Node.js
Introducción a las aplicaciones web
1. Tipos de aplicaciones
Cuando estamos utilizando un ordenador, una tablet o un teléfono móvil, ¿qué tipos de aplicaciones o programas podemos estar utilizando? Básicamente distinguimos dos grandes grupos:
-
Aplicaciones sin conexión a Internet. Este tipo de aplicaciones no necesitan ninguna conexión a Internet o a una red local de ordenadores para funcionar. Suelen llamarse aplicaciones de escritorio, y podemos encontrar ejemplos muy variados: un procesador de textos, un lector de libros electrónicos, un reproductor de música o vídeo, e incluso videojuegos que tengamos instalados.
-
Aplicaciones con conexión a Internet. Estas aplicaciones sí necesitan conexión, ya sea a Internet o a una red local. Dentro de este grupo, encontramos varios subtipos:
- Aplicaciones P2P (peer-to-peer): todos los elementos conectados a la red tienen el mismo “rango” y comparten información entre ellos. Es el mecanismo en el que se basan varios programas de descarga, como los de archivos tipo torrent.
- Aplicaciones cliente-servidor: consisten en que un conjunto de ordenadores (llamados clientes) se conectan a uno central (llamado servidor), que proporciona la información y los servicios solicitados. Es el caso de los videojuegos online, donde el ordenador del jugador (cliente) se conecta a un servidor central que gestiona el juego. Dentro de las aplicaciones cliente-servidor, hay un subtipo especialmente numeroso, las aplicaciones web. Es en este subtipo en el que nos vamos a centrar.
1.1 ¿Qué es una aplicación web?
Una aplicación web es un tipo de software que se ejecuta en un servidor y se accede a través de un navegador web. El navegador actúa como interfaz entre el usuario y el servidor, donde se procesa la lógica de negocio, se accede a bases de datos y se genera la respuesta que el navegador presenta al usuario.
Con el avance de las tecnologías web, el concepto de aplicación web se ha ampliado. Actualmente, se considera aplicación web a cualquier software desarrollado con tecnologías como HTML, CSS, JavaScript, PHP, etc., que se ejecuta en un navegador o en un entorno que lo emula, como un WebView o un motor de navegador embebido.
WebView es un componente que permite incrustar contenido web dentro de una aplicación móvil nativa. Es común en aplicaciones como Facebook o Instagram, donde se cargan páginas externas sin abrir el navegador del sistema. Aunque su uso es más controlado, ofrece rapidez y cohesión dentro de la app.
1.1.2 Tipos de aplicaciones web modernas
Hoy en día, podemos identificar varios tipos de aplicaciones web modernas según su entorno de ejecución y sus capacidades:
- Aplicaciones híbridas (basadas en WebView): son aplicaciones desarrolladas con tecnologías web y empaquetadas como aplicaciones móviles usando herramientas como Ionic o Capacitor. Se ejecutan dentro de un WebView y gracias a plugins específicos permiten acceder a funcionalidades del dispositivo como cámara, GPS, notificaciones,etc.
- Aplicaciones de escritorio realizadas con tecnologías web: utilizan frameworks como Electron o Tauri para crear aplicaciones de escritorio que funcionan como programas nativos en Windows, macOS o Linux. Combinan un motor web (como Chromium) con acceso al sistema operativo, permitiendo construir interfaces con tecnologías web reutilizando el mismo código base del frontend. Aunque permiten acceso al sistema de archivos y notificaciones, suelen consumir más recursos que una aplicación nativa tradicional. Un ejemplo representativo es Visual Studio Code, desarrollado con Electron.
- Progressive Web Apps (PWA): son aplicaciones web que pueden instalarse desde el navegador y ofrecer funcionalidades típicas de apps nativas, como notificaciones push, acceso sin conexión o ejecución en segundo plano. Un ejemplo destacado es Twitter Lite.
2. Arquitectura de una aplicación web
2.1. ¿Qué es “la web”?
La web es una plataforma global que permite acceder a una gran variedad de contenidos y servicios: páginas informativas, aplicaciones interactivas, redes sociales, foros, vídeos, videojuegos, etc.
