Modelos y servicios de Azure¶
En este documento explicaremos los modelos disponibles en la nube de Azure. Estos modelos nos permitirán realizar tareas como identificar elementos en imágenes, clasificarlas, detectar texto, y también analizar texto escrito, interpretarlo, sintetizar voz y otras tareas.
1. Primeros pasos con Azure¶
Para poder utilizar los servicios de Azure debemos acceder a su portal. Tendremos que crear una cuenta si no tenemos ninguna creada. En caso de ser estudiantes en algún centro registrado, podemos darnos de alta a través del centro en el programa de Azure para estudiantes, que proporciona un crédito inicial y acceso gratuito a ciertos servicios de la nube, sin necesidad de dar datos de pago. Si optamos por esta opción, podemos consultar datos generales de la plataforma para estudiantes en la sección de Education, desde el portal.
También desde el buscador superior podemos buscar por Suscripciones y consultar el tipo de suscripción que tenemos activa actualmente.
1.1. Azure AI¶
Azure AI es un compendio de servicios pre-entrenados centrados en tareas de visión, audio y procesamiento del lenguaje. Esto aporta ciertas ventajas al desarrollador, como la posibilidad de usar aplicaciones inteligentes sin tener demasiadas nociones sobre cómo desarrollarlas, y el hecho de que Microsoft se encargue de su mantenimiento y mejora. Evidentemente, el uso de estos servicios supondrá un coste para quien los emplea, y no vamos a tener mucho control sobre ellos, en cuanto a la posibilidad de ajustar los modelos.
Existen distintos servicios ofrecidos, agrupados por categorías. Lo que haremos será aprovisionar los servicios. En algunos casos, los servicios requerirán la creación de un portal específico para poderlos configurar, como es el caso de Custom Vision. El funcionamiento general es similar al uso de modelos pre-entrenados en otras plataformas, como OpenAI o Pretrained.ai: dejaremos nuestro servicio configurado en un endpoint o URL de acceso, y lo consumiremos mediante llamadas a su API. Alternativamente, Microsoft proporciona una serie de SDK (Software Development Kit) que encapsulan estas peticiones en clases, para distintos lenguajes de programación.
2. Servicios de visión¶
En lo que se refiere a servicios y modelos de visión, éstos permiten realizar tareas como el reconocimiento facial, identificación de textos en imágenes o formularios, búsqueda en vídeos, etc.
2.1. Características generales de los servicios de visión¶
En estos apuntes emplearemos distintos modelos y servicios ofrecidos por Azure para el procesamiento de imágenes, que se agrupan en dos conjuntos:
- Vision, para tareas diversas como análisis de imágenes, reconocimiento de caras, o de texto en imágenes. En versiones anteriores a este servicio se le conocía como Computer Vision
- Custom Vision, para personalizar nuestro propio sistema de clasificación o identificación.
En todos existen unas características comunes:
- Se admiten imágenes en distintos formatos (JPG, GIF, PNG o BMP), bien proporcionando la URL de la imagen o los datos binarios de la imagen
- Existe un tamaño máximo para la imagen a procesar: 4 MB en el caso del servicio Vision o Computer Vision, y 6 MB para Custom Vision.
- La resolución mínima de la imagen debe ser al menos de 50x50 píxeles
- En el caso de servicios de identificación de textos escritos, también se admiten ficheros PDF o TIFF, con hasta 2.000 páginas (sólo 2 en la capa gratuita) y 50 MB de tamaño (sólo 4 MB para la capa gratuita).
2.2. El servicio Computer Vision de Azure AI¶
Este servicio comprende un conjunto de operaciones sobre imágenes, como por ejemplo el análisis de imágenes (detectar distintos elementos en una imagen), detección de áreas de interés en la imagen, reconocimiento de texto escrito, etc.
2.2.1. Análisis de imágenes¶
La modalidad de análisis de imágenes es el modo de uso más elemental del servicio Computer Vision, a partir del cual obtenemos información general de la imagen: categoría general a la que pertenece (dentro de un subconjunto limitado de categorías), lista de objetos identificados, descripción general de la imagen, etc. Aquí tenemos un enlace a la documentación de la API y las opciones que ofrece.
