este parámetro indicamos el número de conexiones de entrada de la red. Este parámetro sólo se ajusta en la primera capa LSTM, ya que el resto tomará automáticamente el tamaño de las capas anteriores. También podemos omitir este parámetro si especificamos una capaInputinicial, como en las redes multicapa convencionales.- Además, existen otros parámetros que permiten definir, por ejemplo, las funciones de activación. En el caso de capas LSTM se pueden configurar dos funciones de activación: una para generar el valor para la capa siguiente (normalmente es una función tanh), y otra para la propia recurrencia de la capa (normalmente es una función sigmoide). Ambos parámetros vienen inicializados con sus funciones por defecto.
Aquí vemos cómo construir una red con varias capas recurrentes (LSTM), incluyendo dropout entre ellas.
modelo = Sequential()
# Capa de entrada
modelo.add(Input((X_train.shape[1], 1)))
# Capas LSTM
modelo.add(LSTM(units=50, return_sequences=True))
modelo.add(Dropout(0.2))
modelo.add(LSTM(units=50, return_sequences=True))
modelo.add(Dropout(0.2))
modelo.add(LSTM(units=50, return_sequences=True))
modelo.add(Dropout(0.2))
# Capa final LSTM (return_sequences = False)
modelo.add(LSTM(units=50))
modelo.add(Dropout(0.2))
# Capa de salida (por ejemplo, con 1 neurona)
modelo.add(Dense(units=1))
Sobre el formato de datos
Como ya podemos intuir, para entrenar las redes recurrentes tendremos que proporcionar los datos en secuencias. Así, por ejemplo, para una red muchos a uno, cada muestra de entrenamiento constará de una secuencia de entrada y de una etiqueta o valor de salida. El conjunto de datos de entrada será un array tridimensional donde:
- En la primera dimensión indicaremos el número de ejemplos que pasaremos a la red
- En la segunda dimensión indicaremos la longitud de cada secuencia de datos, que típicamente se suele asociar a
X_train.shape[1]. - En la tercera dimensión las características de cada dato (normalmente cada dato consta de un solo valor, pero podría tener más)
En el caso de la salida se tendrán dos dimensiones, donde la primera indicará el número de resultados producidos, y la segunda el valor de cada resultado (nuevamente, en el caso de una red muchos a uno).
3.2. Compilación, entrenamiento y predicción¶
Para compilar la red, usaremos el método compile, especificando el optimizador y la función de pérdida, como en anteriores ejemplos.
modelo.compile(optimizer='adam', loss='mse')
Para entrenar a la red, usamos el método fit indicando los conjuntos de entrenamiento X e y:
modelo.fit(X_train, y_train, epochs=100, batch_size=32)
A la hora de predecir, usamos el método predict indicándole el conjunto de datos de entrada, que deberán tener una forma similar a los que hemos utilizado para entrenar.
predicciones = modelo.predict(X_test)
3.3. Un ejemplo¶
Volvamos a nuestro ejemplo inicial de predecir una secuencia de valores continuos del 1 al 5. Vamos a reemplazar el perceptrón multicapa del intento anterior por una red recurrente. Los primeros y últimos pasos no cambian, sólo cambiaremos el modelo de red por este otro, con tres capas recurrentes:
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout, LSTM
... # El código para configurar X_train e y_train no cambia
modelo = Sequential()
modelo.add(Input((X_train.shape[1], 1)))
modelo.add(LSTM(units=5, return_sequences=True))
modelo.add(Dropout(0.2))
modelo.add(LSTM(units=5, return_sequences=True))
modelo.add(Dropout(0.2))
modelo.add(LSTM(units=5))
modelo.add(Dropout(0.2))
modelo.add(Dense(units=1))
... # El código para compilar, entrenar y probar la red no cambia
Notar que en este caso la entrada es una tupla con dos valores a la primera capa recurrente la definimos con input_shape, ya que en el caso de redes recurrentes necesitamos definir una tupla con el tamaño del conjunto de valores de entrada (5, en nuestro caso), y cuántos conjuntos de valores se pasarán a la vez como entrada (1).