Desde sus inicios en los años 90, con páginas estáticas y correo electrónico, ha evolucionado hasta convertirse en una plataforma compleja y dinámica. La llamada Web 2.0 introdujo la participación del usuario (blogs, redes sociales, wikis), y hoy día hablamos incluso de una Web 3.0, más centrada en la descentralización, la inteligencia artificial y la personalización.
2.2. Elementos de una aplicación web
Una aplicación web moderna suele estar compuesta por tres elementos principales que trabajan de forma coordinada:
- Front-end (cliente): es la parte de la aplicación que se ejecuta en el navegador del usuario y se encarga de mostrar la interfaz visual, capturar la interacción (clics, formularios, navegación), y enviar/recibir datos desde el servidor. Trabaja directamente con la experiencia del usuario.
- Tecnologías habituales:
- Lenguajes: HTML, CSS, JavaScript.
- Frameworks/librerías modernas: React, Angular, Vue.
- Herramientas complementarias:
- Mejora de estilos: Sass (preprocesador), Bootstrap, Tailwind.
- Mejora del código JavaScript: TypeScript (superset con tipado estático).
- Tecnologías habituales:
- Back-end (servidor): es el componente que se ejecuta en un servidor remoto y gestiona la lógica de negocio, el acceso a datos, la autenticación de usuarios y la respuesta a las peticiones del cliente. Es el “motor” de la aplicación.
- Tecnologías habituales:
- Lenguajes: PHP, Node.js, Python (Django/Flask), Java (Spring), etc.
- Bases de datos: MySQL, PostgreSQL, MongoDB, Redis.
- Servidores: Apache, Nginx, Express.
- Herramientas útiles: ORMs como Prisma o Sequelize.
- Tecnologías habituales:
- Comunicación entre cliente y servidor: la interacción se realiza mediante peticiones HTTP/HTTPS, utilizando normalmente APIs (como REST o GraphQL). La información suele enviarse en formato JSON, aunque pueden usarse otros formatos como XML o HTML, dependiendo del contexto.
2.3. Funcionamiento de una aplicación web
Las aplicaciones web siguen una arquitectura cliente-servidor, en la que las tareas se reparten entre:
- El cliente (navegador), que solicita recursos o servicios.
- El servidor, que procesa esas solicitudes, accede a los datos si es necesario, y devuelve la respuesta correspondiente.
Secuencia básica de funcionamiento
- El usuario accede a la aplicación desde su navegador (cliente)
- El cliente envía una petición al servidor (por ejemplo, para iniciar sesión o consultar información)
- El servidor procesa la solicitud, accede a la base de datos si es necesario y genera una respuesta.
- El servidor envía la respuesta (datos en formato JSON, HTML, etc.)
- El cliente interpreta la respuesta y muestra la información al usuario y, según el caso, realiza nuevas peticiones o finaliza la sesión.
2.4 Arquitectura en capas
En muchas aplicaciones web modernas, el servidor no es un único sistema. En su lugar, se organiza en una arquitectura en capas (también llamada multi-tier), donde diferentes servicios o máquinas se especializan en funciones concretas. Esto mejora el rendimiento, la escalabilidad y la seguridad del sistema.
Por ejemplo:
- Una máquina puede encargarse del servidor web, que atiende las peticiones del cliente.
- Otra, del servidor de bases de datos, que almacena y gestiona la información.
- Otros servicios adicionales pueden gestionar el correo electrónico, la autenticación o almacenamiento en la nube.