Vamos a ver cómo construir un ejemplo paso a paso. Como decíamos antes, lo primero que tenemos que hacer es aprovisionar el servicio. Para ello debemos ir al portal de Azure con nuestro usuario. En nuestro portal, elegiremos el icono de Crear un recurso:
En el buscador superior elegimos crear un recurso de tipo Computer Vision
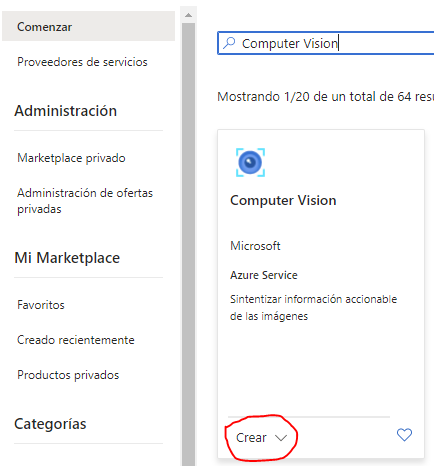
En el formulario posterior debemos asignar el recurso a un grupo (podemos crear uno de prueba). Estos grupos son básicamente carpetas o contenedores que agrupan recursos, y que luego permiten obtener estadísticas de uso por grupo, entre otras cosas. También debemos elegir la región en la que se desplegará (dependiendo de la región tendremos más o menos latencia en el uso, según quiénes sean sus usuarios finales), y le asignaremos un nombre identificativo al recurso. Finalmente, debemos elegir el Plan de tarifa. Al ser un servicio gratuito, es IMPORTANTE que elijamos el plan gratuito, que permite un número limitado (aunque razonable) de llamadas por minuto y mes. De lo contrario, se cargarán las peticiones contra el crédito que tengamos en nuestra cuenta Azure. Es posible que el plan gratuito no esté disponible para la región que elijamos, por lo que deberemos elegir otra. También, dependiendo del servicio, es posible que tengamos que marcar alguna casilla de aceptación de las condiciones del mismo.
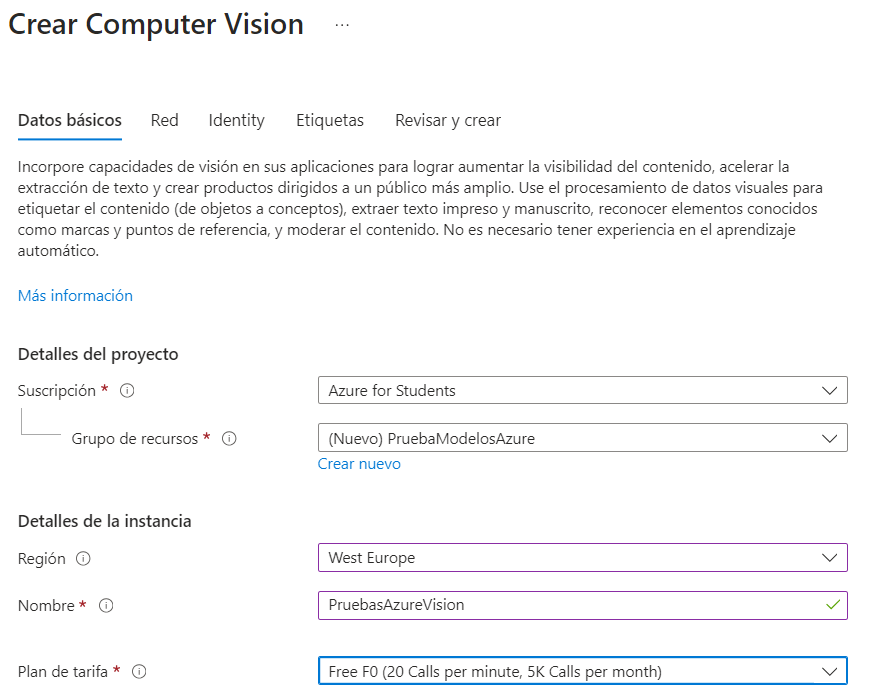
Una vez creado el recurso, podemos ir a su página. En la sección de información general explica los pasos que debemos seguir: en primer lugar debemos obtener la clave (key) para acceder y el punto de conexión o endpoint al que conectar. Después, podemos optar por usarlo a través de llamadas a la API, o bien mediante código en el SDK correspondiente (C#, Python, etc). Para obtener la clave y el punto de conexión debemos ir a la sección Claves y punto de conexión del menú izquierdo. Podemos mostrar la clave, ya que por defecto aparece enmascarada, y también regenerarlas si intuimos que alguien ha accedido a ellas.