Los resultados obtenidos en este caso son similares a los de la red multicapa, aunque ligeramente peores:
[0.9254465 2.7648053 4.4466567]
El motivo del empeoramiento es que, en redes recurrentes, normalmente hacen falta capas más densas para retener la información previa y procesarla correctamente; subiendo el número de neuronas a 20 o 30 en las capas ocultas mejoramos el resultado. Podríamos pensar que esto es un retroceso con respecto a lo que ya sabemos... Sin embargo, como veremos en ejemplos posteriores, el uso de redes recurrentes LSTM supone una mejora importante en la predicción de valores en secuencias temporales más complejas
Puedes descargar aquí el código fuente de los distintos ejemplos que hemos realizado sobre este problema de la secuencia de valores de 1 a 5: una red MLP sencilla (v1), una red MLP con timesteps (v2) y esta última versión con capas LSTM (v3).
3.4. Ajuste de hiperparámetros en una RNR¶
A la hora de mejorar el comportamiento de una red neuronal recurrente, existen algunos hiperparámetros que podemos ajustar, además de los habituales en una red neuronal convencional:
- Por un lado, podemos intentar aumentar el conjunto de datos de entrada de que disponemos, para tener más información con la que entrenar a la red
- También podemos variar el tamaño del timestep, para ver qué rango de valores optimiza los resultados obtenidos
- En el conjunto de datos de entrada podemos añadir otras secuencias en paralelo. Por ejemplo, si estamos analizando el valor de una acción, tomaríamos la secuencia de valores de dicha acción en el tiempo como entrada. Pero, si tenemos conocimiento de que otras acciones pueden afectar al valor de la acción que estamos estudiando, podríamos añadir al dataset de entrada otras secuencias con los valores de esas otras acciones.
- Agregar más capas LSTM y/o más unidades en cada capa, para dotar a la red de mayor capacidad de análisis.
Ejercicio 1
Descarga este dataset sobre valores de una acción a lo largo de varios años. Utiliza este documento Google Colab para cargar el dataset y predecir el valor de la acción durante 2017, tomando como base los valores en los años previos. Crea para ello una RNR con los parámetros que se te indican en el documento Colab.
Ejercicio 2
Sobre el ejercicio anterior, evalúa el funcionamiento de otros modelos de red, como estos:
- 5 capas recurrentes de 80 neuronas cada una, optimizador adam, T = 90, 50 epochs
- 4 capas recurrentes de 80 neuronas cada una, optimizador sgd, T = 30, 100 epochs
Determina qué modelo ha obtenido mejores resultados (contando también con la RNR del ejercicio anterior)
3.5. Redes recurrentes bidireccionales¶
Keras dispone de una capa especial llamada Bidirectional, en el paquete keras.layers, que nos permite crear capas recurrentes con conexión bidireccional (hacia adelante y hacia atrás). Se utilizan como un wrapper que encapsula la capa LSTM que queremos convertir en bidireccional. Por ejemplo:
modelo = Sequential()
...
modelo.add(Bidirectional(LSTM(units=50, return_sequences=True)))
...
modelo.add(Dense(units=1))
Ejercicio 3
Partiendo del Ejercicio 1 anterior, prueba otro modelo diferente transformando la red recurrente inicial en una bidireccional. Haz todas las capas LSTM bidireccionales salvo la primera, que toma los datos de entrada. Compara los resultados (y el tiempo de entrenamiento) de esta red con la original.
4. Procesamiento del lenguaje natural¶
Uno de los ámbitos de aplicación más populares hoy en día de la IA es el procesamiento del lenguaje natural. Aquí podemos encontrar diversos campos: sistemas que traducen de un idioma a otro, o que interpretan un texto para encontrar un significado general, o incluso para emitir una respuesta elaborada, como ocurre hoy en día con sistemas como ChatGPT, Gemini o similares.
Veremos en este apartado algunas nociones básicas sobre las que se sustenta el procesamiento del lenguaje natural, y distintas estrategias para abordarlo.
4.1. Fundamentos previos¶
Como paso inicial, vamos a analizar algunos elementos importantes de la problemática a la que nos enfrentamos, y cómo podemos procesar las palabras del texto a analizar.
4.1.1. Problemas inherentes al procesamiento de textos¶
A la hora de analizar un texto y extraer o catalogar su significado, nos podemos encontrar con diferentes problemas:
- La semántica o significado de las palabras. ¿Cómo trasladar esos significados a un ordenador?
- La secuencia o el orden en que vienen dadas las palabras será determinante para asignar un significado o veracidad a la frase. Por ejemplo, las frases "Los leones comen gacelas" y "Las gacelas comen leones" tienen las mismas palabras, pero el orden en que las ubicamos hace que una sea cierta y la otra no.