Ejemplo práctico
Supongamos que un usuario accede a una aplicación web para consultar noticias. Este proceso puede ser representado con un diagrama de secuencia como el siguiente:
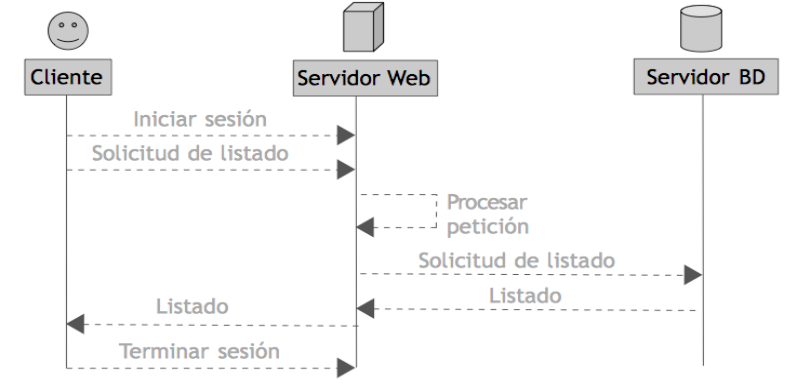
- El cliente (navegador) envía una solicitud de inicio de sesión al servidor web.
- Tras iniciar sesión correctamente, el cliente solicita un listado de noticias.
- El servidor web procesa la petición y, si necesita datos, consulta al servidor de bases de datos.
- El servidor de bases de datos responde con los datos solicitados al servidor web.
- El servidor web genera una respuesta (por ejemplo, un JSON o un HTML) y la envía al cliente.
- El cliente muestra los datos y permite nuevas interacciones o cerrar sesión.
2.4.1 Tipos de arquitectura
En función de cómo se organizan los elementos del sistema, podemos distinguir dos modelos principales:
-
Arquitectura de dos niveles (2-tier), tanto el servidor web como el servidor de bases de datos se ejecutan en la misma máquina. Es una solución sencilla y económica, adecuada para proyectos pequeños, entornos de desarrollo o pruebas. Sin embargo, presenta limitaciones importantes en términos de seguridad, escalabilidad y rendimiento, especialmente cuando el número de usuarios o el volumen de datos crece.
-
Arquitectura de tres niveles (3-tier), el servidor web y el servidor de bases de datos están separados físicamente, lo que permite distribuir mejor la carga, mejorar el rendimiento, y aumentar la seguridad. Es el modelo más común en entornos empresariales y sistemas en producción.
Más allá de estos modelos clásicos, hoy en día también se emplean otras arquitecturas modernas, como:
- La arquitectura de microservicios, donde cada funcionalidad (autenticación, pagos, búsqueda, etc.) se implementa como un servicio independiente, lo que permite desplegar, escalar y mantener cada uno por separado.
- La arquitectura desacoplada (frontend-backend), en la que el frontend (interfaz) y el backend (la lógica y datos) se desarrollan y despliegan por separado, comunicándose a través de una API (normalmente REST o GraphQL). Esto permite más flexibilidad y reutilización entre plataformas (web, móvil, etc.).
- Las arquitecturas serverless, proporcionadas por proveedores en la nube (AWS, Azure…) que administran la estructura automáticamente, y el desarrollador sólo implementa pequeñas funciones
3. Localización y acceso a aplicaciones web
Para que una aplicación web esté disponible en Internet y accesible desde cualquier navegador, es necesario tener en cuenta tres elementos clave:
- Dónde se aloja la aplicación (hosting o servidor).
- Cómo hacer accesible la aplicación con un nombre de dominio.
- Cómo se accede a los recursos dentro de la aplicación (URLs).
En este apartado se abordan los conceptos básicos necesarios para comprender cómo se publica una aplicación web y cómo se accede a ella desde cualquier parte del mundo. Algunos aspectos más técnicos, como los protocolos de comunicación y el sistema DNS, se estudiarán en detalle en apartados posteriores.
3.1 Alojamiento web (hosting)
El hosting es el servicio que permite almacenar y servir los archivos de una aplicación web (HTML, CSS, JS, imágenes, bases de datos, etc.) desde un servidor conectado permanentemente a Internet.
Existen distintas opciones de alojamiento según el tipo de proyecto, el nivel técnico del equipo y los recursos disponibles:
-
Servidor propio: implica desplegar la aplicación en una máquina física gestionada directamente por la empresa o el equipo de desarrollo. Ofrece control total, pero requiere conocimientos avanzados, mantenimiento continuo y una inversión inicial considerable.