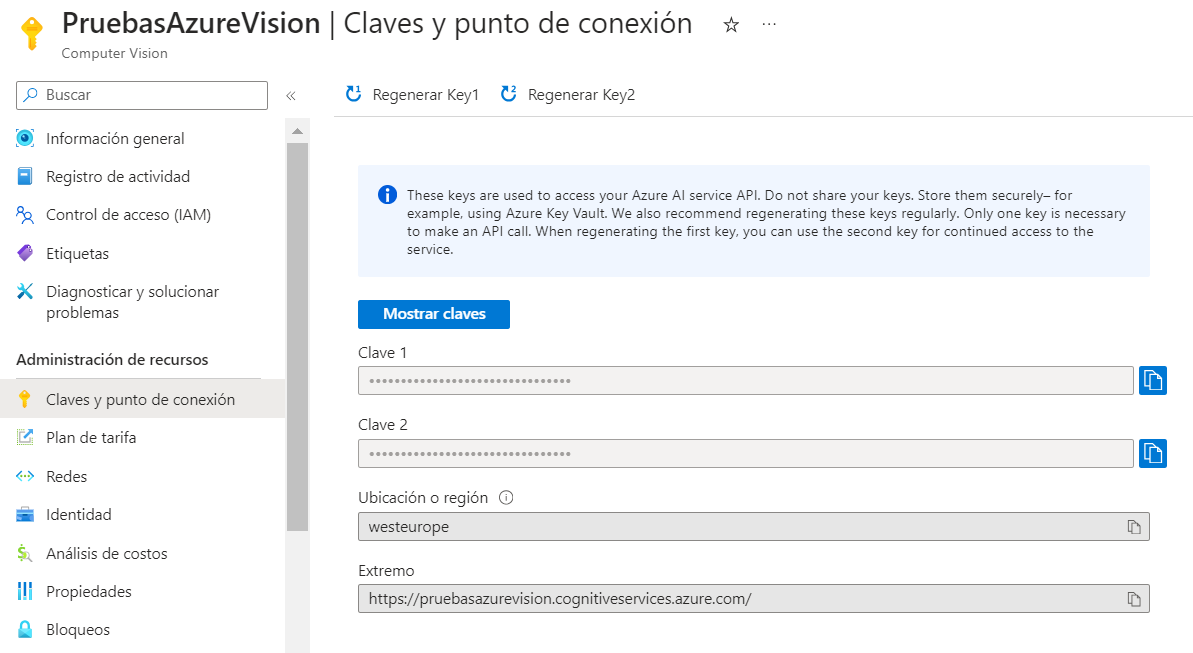
Con esto ya hemos terminado la configuración en el portal de Azure. El resto del trabajo debemos hacerlo en nuestra aplicación. Probaremos con esta imagen de ejemplo para ver cómo la analiza. El código que incorporaremos a nuestro programa en Python puede ser similar a este:
{kind=link}
import requests
# Cambiar esta URL por la de nuestro endpoint
URL = 'https://pruebasazurevision.cognitiveservices.azure.com/computervision/imageanalysis:analyze'
KEY = '...'
with open("ejemplo_analisis_imagen.jpg", "rb") as img:
imagen = img.read()
cabeceras = {"Ocp-Apim-Subscription-Key": KEY,
"Content-Type": "application/octet-stream" }
respuesta = requests.post(URL +
"?api-version=2024-02-01&features=caption,objects",
data=imagen, headers=cabeceras)
respuesta_json = respuesta.json()
print(respuesta_json)
descripcion = respuesta_json['captionResult']['text']
print("Descripción:", descripcion)
for objeto in respuesta_json['objectsResult']['values']:
for etiqueta in objeto['tags']:
print("Identificado", etiqueta['name'], 'con una confianza de',
etiqueta['confidence'])
En este caso, hemos pedido que nos devuelva la descripción de la imagen y los objetos que identifica, para luego procesarlos en el contenido JSON de respuesta y mostrarlos por pantalla. Además, en las cabeceras de la petición tenemos que indicar el tipo de contenido (JSON para enviar URL de imagen, o contenido binario si enviamos la imagen codificada en bytes) y el token o clave de autenticación. En el cuerpo de la petición enviaremos la URL o los bytes de la imagen a analizar.
Note
Dependiendo de los valores que pongamos en el parámetro features de la URL es posible que sólo podamos utilizar el idioma inglés. Por ejemplo, los tags están soportados en muchos idiomas, pero los objetos encontrados no. Aquí podemos consultar qué cosas se admiten en cada idioma.
Uso mediante el SDK de Python
Alternativamente a la llamada mediante API REST podemos emplear las clases proporcionadas por el SDK para Python. Aquí tenemos una guía de cómo hacerlo. El primer paso es común (crear el recurso de Computer Vision en el portal de Azure y obtener el endpoint y la clave), lo que cambia es la forma que desde el cliente accedemos a esa URL.
En este caso deberemos instalar en nuestro sistema la librería azure-ai-vision-imageanalysis.
pip install azure-ai-vision-imageanalysis
Después construimos un programa que resuelva el mismo caso anterior, usando este SDK. Empleamos para ello las clases ImageAnalysisClient (que crea el cliente de conexión), VisualFeatures (que aglutina los parámetros que queremos extraer de la imagen) y AzureCredential (que almacena las credenciales para acceder al endpoint).
from azure.ai.vision.imageanalysis import ImageAnalysisClient
from azure.ai.vision.imageanalysis.models import VisualFeatures
from azure.core.credentials import AzureKeyCredential
# Cambiar esta URL por la de nuestro endpoint
URL = 'https://pruebasazurevision.cognitiveservices.azure.com'
KEY = '...'
with open("ejemplo_analisis_imagen.jpg", "rb") as img:
imagen = img.read()
# Creamos el cliente
client = ImageAnalysisClient(
endpoint=URL,
credential=AzureKeyCredential(KEY)
)
# Llamamos al endpoint y obtenemos el resultado con las "features" elegidas
resultado = client.analyze(
image_data=imagen,
visual_features=[VisualFeatures.CAPTION, VisualFeatures.OBJECTS]
)
# Procesamos cada resultado solicitado
if resultado.caption is not None:
print("Caption:")
print(f"{resultado.caption.text}, Confianza {resultado.caption.confidence:.4f}")
if resultado.objects is not None:
print("Objetos:")
for object in resultado.objects.list:
print(f"{object.tags[0].name}, Confianza: {object.tags[0].confidence:.4f}")
Notar que, en este caso, ya no tenemos que proporcionar en la URL datos del servicio a utilizar ni de los parámetros que buscamos. Todo eso ya lo envía el cliente ImageAnalysisClient.