- La representación numérica de las palabras. Dado que los datos que recibe una red neuronal son datos numéricos, debemos encontrar una forma de codificar las palabras en números de forma unívoca. Trataremos este punto a continuación
- El lenguaje no estándar, ya que en algunas ocasiones se escriben palabras que no se recogen en un diccionario tradicional: palabras mal escritas, abreviaturas, etc.
- La segmentación de la frase, para identificar los componentes principales (sujeto, verbo...)
4.1.2. Representación numérica de la entrada¶
Como hemos visto, es necesario codificar de algún modo las palabras para pasarlas a la red neuronal. Podemos optar por dos estrategias principales:
- Codificación (encoding): es la forma más simple de conversión. Asigna a cada palabra o a cada letra una representación numérica
- Encaje o incrustación (embedding): las palabras se representan mediante vectores numéricos, de forma que dos palabras de significado similar tienen vectores también similares.
Codificación de palabras (word encoding)
Existen dos tipos de codificación de textos: por caracteres o por palabras. En la codificación por caracteres se dispone de una tabla con tantas columnas como letras del alfabeto, y tantas filas como letras tenga la frase a analizar. En cada fila, se marca como 1 la letra correspondiente a esa posición. Por ejemplo, para la frase "hola buenas" tendríamos algo así:
| a | b | c | d | e | f | g | h | i | j | k | l | m | ... | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| h | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | ... |
| o | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... |
| l | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | ... |
| a | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... |
| _ | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... |
| b | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... |
| u | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... |
| e | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... |
| n | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... |
| a | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... |
| s | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... |
Podría ser una estrategia válida, pero se utiliza mucha memoria para almacenar la codificación de la frase y, además, se pierde la noción de "palabra" y de "significado" en este caso. La red se dedicaría a asociar secuencias de letras a resultados, pero no palabras ni combinaciones de palabras de forma sencilla.
En la codificación por palabras se construye un diccionario de palabras conocidas, y se le asigna a cada una un código numérico distinto. Por ejemplo:
| Palabra | Código |
|---|---|
| hola | 1 |
| buenas | 2 |
| leones | 3 |
| comen | 4 |
| gacelas | 5 |
| ... | ... |
Es importante, en este caso, decidir el tamaño del diccionario, ya que con esto sólo permitiremos registrar un número limitado de palabras. Todas aquellas palabras no comprendidas en el diccionario quedarán marcadas con un código adicional, que significará que esa palabra no se reconoce y no se tendrá en cuenta (por ejemplo, código 0 en el caso anterior). Así, una frase como "hola buenas, los leones comen gacelas" se podría codificar como [1, 2, 0, 3, 4, 5].
Encaje de palabras (word embedding)
El encaje de palabras va un paso más allá de la codificación, y transforma cada código de palabra en un vector. La idea es, a partir del texto original, obtener la codificación de cada palabra, vectorizarlas y pasar esto como entrada a una red recurrente para que obtenga un resultado final:
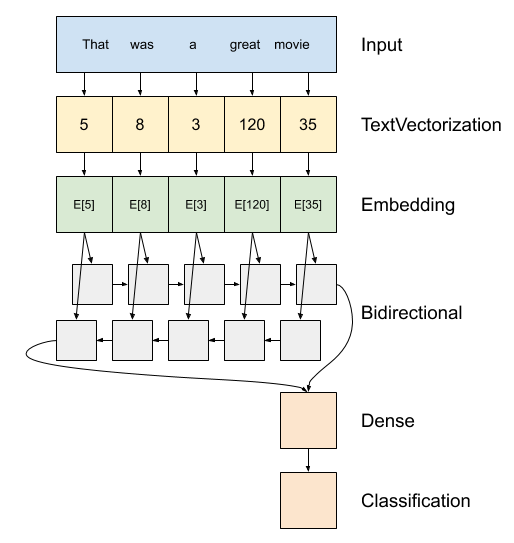
Como vemos, añadimos una etapa más en la entrada, tras la codificación de las palabras, para vectorizarlas. Esto permite, entre otras cosas, eliminar una posible "relación de orden" entre las palabras. En el ejemplo anterior, la red podría llegar a asimilar que la palabra 120 es "mejor" o "peor" que la 35 por tener un código mayor. Por otra parte, palabras con significados similares como "triste" y "deprimido" podrían tener códigos muy dispares, lo que haría que la red no aprenda a establecer asociaciones entre ellas.