- Hosting tradicional: empresas como Ionos, Hostinger o OVH ofrecen alojamiento web profesional con distintas modalidades, adaptadas al tipo de proyecto y al nivel técnico del usuario. Las más comunes son:
- Alojamiento compartido: varios sitios web comparten un mismo servidor físico y sus recursos. Es la opción más económica y sencilla de usar, ideal para proyectos pequeños, páginas personales o sitios con poco tráfico. No requiere conocimientos técnicos y suele incluir paneles de control fáciles de usar. Sin embargo, al compartir recursos con otros usuarios, el rendimiento puede verse afectado por el uso de terceros. En cuanto a la seguridad, depende en gran medida de la correcta configuración del proveedor, ya que una mala gestión puede permitir que los fallos de una web afecten a las demás.
- Servidor privado virtual (VPS, Virtual Private Server): se trata de una partición virtual dentro de un servidor físico, que funciona como un servidor independiente con sus propios recursos asignados. Ofrece mejor rendimiento, más control y opciones de configuración que el alojamiento compartido. Es una buena opción para aplicaciones de tamaño medio o que requieren ajustes técnicos específicos. A nivel de seguridad, proporciona un entorno más aislado y configurable, lo que permite aplicar políticas de protección más avanzadas, aunque también exige conocimientos para administrarlo correctamente.
- Servidor dedicado: consiste en alquilar un servidor físico completo, exclusivo para una única aplicación o cliente. Es la opción más potente y flexible, recomendada para proyectos que manejan grandes volúmenes de tráfico, datos sensibles o servicios críticos. Permite control total sobre el sistema y la seguridad, pero también requiere experiencia técnica para gestionarlo y mantenerlo adecuadamente. Aunque el proveedor se encarga de la infraestructura, la protección del entorno depende de cómo se configure y administre.
- Plataformas modernas de despliegue: servicios en la nube como AWS, Azure o plataformas especializadas como Vercel y Netlify, permiten desplegar aplicaciones de forma automatizada, con integración continua y escalado dinámico. Están especialmente orientadas a arquitecturas modernas como APIs, microservicios y frontends desacoplados.
3.2 Nombres de dominio
Aunque las aplicaciones web están alojadas en servidores identificados por su dirección IP (por ejemplo, 172.217.168.78), estos números no son prácticos para el uso diario.
Para facilitar el acceso, se utilizan nombres de dominio, que son direcciones web legibles y fáciles de recordar, como www.iessanvicente.com. Internamente, el nombre de dominio está asociado a la IP real del servidor donde se aloja la aplicación. Gracias a esta asociación, el navegador puede dirigir correctamente las solicitudes sin que el usuario conozca la dirección IP.
Por ejemplo, al acceder a www.google.es, el sistema traduce ese nombre en la dirección IP correspondiente a uno de los servidores de Google. Esta conversión la realiza un sistema llamado DNS (Domain Name System), que se explicará en profundidad.
3.2.1 Registro de dominio
Para disponer de un dominio propio, es necesario realizar un registro de dominio, un proceso gestionado por empresas autorizadas por la ICANN (Internet Corporation for Assigned Names and Numbers).
Para registrar un dominio, es necesario:
- Elegir un nombre de dominio que esté disponible.
- Seleccionar una extensión adecuada (.com, .es, .org, etc.).
- Registrar el dominio a través de un agente registrador acreditado.
- Configurar los registros DNS necesarios para vincular el dominio con el servidor que aloja la aplicación.
Una vez registrado y vinculado al servidor mediante el sistema DNS, el dominio estará activo y accesible desde Internet.
3.3 URLs
Una URL (Uniform Resource Locator) es la dirección completa que se usa para localizar un recurso específico dentro de una aplicación web. Es la forma en la que los navegadores realizan peticiones a los servidores.
Por ejemplo, cuando escribimos en un navegador una dirección como http://www.miweb.com/paginas/pagina.html, estamos introduciendo una URL para localizar un recurso (en este caso, una página HTML).
La estructura general de una URL es la siguiente:
protocolo://subdominio.dominio.com/carpeta/pagina?param=valor
- El protocolo, define las reglas para la comunicación entre cliente y servidor. En una URL, aparece al inicio, antes de los dos puntos y las dos barras ( // ). En el ejemplo anterior, el protocolo es http (HiperText Transfer Protocol). Veremos más adelante otros protocolos.