Ejercicio 1
Utiliza el servicio de análisis de imágenes para leer los textos que se encuentren en una imagen (consulta en la página de documentación qué parámetros pasar al servicio). Puedes utilizar esta imagen, que también puedes descargar aquí
{kind=link}
{kind=link}
Tip
Si quieres enviar la URL remota de la imagen al servicio debes construir un diccionario con los datos a enviar, por ejemplo datos_json = {'url': 'https://...'} y luego usar el parámetro json para pasarlo en la llamada post, en lugar de usar el parámetro data. Quedaría json=datos_json.
2.2.2. El servicio Face¶
El servicio Face es un servicio de detección de caras, que ofrece varias modalidades de uso: identificación y delimitación de caras en imágenes, incluyendo algunos atributos como género o edad estimada, búsqueda de caras similares a una dada, agrupación de caras, etc.
Actualmente es un servicio de uso restringido, y sólo permite ser utilizado con un permiso expreso de Microsoft, por lo que existen ciertas limitaciones, y no lo veremos en este documento. En cuanto a los requisitos, Face admite imágenes en distintos formatos, como los servicios de visión en general, bien proporcionando la URL o los datos binarios de la imagen. El tamaño máximo de imágenes es de 6 MB, y permite identificar hasta 100 caras por imagen. Podemos encontrar más información en la documentación oficial de Face
2.3. El servicio Custom Vision de Azure AI¶
El servicio de Custom Vision nos va a permitir definir un modelo de procesado de imágenes ad hoc, para un propósito específico. El servicio permite subir las imágenes con las que entrenar el modelo, definir los parámetros de entrenamiento y, con el modelo ya entrenado, definir la URL de acceso al mismo. Para la primera etapa, la de entrenamiento, emplearemos el portal específico que ofrece Azure, www.customvision.ai, entrando con el mismo usuario de nuestra cuenta Azure.
Lo que haremos será crear proyectos, donde definiremos los criterios de entrenamiento y dejaremos, finalmente, el sistema entrenado y listo. Podemos configurar diferentes proyectos Custom Vision, aunque en el uso gratuito el número de proyectos está limitado. Una vez entrenado y puesto a disposición, podemos utilizarlo para emitir predicciones, consultando a la API que se nos facilite. Tendremos que indicar como parámetros los datos del proyecto en cuestión. En las cabeceras de petición enviaremos el tipo de contenido (similar al resto de modelos pre-entrenados de uso de imágenes) y la clave que también se nos proporcionará. En el cuerpo enviaremos la imagen a predecir codificada en bytes o la URL de acceso a la misma. Como resultado obtendremos una lista con las etiquetas asignadas a la imagen (tagName) y la probabilidad o grado de certeza de cada etiqueta.
Aquí tenemos la documentación general del servicio Custom Vision.
Vamos a desarrollar un proyecto que aprenda a distinguir entre los tipos de comida presentes en este dataset de imágenes. Lo primero que tenemos que hacer es crear un nuevo recurso en el portal de Azure, de tipo Custom Vision. En el formulario para rellenar la información del recurso, ahora tendremos que especificar algún dato más:
- Para qué vamos a usar el recurso: aprendizaje (entrenamiento), predicción o ambas cosas (valor por defecto). Será útil distinguir una cosa u otra si dividimos la tarea en dos equipos, uno especializado en IA (que lo creará para entrenamiento) y otro que lo utilizará después (desde predicción).
- También debemos indicar el plan de tarifa para las dos etapas (aprendizaje y predicción). En el desplegable aparecerán las limitaciones ofrecidas en el plan gratuito en uno u otro caso.