Al vectorizar los datos se pierde esa relación de orden numérica. Además, también se pretende que las palabras que sean similares tengan un vector similar de representación. Como viene siendo habitual en el mundo del deep learning, buscaremos que la red neuronal aprenda a crear vectores similares para palabras similares por sí misma.
4.2. Procesamiento del lenguaje en Keras/TensorFlow¶
Veamos algunas estrategias y mecanismos que podemos emplear usando Keras/TensorFlow y algunas librerías auxiliares para procesar secuencias de textos y pasarlos como entrada a redes neuronales recurrentes.
4.2.1. Pasos previos¶
Antes de construir un modelo de procesamiento de lenguaje natural en Keras/TensorFlow, es necesario realizar una serie de pasos previos de tratamiento del texto de entrada. Existen varias estrategias para esto, aunque aquí plantearemos las más habituales.
1. Cargar o preparar las palabras irrelevantes (stop words)
Los stop words o palabras vacías son palabras que no aportan un significado relevante en las frases, como por ejemplo preposiciones (de, con...) o conjunciones (y, que...). Tener en cuenta estas palabras en el análisis de las frases puede hacer que éstas ocupen más espacio del necesario y se complique innecesariamente el modelo. Así que la idea es tenerlas identificadas para ignorarlas cuando analicemos los textos.
Podemos encontrar en Internet diferentes listas de stop words para cada idioma. Existen, además, librerías como nltk que descargan y utilizan listados predefinidos de stop words en el idioma indicado. Primero instalamos la librería en nuestro entorno (pip install nltk) y luego cargamos las stop words de este modo:
import nltk
from nltk.corpus import stopwords
# Paso previo obligatorio para descargar las listas al equipo local
nltk.download('stopwords')
# Ahora ya se pueden cargar las stop words del idioma que queramos
stop_words = stopwords.words('spanish')
De forma alternativa, también podemos crear nosotros nuestra propia lista de stop words para ejemplos sencillos:
stop_words = ['un', 'una', 'el', 'que', 'y', 'la', 'de']
2. Obtener la raíz de las palabras
Hay que tener en cuenta que puede haber distintas versiones de una misma palabra; por ejemplo, "comido", "comió", "comer"... se refieren todas a un mismo verbo, y podríamos simplificarlas haciendo que todas sean la raíz común (com, en este caso). Este proceso se llama lematización o stemming, y ayuda a que no haya muchas palabras con un significado similar en nuestro diccionario.
La propia librería NLTK cuenta con un lematizador que permite obtener la raíz de las palabras que se encuentre para un idioma determinado. Podríamos definir una función como esta:
import re
from nltk.stem import SnowballStemmer
stop_words = ... # La lista de stop words que hayamos creado
stemmer = SnowballStemmer('spanish')
# Función que tokeniza (separa en palabras) y aplica stemming
def stem_tokenizer(texto):
# Tokenizamos (separamos las palabras del texto)
tokens = re.findall(r'\b\w+\b', texto.lower())
# Eliminamos los stop words
tokens = list(filter(lambda x: x not in stop_words, tokens))
# Aplicamos stemming
return [stemmer.stem(t) for t in tokens]
3. Obtener un diccionario con las N palabras (raíces) más relevantes del conjunto de entrenamiento
En este paso analizaremos cada texto de entrada, lo dividiremos en palabras y nos quedaremos con las N más representativas (las N que más ocurrencias tienen en el contexto en que estamos trabajando), asignándole a cada una un código numérico distinto.
Para ayudarnos en todo este proceso, podemos emplear la clase CountVectorizer de SciKit Learn. Dispone de un constructor donde podemos indicarle la lista de stop words, el tamaño N del diccionario que queramos generar (cuántas palabras elegimos) y el tokenizador que procesará cada palabra, entre otras cosas. Con el método fit_transform le pasamos un texto o array de textos y genera un diccionario en la propiedad vocabulary_.