- El subdominio, es opcional y permite organizar servicios dentro de un mismo dominio principal. Es habitual que las empresas de hosting permitan registrar subdominios, aunque algunas lo ofrezcan con ciertas restricciones, ya sea por el número de subdominios permitidos o por el servicio que prestan. Por ejemplo, si tenemos el dominio www.miweb.com del ejemplo anterior como URL principal, podríamos tener además, tienda.miweb.com como subdominio para una tienda asociada a la web.
- El nombre de dominio, identifica el servidor al que se desea acceder. Va justo detrás del protocolo, hasta la siguiente barra. Normalmente termina en .com, .es, .net, etc. En nuestro ejemplo sería www.miweb.com
- La ruta hacia el recurso, indica la ubicación concreta del archivo dentro del servidor (/paginas/pagina.html, en el ejemplo).
- Unos parámetros opcionales, que proporcionan información adicional a la solicitud. Útil para generar contenidos dinámicos (?param=valor).
Este formato permite acceder de forma precisa y estructurada a cualquier recurso dentro de una aplicación web.
Ejercicio 1:
Hemos visto que la ICANN autoriza a diversas empresas para gestionar el registro de nombres de dominio en Internet. Estas empresas, conocidas como agentes registradores de dominio, ofrecen distintos planes de pago para este servicio. Busca en Internet una lista de agentes registradores de dominio oficiales para España y consulta los precios que tienen algunos de ellos.
4. Protocolos más utilizados
Para que los clientes y servidores puedan comunicarse, deben seguir un protocolo de comunicación. Un protocolo define una serie de reglas que especifican qué tipo de mensajes se van a intercambiar, en qué orden y cómo debe interpretarlos cada parte. Esto garantiza que ambos extremos de la comunicación se entiendan, incluso si son tecnologías distintas.
4.1 Protocolo base: TCP/IP
Todas las comunicaciones en Internet se apoyan en la familia de protocolos TCP/IP, que se compone de dos elementos principales:
- Protocolo TCP (Transmission Control Protocol): se encarga de dividir la información en paquetes, asegurar su entrega completa y en el orden correcto.
- Protocolo IP (Internet Protocol): identifica los dispositivos mediante direcciones IP y dirige los paquetes entre origen y destino.
Sobre esta base se construyen protocolos más específicos, como los que usan las aplicaciones web, el correo electrónico o la transferencia de archivos.
4.2 Protocolos web principales: HTTP y HTTPS
En el caso de las aplicaciones web, los protocolos más utilizados son:
- HTTP (HyperText Transfer Protocol): es el protocolo estándar desde los años 90 para la transferencia de páginas web. Funciona siguiendo un esquema de petición-respuesta, en el que el cliente solicita un recurso (como un archivo HTML) y el servidor lo envía como respuesta. Este protocolo no es seguro, ya que los datos viajan sin cifrar. Su evolución ha originado posteriores versiones como HTTP/2 o HTTP/3, que han mejorado significativamente los tiempos de respuesta al permitir peticiones simultáneas.
- HTTPS (HTTP Secure): es la versión segura de HTTP. Añade una capa de cifrado mediante TLS (antes SSL), de forma que los datos transmitidos no pueden ser interceptados ni manipulados por terceros. Es obligatorio en aplicaciones que manejan información sensible, como contraseñas, pagos, datos personales o bancarios. Los navegadores modernos priorizan automáticamente el uso de HTTPS cuando detectan formularios o zonas de autenticación, y muestran un candado en la barra de direcciones cuando la conexión es segura. No obstante, es necesario que el servidor web esté correctamente configurado para soportar HTTPS, incluyendo la instalación de un certificado digital válido.
4.3 Otros protocolos de Internet
Aunque no se usan directamente en aplicaciones web, existen otros protocolos de comunicación esenciales para servicios en Internet:
- SMTP (Simple Mail Transfer Protocol): se utiliza para enviar correos electrónicos.