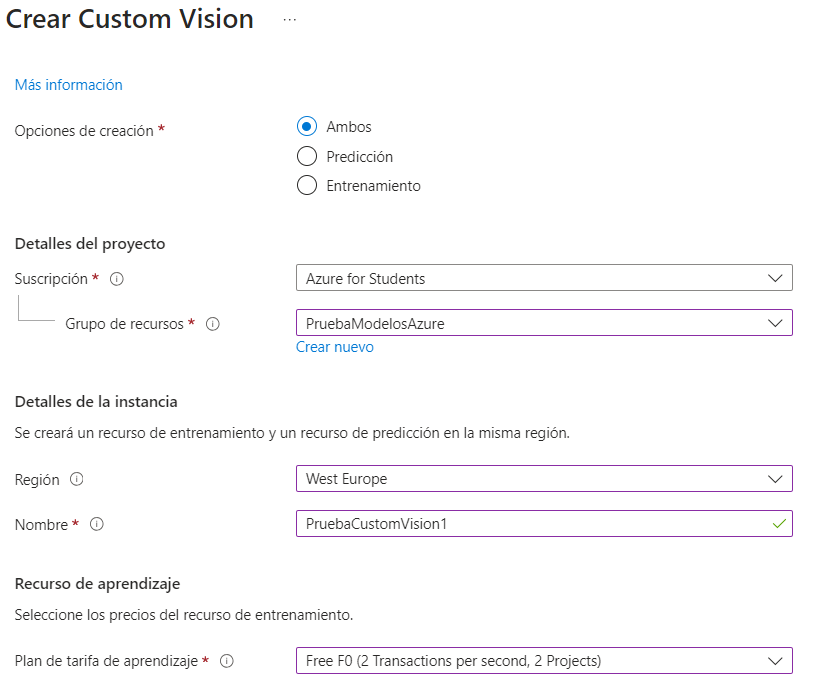
Al finalizar el proceso de creación podremos ver que, en realidad, se han creado dos recursos: uno para aprendizaje y otro para predicción:
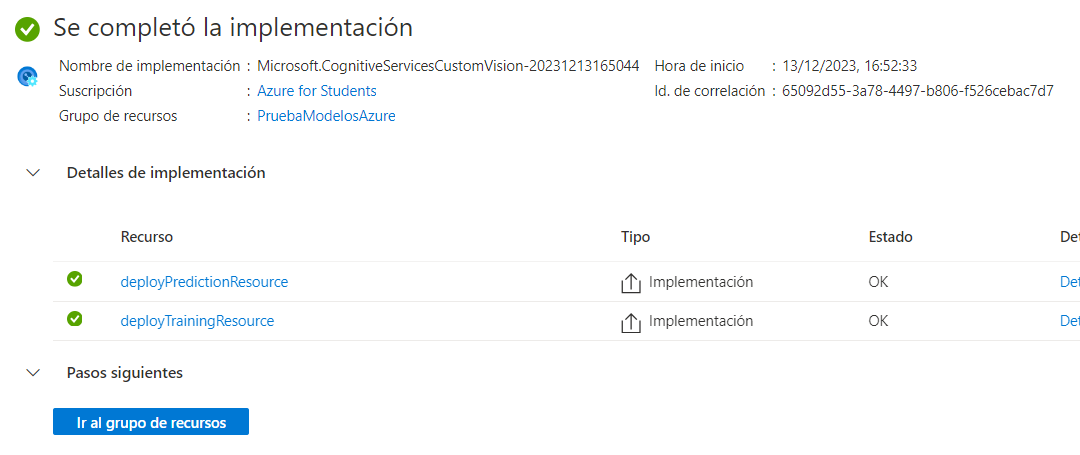
El siguiente paso será ir al portal de Custom Vision e identificarnos para entrenar el modelo. Tendremos que crear un proyecto para empezar con nuestro modelo (recuerda la limitación del número de proyectos para la capa gratuita):
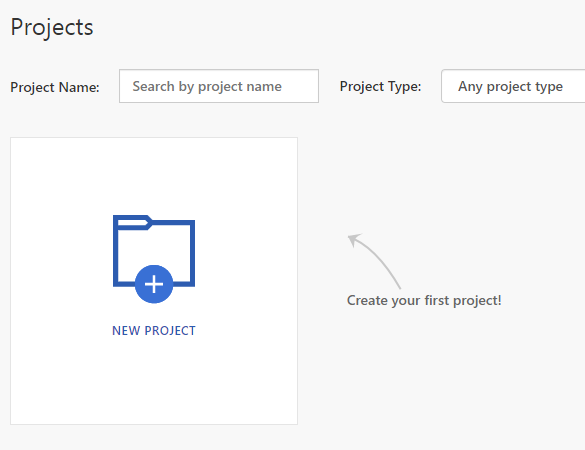
En el formulario para crear el proyecto deberemos asignarle un nombre (en nuestro caso, por ejemplo, Comidas), una descripción (no obligatoria) y asociarlo al recurso que hemos creado previamente en el portal de Azure. Además, tendremos que indicar el propósito del proyecto (clasificación de imágenes o detección de objetos) y también el tipo concreto. En nuestro caso, es un modelo para clasificación de imágenes, con una única etiqueta por imagen. También podemos elegir si vamos a abarcar un dominio específico, como comida (como es nuestro caso).