from sklearn.feature_extraction.text import CountVectorizer
N = 5
stop_words = ['un', 'una', 'el', 'que', 'y', 'la', 'de']
textos = ['Había una vez un circo que alegraba siempre el corazón',
'Érase una vez un planeta triste y oscuro',
'Mírala, la puerta de Alcalá']
# Le pasamos el tokenizador de stemming anterior que ya separa palabras y elimina stop words
# Por eso stop_words es None y token_pattern también
cv = CountVectorizer(tokenizer=stem_tokenizer, token_pattern=None, stop_words=None, max_features = N)
cv.fit_transform(textos)
# Diccionario con las N=5 palabras más relevantes
diccionario = cv.vocabulary_
Hay que tener en cuenta que, además de las palabras del vocabulario, habrá que dejar dos huecos especiales más, que podemos asignar a los números 0 y 1, por ejemplo:
- 0 para palabras desconocidas (no contempladas en el vocabulario)
- 1 para palabras de relleno o padding, usadas para igualar la longitud de las cadenas de entrada
Así, nuestro diccionario podría quedar así:
diccionario = dict([(palabra, i+2) for i, palabra in enumerate(diccionario)])
diccionario['DESC'] = 0
diccionario['PAD'] = 1
4. Uniendo las piezas
Vamos a crear una función llamada generar_diccionario que recibirá como parámetros:
- El array
textosde entradas de texto a procesar - El tamaño
Ndel vocabulario que queremos construir
La función devolverá el diccionario creado con los textos de entrada, apoyándose en el stem_tokenizer anterior:
def generar_diccionario(textos, N):
cv = CountVectorizer(tokenizer=stem_tokenizer, token_pattern=None, stop_words=None, max_features = N)
cv.fit_transform(textos)
diccionario = cv.vocabulary_
diccionario = dict([(palabra, i+2) for i, palabra in enumerate(diccionario)])
diccionario['DESC'] = 0
diccionario['PAD'] = 1
return diccionario
Esta otra función tomará un texto como entrada y, aplicando el diccionario y la lista de stop words, devolverá la secuencia de códigos que representa el texto, incluyendo los símbolos desconocidos y de relleno, para formar una frase de T palabras:
def procesar_cadena(texto, diccionario, stop_words, T):
# Identificar palabras en el texto
palabras = re.findall(r'\b\w+\b', texto.lower())
# Eliminar stop words
palabras = list(filter(lambda x: x not in stop_words, palabras))
# Lematizar (stemming) el resto de palabras
palabras = [stemmer.stem(p) for p in palabras]
resultado = []
for i in range(0, T):
if i < len(palabras):
if palabras[i] in diccionario:
resultado.append(diccionario[palabras[i]])
else:
resultado.append(diccionario['DESC'])
else:
resultado.append(diccionario['PAD'])
return np.array(resultado)
4.2.2. Ejemplo de red recurrente con word encoding¶
Para poner en práctica todos estos conceptos, utilizaremos este dataset con reseñas de hoteles en la web TripAdvisor, basado en este reto de Kaggle. En cada línea se tiene el texto completo de la reseña y la valoración numérica (entero de 1 a 5) que ha hecho el usuario en cuestión. Vamos a construir una red recurrente que, con una codificación previa de las palabras, aprenda a adivinar la puntuación que da un cliente a un hotel, dada su reseña.
Comenzaremos nuestro programa cargando las librerías necesarias, junto con las funciones que hemos definido previamente, y una lista de stop words en inglés:
import re
import numpy as np
import pandas as pd
from keras.models import Sequential
from keras.layers import Input, Dense, LSTM, Bidirectional
from sklearn.feature_extraction.text import CountVectorizer
import nltk
from nltk.corpus import stopwords
from nltk.stem import SnowballStemmer
nltk.download('stopwords')
# Parámetros configurables
N = 20000 # Número de palabras del diccionario
T = 100 # Longitud prefijada de la reseña
EPOCHS = 10
NEURONAS_CAPA = 128
# Stop words: podemos generarlas con NLTK o crear una lista propia offline
# stop_words = stopwords.words('english')
stop_words=['a', 'about', 'an', 'and', 'as', 'at', 'be', 'because', 'been',
'being', 'by', 'during', 'each', 'for', 'from', 'he', 'he\'d', 'he\'ll',
'he\'s', 'her', 'him', 'his', 'how', 'i', 'i\'d', 'i\'ll', 'i\'m', 'i\'ve',
'if', 'in', 'into', 'it', 'it\'s', 'its', 'let', 'let\'s', 'll', 'of', 'or',
'our', 'out', 'over', 're', 'same', 'she', 'she\'d', 'she\'ll', 'she\'s',
'so', 'some', 'such', 'than', 'that', 'that\'s', 'the', 'them', 'then',
'there', 'these', 'they', 'they\'d', 'they\'ll', 'they\'re', 'they\'ve',
'this', 'those', 'through', 'to', 'until', 've', 'very', 'we', 'we\'d',
'we\'ll', 'we\'re', 'we\'ve', 'what', 'what\'s', 'when', 'when\'s', 'where',
'where\'s', 'which', 'while', 'who', 'who\'s', 'whom', 'why', 'why\'s',
'with', 'would', 'wouldn', 'wouldn\'t', 'you', 'you\'d', 'you\'ll', 'you\'re',
'you\'ve', 'your', 'yours']
# Lematizador
stemmer = SnowballStemmer('english')
# Funciones auxiliares
def stem_tokenizer(texto):
...