- POP3 (Post Office Protocol v3) / IMAP (Internet Message Access Protocol): se utilizan para recibir correos electrónicos, dependiendo de si se descargan o se consultan directamente desde el servidor.
- FTP (File Transfer Protocol): se emplea para transferir archivos entre el cliente y el servidor. Es útil durante el desarrollo web para subir archivos al hosting, aunque cada vez se usa menos en favor de métodos más seguros como SFTP o despliegues automáticos desde repositorios.
4.4. Funcionamiento de HTTP/HTTPS
El protocolo HTTP, y su versión segura HTTPS, son la base de la comunicación en las aplicaciones web. Ambos funcionan bajo un modelo cliente-servidor, donde el navegador (cliente) realiza una petición y el servidor responde con el contenido solicitado o un mensaje de error. Esta comunicación se realiza siguiendo un formato estandarizado, que permite que ambos extremos puedan interpretarla correctamente.
Peticiones HTTP (requests)
Una petición HTTP es el mensaje que el cliente envía al servidor para solicitar un recurso. Suele estar compuesta por:
- La URL del recurso solicitado.
- Las cabeceras de petición, que incluyen información sobre el navegador, el idioma del usuario, el tipo de contenido aceptado, etc.
- El cuerpo (opcional), que puede contener datos como los valores de un formulario o archivos que se quieren subir.
Internamente, esta información se encapsula en paquetes que se fragmentan y envían siguiendo las reglas del protocolo TCP.
Respuestas HTTP (response)
El servidor analiza la petición y responde con un mensaje estructurado, que incluye:
- Un código de estado, que indica el resultado de la petición. Estos códigos se agrupan en varias categorías:
- Los códigos 2xx indican una respuesta satisfactoria (200 OK).
- Los códigos 3xx indican que ha habido algún tipo de redirección (301 Moved Permanently, 302 Found).
- Los códigos 4xx indican un error por parte del cliente. (404 Not Found, 403 Forbidden).
- Los códigos 5xx indican un error por parte del servidor (500 Internal Server Error, 503 Service Unavailable).
- Unas cabeceras de respuesta, que detallan aspectos como el tipo de contenido devuelto (tipo MIME), el tamaño del recurso o la fecha de última modificación.
- El contenido propiamente dicho, que puede ser una página HTML, un archivo, una imagen o incluso un mensaje de error en formato web.
4.5 Análisis de tráfico HTTP con Google Chrome
Para observar este intercambio en tiempo real, se puede usar la herramienta de desarrolladores de Google Chrome, en la pestaña Network, para analizar cualquier comunicación entre el navegador y un servidor web. Esto permite identificar códigos de estado, cabeceras y contenido transferido.
Accede a una web conocida (por ejemplo, ceice.gva.es), y comprueba la información enviada y recibida:
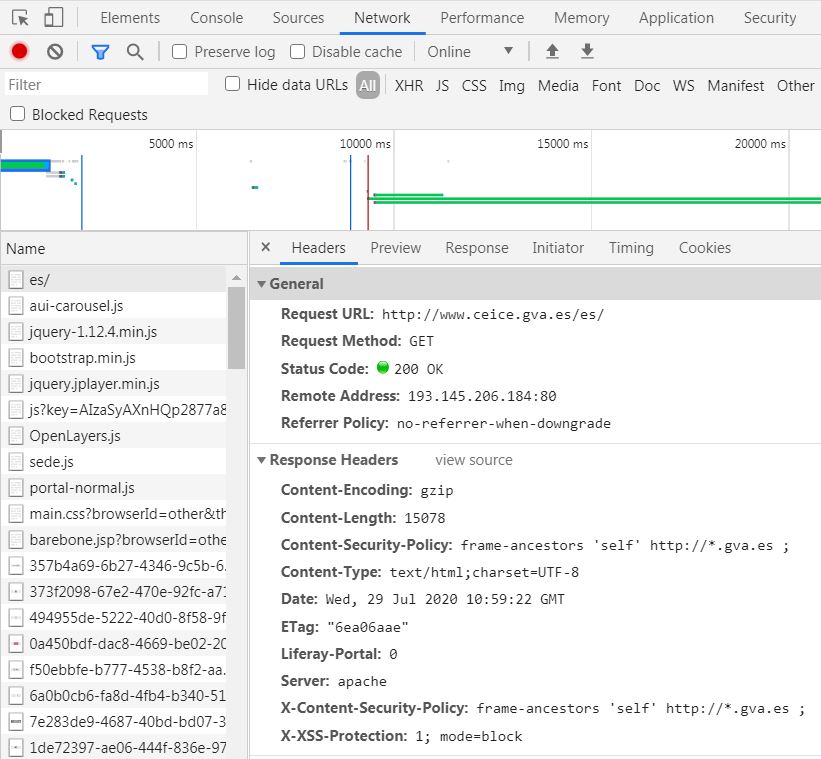
Ejercicio 2:
Utiliza Google Chrome (opción de Herramientas para desarrolladores, pestaña Network) para ver el esquema de petición y respuesta HTTP hacia alguna web conocida. Identifica el código de estado, las cabeceras de respuesta (trata de identificar algunas de ellas) y el contenido.