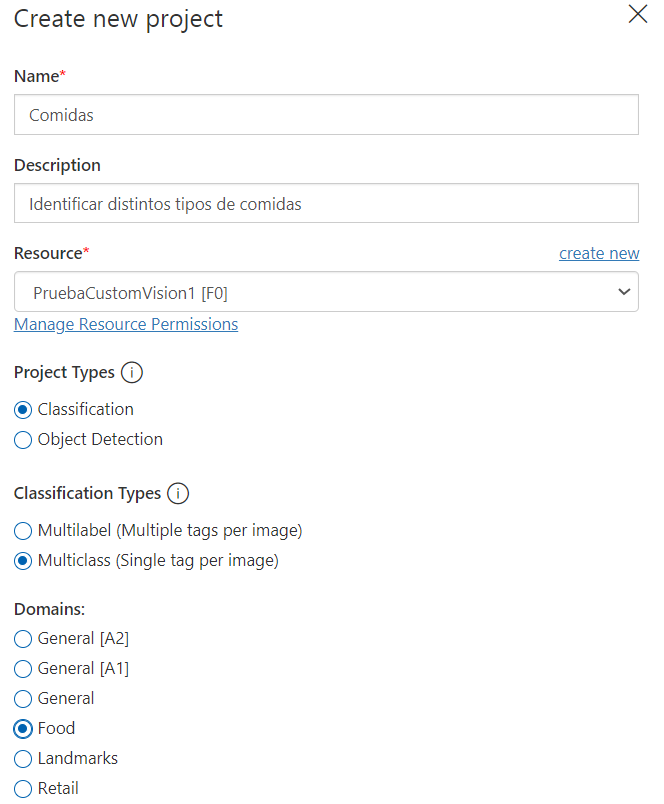
A continuación debemos añadir imágenes al proyecto para que pueda entrenar con ellas. A la hora de subirlas, podemos hacerlo por bloques, y en cada bloque tendremos que indicar a qué categoría pertenecen:
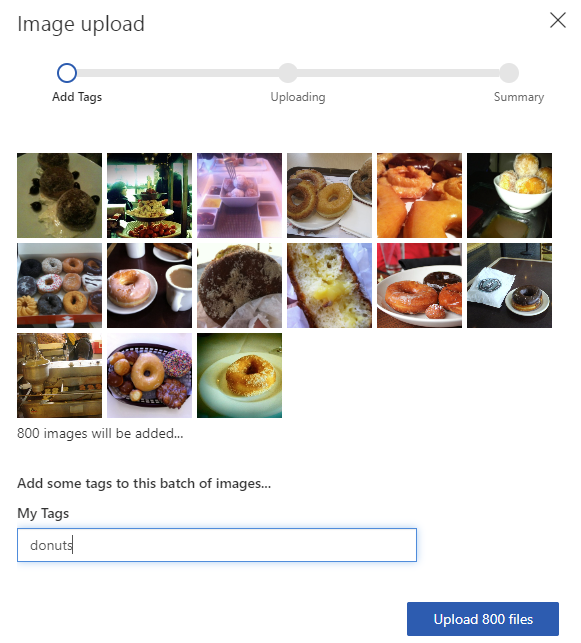
Tras subir las imágenes etiquetadas, ya podemos entrenar el modelo con el botón de Train. Podemos elegir entre un entrenamiento rápido o uno avanzado, dependiendo del tiempo que queramos dedicar a ese entrenamiento. Al finalizar obtendremos las estadísticas, y podremos ver cómo la plataforma etiqueta cada entrenamiento con un número de iteración. De este modo, si más adelante añadimos nuevas imágenes, o nuevas etiquetas, podemos lanzar un nuevo entrenamiento, y se le asignará otro número de iteración. Las tendremos todas disponibles en la sección Performance del proyecto y, a la hora de evaluar la predicción del modelo, deberemos proporcionar el número de iteración con el que queremos hacer la predicción, de entre los que tengamos disponibles. Esto permite tener un modelo utilizado en producción y luego seguir haciendo pruebas y mejoras en otras iteraciones posteriores, hasta dar con alguna que pongamos en producción sustituyendo a la anterior.
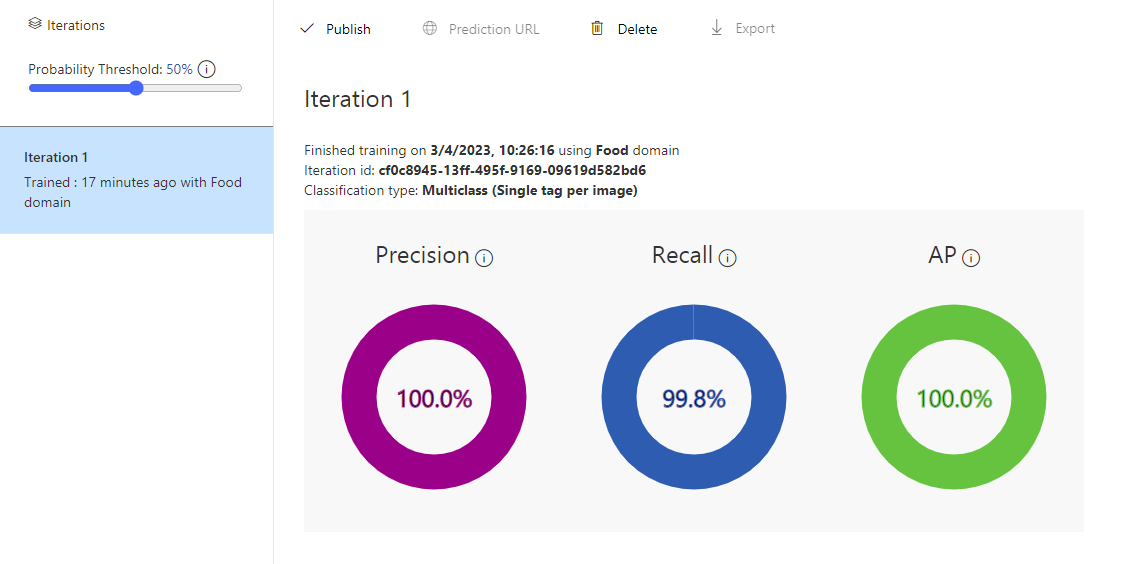
Con el botón Quick Test podemos hacer una prueba rápida del modelo, subiendo una imagen local o proporcionando una URL de imagen a probar. Una vez entrenado, el siguiente paso será publicar el modelo para poder acceder al recurso vía API REST y enviarle peticiones. Hacemos clic para ello en el botón Publish sobre la iteración (ver imagen anterior), y tendremos que elegir el nombre que tendrá la iteración (lo usaremos desde la llamada a la API) y a qué recurso de Azure lo vinculamos (al recurso de predicción asociado al anterior recurso de entrenamiento):
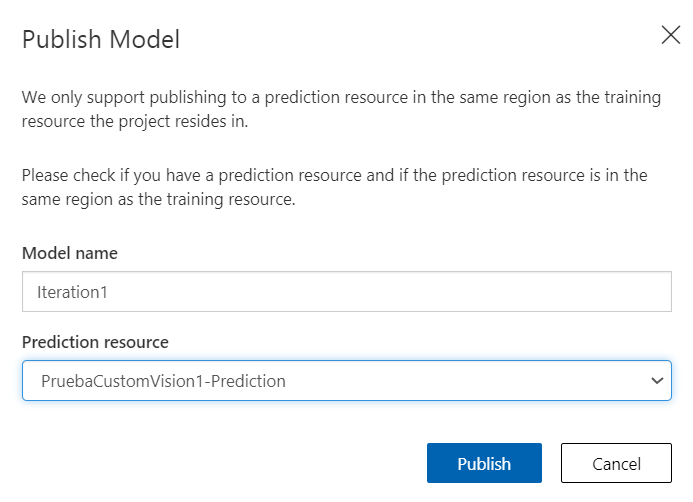
Después de la publicación, tendremos disponible la URL para hacer la petición en el enlace Prediction URL, también sobre la iteración (ver imagen anterior).
Ejercicio 2