# Genera el diccionario de raíces más habituales
def generar_diccionario(textos, N):
...
# Función auxiliar para, dada una cadena, convertirla en una secuencia de
# códigos según el diccionario aportado, hasta un tamaño máximo de T códigos
def procesar_cadena(texto, diccionario, stop_words, T):
...
Ahora vamos a leer el CSV de entrada, procesar la columna con las reseñas y convertir cada reseña en una secuencia de T = 100 códigos, según el diccionario que generaremos con las propias reseñas.
datos = pd.read_csv('tripadvisor_hotel_reviews.csv')
# Variable objetivo
y = datos.iloc[:, -1]
num_clases = len(y.unique())
# Codificamos con "one hot" las posibles categorías finales
y = pd.get_dummies(datos['Rating'], columns=['Rating'])
# Textos de reseñas
textos = datos['Review']
X = []
diccionario = generar_diccionario(textos, stop_words, N)
for texto in textos:
X.append(procesar_cadena(texto, diccionario, stop_words, T))
# X contendrá las reseñas codificadas y rellenas con la misma longitud
X = np.array(X)
Ya estamos en disposición de crear y entrenar la red. Nuestros datos de entrada serán los de la variable X, y la columna objetivo la tenemos almacenada en la variable y (columna Rating codificada en one hot).
modelo = Sequential()
modelo.add(Input((X.shape[1], 1)))
modelo.add(LSTM(units=NEURONAS_CAPA, return_sequences=True))
modelo.add(Bidirectional(LSTM(units=NEURONAS_CAPA)))
modelo.add(Dense(units=num_clases, activation='softmax'))
modelo.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
modelo.fit(X, y, validation_split=0.2, epochs=EPOCHS, batch_size=128)
Nota
Observa que las capas recurrentes son bidireccionales (salvo la primera). Esto es habitual (y recomendable) en procesamiento de textos, ya que el análisis de palabras posteriores en la secuencia puede influir en la valoración de palabras analizadas previamente.
Si lanzamos el entrenamiento, veremos que se alcanza una exactitud en torno al 50%. No está del todo mal, teniendo en cuenta que hay 5 categorías diferentes, lo que daría una probabilidad de acierto por azar del 20%. Sin embargo, la red no es todo lo buena que podría, entre otras cosas, porque la codificación word encoding tiene sus limitaciones. Por ejemplo, la red aprende que hay palabras "mejores" o "peores" que otras en función de su código numérico y, además, dos palabras con significados similares, como podrían ser "increíble" y "maravilloso", podrían tener códigos muy diferentes, lo que hace difícil que la red las asocie. Veremos cómo evitar este problema con el encaje de palabras (word embedding) a continuación.
Ejercicio 4
Utiliza este dataset sobre asociaciones entre preguntas, basado en este reto de Kaggle. En cada línea aparecen los textos de dos preguntas y un resultado (1 o 0) que indica si las dos preguntas tratan sobre el mismo contenido u objetivo final. Vamos a construir una red recurrente que, usando word encoding, entrene con el dataset proporcionado para aprender a asociar preguntas.
4.2.3. Ejemplo de red recurrente con word embedding¶
Para trabajar con la técnica del word embedding, Keras pone a nuestra disposición la clase Embedding del paquete keras.layers. Con ella añadiremos una capa más que procesará la entrada (secuencia de palabras ya codificadas) y las transformará en vectores de la dimensión que elijamos. Recibirá como entrada un código del vocabulario y devolverá su representación en forma de vector. Para ello, emplearemos dos parámetros:
input_dim: tamaño del vocabulario de entrada (variableNusada en ejemplos anteriores)output_dim: tamaño de los vectores que se quieren generar (configurable)
Vamos a poner un ejemplo simple para comprender cómo funciona esta capa: imaginemos un tamaño de vocabulario de N = 5 palabras, y queremos vectorizarlas en vectores de tamaño D = 8. Vamos a "simular" la construcción de un modelo con una capa de embedding que haga este trabajo:
import numpy as np
from keras.models import Model
from keras.layers import Input, Embedding
N = 5
D = 8
# Capa de entrada ficticia para la red. Le pasamos 10 códigos numéricos
capa_entrada = Input(shape=(10,), dtype='int32')
# Añadimos la capa de embedding
embedding = Embedding(input_dim=N, output_dim=D)(capa_entrada)
# Creamos un modelo a partir de estas dos capas
modelo = Model(capa_entrada,embedding)
modelo.summary()
# Probamos a 'predecir' a través de esta red
# Una frase de 10 códigos del 0 al 4 (N = 5)
codificacion_entera = [4,1,3,3,3,4,1,2,0,1]
codificacion_embedding = modelo.predict(np.asarray([codificacion_entera]))
print()
print('Representación de {}'.format( str(codificacion_entera) ))
print(codificacion_embedding)
La salida vectorizada que obtendremos para la entrada de las palabras [4,1,3,3,3,4,1,2,0,1] será algo así:
Representación de [4, 1, 3, 3, 3, 4, 1, 2, 0, 1]
[[[ 0.03018123 0.00643995 0.01006697 0.04564729 0.0336056
-0.00224669 0.02171426 -0.04645901]
[-0.01138139 0.04232264 0.0221484 0.04390368 -0.00368824
-0.00901617 0.0044185 0.02825235]
[-0.01859012 -0.00629542 -0.03538439 0.00934307 -0.01918806
-0.046248 0.01426477 0.00069664]
[-0.01859012 -0.00629542 -0.03538439 0.00934307 -0.01918806
-0.046248 0.01426477 0.00069664]
[-0.01859012 -0.00629542 -0.03538439 0.00934307 -0.01918806
-0.046248 0.01426477 0.00069664]
[ 0.03018123 0.00643995 0.01006697 0.04564729 0.0336056
-0.00224669 0.02171426 -0.04645901]
[-0.01138139 0.04232264 0.0221484 0.04390368 -0.00368824
-0.00901617 0.0044185 0.02825235]
[-0.01592133 -0.02350215 0.03656745 0.01110729 -0.01417758
-0.04995153 0.03740096 0.00377519]
[ 0.01246772 0.01444924 -0.03695682 -0.02290478 -0.03107561
-0.00191031 -0.04281888 -0.02300755]
[-0.01138139 0.04232264 0.0221484 0.04390368 -0.00368824
-0.00901617 0.0044185 0.02825235]]]
Así, la palabra codificada como 4 se representará con el vector [0.03018123 0.00643995 0.01006697 0.04564729 0.0336056 -0.00224669 0.02171426 -0.04645901], y así sucesivamente. Estos vectores se ajustan poco a poco, de forma convencional para el entrenamiento en redes neuronales.
Transformaremos ahora el ejemplo anterior de reseñas de TripAdvisor usando word embedding, para comprobar si esta técnica ofrece mejores resultados. En cuanto a cambios importantes, debemos importar la capa Embedding junto a las demás...
from keras.layers import Input, Dense, Dropout, LSTM, Bidirectional, Embedding
... y declaramos la variable D con el número de dimensiones que queremos que tengan los vectores (podemos hacer varias pruebas con varios valores para dar con uno apropiado).
N = 20000
T = 100
D = 128 # Dimensiones de los vectores de embedding
EPOCHS = 10
NEURONAS_CAPA = 128
El siguiente cambio viene en la definición del modelo, añadiendo una capa Embedding en la entrada:
modelo = Sequential()
# Cambiamos la dimensión de entrada para hacerla compatible con Embedding
# Debe ser unidimensional (número de códigos de cada frase: X.shape[1] o T)
modelo.add(Input((T,)))
# Añadimos 2 unidades más al tamaño para incluir los códigos de
# palabras desconocidas y de padding
modelo.add(Embedding(input_dim=N+2, output_dim=D))
modelo.add(LSTM(units=NEURONAS_CAPA, return_sequences=True)))
modelo.add(Bidirectional(LSTM(units=NEURONAS_CAPA)))
modelo.add(Dense(units=num_clases, activation='softmax'))
modelo.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
modelo.fit(X, y, validation_split=0.2, epochs=EPOCHS, batch_size=128)
En este caso es fácil caer en el overfitting, con una exactitud de más del 90% en el conjunto de entrenamiento y de menos del 60% en el de test. Ajustando el número de capas, el dropout y el número de neuronas por capa se puede reducir parcialmente ese overfitting, con una exactitud cercana al 70%.