Crea un programa en Python que conecte con el modelo entrenado en Custom Vision y le facilite una imagen de prueba para que la catalogue. Puedes utilizar, por ejemplo, alguna de estas imágenes. Averigua la estructura de la respuesta JSON proporcionada para dar un mensaje apropiado al usuario (no simplemente el contenido JSON). Por ejemplo:
Resultado predicción:
Donuts: 99.6%
Guacamole: 0.0%
Nachos: 0.4%
3. Servicios de tratamiento de texto (Lenguaje)¶
Los servicios de tratamiento de texto permiten hacer diversas operaciones sobre un texto, como por ejemplo analizar su sentimiento u opinión, extracción de palabras clave, detección de idioma, etc.
Para ello emplearemos el servicio de lenguaje, cuya documentación general podemos encontrar aquí. Por ejemplo, vamos a probarlo en el análisis de opinión: le proporcionaremos un texto y nos catalogará la opinión emitida en ese texto como positiva, neutra o negativa. Se permite enviar varios textos a la vez (cada uno con una limitación de algo más de 5.000 caracteres como mucho), y obtener una respuesta para cada texto. En todo caso, la petición en su conjunto no puede exceder de 1 MB de tamaño. Aquí tenemos documentación concreta sobre ese análisis de sentimiento.
Crearemos, por tanto, un nuevo recurso en el portal de Azure de tipo Lenguaje, con el nombre que queramos.

Nota
No es necesario que elijamos ningún elemento personalizado (Custom), ya que de lo contrario se necesitará un espacio de almacenamiento para el entrenamiento del modelo, con su correspondiente recargo.
Advertencia
En versiones antiguas de Azure, este servicio se llamaba Análisis de texto (Text Analytics), pero en versiones recientes lo han integrado en el nuevo servicio de lenguaje.
Podemos plantear un programa en Python sencillo como éste, que le pide al usuario varias opiniones (hasta que escriba una cadena vacía), las envía al servicio y recoge la respuesta:
import requests
# Cambiar URL y KEY por las nuestras propias
URL = 'https://pruebalenguaje.cognitiveservices.azure.com/language/:analyze-text?api-version=2023-04-15-preview'
KEY = '...'