Aquí puedes descargar los ejemplos sobre el dataset de TripAdvisor, tanto con word encoding como con word embedding.
Ejercicio 5
Transforma la red recurrente del ejercicio anterior en otra que utilice word embedding para la misma tarea
4.2.4. Otras mejoras aplicables¶
El proceso anterior puede funcionar correctamente para muchos casos de procesamiento del lenguaje. Sin embargo, tiene algunos problemas que podemos intentar subsanar. Por ejemplo, hacer un padding o rellenado general en todo el conjunto de datos puede resultar ineficiente si las entradas tienen tamaños muy dispares. Demasiados códigos de padding pueden alterar significativamente el aprendizaje de la red.
Para evitar este problema podemos aplicar distintas alternativas:
- Podemos aplicar un padding por lotes, a través de lo que se llaman funciones generadoras. En este caso, definimos un tamaño de lote B, y la función se encarga de, a partir del conjunto de entradas X, irlas agrupando en bloques de B entradas, y aplicar un padding a ese bloque de acuerdo al tamaño de las entradas de ese bloque nada más. Esto permitirá, además, que la red pueda entrenar con entradas de longitud variable, ya que cada lote podrá tener un tamaño diferente.
- Complementar la técnica anterior con otra llamada bucketting. Consiste en ordenar el conjunto X de entrada por tamaño, para que luego los lotes de tamaño B agrupen entradas de tamaño similar, y se reduzcan aún más los caracteres de padding necesarios.
5. Transfer learning para redes recurrentes¶
En documentos anteriores ya explicamos el concepto de transfer learning, y vimos que consiste en re-entrenar parcialmente un modelo ya definido para utilizarlo en otro contexto diferente, a grandes rasgos.
En el ámbito de las redes recurrentes también podemos aplicarlo. Por ejemplo, el análisis de textos o procesamiento del lenguaje es una tarea algo tediosa en ocasiones, en lo que se refiere al procesamiento previo de los textos para convertirlos en secuencias de códigos (word encoding) o incluso en vectores de códigos (word embedding), como ya hemos visto antes. Sin embargo, podemos valernos del transfer learning para incorporar ya un modelo de embedding específico, y construir con él otro modelo propio.
En la red existen multitud de modelos pre-entrenados para hacer esta tarea de word embedding. Podemos utilizar cualquiera de ellos como punto de entrada a nuestro modelo. Vamos a utilizar en este ejemplo este modelo entrenado sobre noticias de Google News. Podemos ver cómo vectoriza contenido muy sencillamente, con un ejemplo como éste (necesitamos tener instalado el paquete tensorflow_hub):
import tensorflow_hub as hub
embed = hub.load("https://www.kaggle.com/models/google/nnlm/TensorFlow2/tf2-preview-en-dim50/1")
embeddings = embed(["cat is on the mat", "dog is in the fog"])
Como podemos ver si ejecutamos el ejemplo anterior y echamos un vistazo a la variable embeddings, se vectoriza cada frase en 50 elementos. Cada elemento de estos vectores de embedding representa una característica, y su valor representa la importancia de esa característica para esa palabra o frase. Podemos utilizar también un modelo que genera vectores de 128 elementos, cambiando 50 por 128 en la URL anterior. A partir de aquí, podemos tomar este modelo como capa de entrada de nuestra red.
Si queremos conectar la capa de embedding importada con capas LSTM, necesitamos redimensionar el conjunto X de entrada previo. Suponiendo que X tenga un array de textos, podríamos hacer algo así:
hub_layer = hub.KerasLayer("https://www.kaggle.com/models/google/nnlm/TensorFlow2/tf2-preview-en-dim50/1",
input_shape=[], dtype=tf.string, trainable=True)
# Convertimos los textos en vectores de códigos numéricos
# Con esto conseguimos que X tenga 2 dimensiones:
# - Número de textos
# - Número de códigos por texto (50 en este caso)
X = hub_layer(X)
modelo = keras.Sequential()
modelo.add(Input((X.shape[1], 1)))
modelo.add(keras.layers.LSTM(units=128, return_sequences=True))
modelo.add(keras.layers.Bidirectional(keras.layers.LSTM(units=128)))
...
Ejercicio 6
Utiliza el modelo de embedding visto en el ejemplo anterior para entrenar una red que prediga si un tuit trata de un desastre real, usando este dataset.