opiniones = []
opinion = " "
contador = 0
while opinion != "":
opinion = input("Escribe una opinion. Cadena vacía para terminar:\n")
if opinion != "":
contador += 1
opiniones.append({'language': 'es', 'id': contador,
'text': opinion})
cabeceras = {"Ocp-Apim-Subscription-Key": KEY,
"Content-Type": "application/json" }
contenido = {
'kind': 'SentimentAnalysis',
'parameters': {
'modelVersion': 'latest',
'opinionMining': 'True'
},
'analysisInput': {
'documents': opiniones
}
}
respuesta = requests.post(URL, json=contenido, headers=cabeceras)
respuesta_json = respuesta.json()
contador = 0
for resultado in respuesta_json['results']['documents']:
contador += 1
print("Resultados reseña", contador, ":")
print(resultado['sentiment'])
print("Positivo:", resultado['confidenceScores']['positive'])
print("Neutro:", resultado['confidenceScores']['neutral'])
print("Negativo:", resultado['confidenceScores']['negative'])
print("-------")
Ejercicio 3
Crea un programa en Python que le pida al usuario que escriba un texto y utiliza el servicio de palabras o frases clave para que detecte las frases clave de dicho texto. Puedes consultar aquí más información sobre este servicio.
4. El servicio de voz (Speech)¶
Los servicios de voz de Azure AI agrupan un conjunto de tareas, como la transcripción en tiempo real de voz a texto (y viceversa), el reconocimiento del hablante, o la traducción de la voz, entre otras cosas. El formato de audio que se gestionará en todo caso serán ficheros WAV, o bien físicos o bien a través de streams en memoria. Aquí disponemos de documentación general.
A diferencia de otros servicios de Azure AI, donde se puede utilizar indistintamente las llamadas a la API o el SDK específico de un lenguaje, en el caso de los servicios de voz algunas funcionalidades no están disponibles en modo API, y se recomienda usar el SDK. Aquí, por ejemplo, se explican las nociones para usar el SDK de Python para síntesis de voz.
Comenzaremos, como siempre, por aprovisionar el servicio. Crearemos un nuevo recurso de voz (Speech):
Tendremos que instalar el paquete azure-cognitiveservices-speech. Aquí vemos un pequeño ejemplo de uso, donde le pedimos al usuario que escriba un texto e invocamos al servicio para que lo hable:
import azure.cognitiveservices.speech as speechsdk
KEY = '...'
REGION = 'westeurope'
# Configuramos acceso al servicio y opciones de audio
config_speech = speechsdk.SpeechConfig(subscription=KEY, region=REGION)
# Configuramos la salida del audio por el altavoz por defecto del sistema
config_audio = speechsdk.audio.AudioOutputConfig(use_default_speaker=True)
config_speech.speech_synthesis_voice_name='es-ES-AbrilNeural'
sintetizador_speech = speechsdk.SpeechSynthesizer(speech_config=config_speech,
audio_config=config_audio)
# Recogemos el texto del usuario
texto = input("Escribe lo que quieras decir:\n")
# Invocamos al servicio y recogemos la respuesta
resultado = sintetizador_speech.speak_text_async(texto).get()
if resultado.reason == speechsdk.ResultReason.SynthesizingAudioCompleted:
print("Audio sintetizado para el texto [{}]".format(texto))
elif resultado.reason == speechsdk.ResultReason.Canceled:
detalles_cancelacion = resultado.cancellation_details
print("Audio cancelado: {}".format(detalles_cancelacion.reason))
if detalles_cancelacion.reason == speechsdk.CancellationReason.Error:
if detalles_cancelacion.error_details:
print("Detalles del error: {}".format(detalles_cancelacion.error_details))
El idioma y tipo de voz que hemos elegido en este caso (es-ES-AbrilNeural) se puede configurar y elegir otro idioma o tipo diferente, de los disponibles en la documentación.
Ejercicio 4
Prueba el servicio de Speech To Text con tu micrófono. Di una frase y observa si la transcribe adecuadamente. Aquí tienes una guía rápida de cómo hacerlo.
4.1. Más opciones¶
Observa en los enlaces de documentación de los ejemplos anteriores (en el menú izquierdo) que los servicios de voz de Azure ofrecen muchas otras alternativas, como por ejemplo:
- Traducción de audios
- Identificación del hablante
- Reconocimiento de intención (propósito o intención de lo que se habla)
- ... etc.
5. Servicios de decisión¶
Los servicios de decisión de Azure incluyen tareas como la detección de anomalías o la seguridad de contenidos, entre otras cosas. Echaremos un vistazo al servicio de seguridad de contenidos como ejemplo.
5.1. La seguridad de contenidos¶
El servicio de seguridad de contenidos permite, entre otras cosas, analizar textos o imágenes potencialmente peligrosos para ciertos grupos de población, con el fin de prohibirlos u ocultarlos a la vista. Podemos consultar aquí la documentación general. Como podemos ver, se puede emplear para analizar tanto texto como imágenes.
Lo primero que tenemos que hacer, como en otros casos, es crear el recurso correspondiente:
En la API específica de moderación de textos podemos comprobar que podemos proporcionar distintos parámetros en la petición. Por ejemplo, el parámetro categories permite indicar qué categorías de contenidos estamos buscando (mensajes de odio, violencia...).
Ejercicio 5
Crea un programa Python que utilice el servicio anterior para analizar el texto que le enviemos. Recoge la severidad de cada una de las categorías disponibles para detectar si el mensaje es potencialmente peligroso.