5. Sistema de nombres de dominio (DNS)
Cuando dos equipos se comunican a través de Internet, el dispositivo de origen necesita conocer dos elementos fundamentales del destino: su dirección IP, que identifica de forma única a un equipo dentro de la red, y el puerto, que indica el servicio específico al que se desea acceder dentro de ese equipo, como puede ser una página web o un servidor de correo.
Por ejemplo, al acceder a una página como www.google.es, el navegador necesita saber cuál es la dirección IP del servidor donde está alojado el sitio, así como el puerto del servicio web correspondiente, que normalmente es el puerto 80 para conexiones HTTP o el 443 para HTTPS.
Ambos datos son esenciales para establecer la conexión correctamente. Si no se conoce la dirección IP, los datos no pueden llegar al destino; si no se conoce el puerto, el servidor no sabría qué aplicación debe responder a la petición.
Aunque es técnicamente posible escribir directamente una dirección IP en el navegador para acceder a un sitio web, esto no es práctico ni intuitivo. Las direcciones IP son difíciles de memorizar y, además, pueden cambiar con el tiempo. Por el contrario, los nombres de dominio como www.google.es son más fáciles de recordar y comprender. Sin embargo, dado que los equipos de red funcionan internamente con direcciones IP, es necesario un sistema que realice la traducción entre nombres y direcciones.
Ese sistema es el DNS, o Sistema de Nombres de Dominio (Domain Name System), que se encarga de traducir nombres de dominio a direcciones IP y viceversa. Este proceso se denomina resolución DNS y resulta fundamental para el funcionamiento de Internet.
El DNS utiliza una base de datos que presenta una estructura jerárquica y distribuida.
- Es jerárquica porque organiza los nombres de dominio en varios niveles sucesivos, desde la raíz hasta los subdominios (por ejemplo: .es → .gob.es → educacion.gob.es).
- Es distribuida porque la información no está almacenada en un único servidor central, sino repartida entre miles de servidores DNS en todo el mundo, lo que proporciona redundancia, escalabilidad y disponibilidad del sistema.
El DNS admite tanto direcciones IPv4 como IPv6, y almacena la información necesaria en registros especiales llamados registros de recursos (Resource Records o RR). Estos registros pueden contener datos como direcciones IP, alias de dominios, información de servidores de correo, entre otros. Estos registros se agrupan en zonas, que son partes del espacio de nombres gestionadas por un servidor autoritativo responsable de mantener y proporcionar esa información de forma actualizada.
A continuación se profundizará en estos elementos y en el funcionamiento detallado del sistema DNS.
5.1. Elementos integrantes del DNS
El DNS se estructura en tres componentes principales: el espacio de nombres de dominio, los servidores de nombres y los resolvers.
5.1.1 Espacio de nombres de dominio
El espacio de nombres de dominio es una estructura jerárquica en forma de árbol invertido donde cada nodo contiene registros de recursos (RR) que proporcionan información sobre los componentes hardware y software que respaldan dicho dominio, como por ejemplo, los hosts, los servidores de nombres, los servidores web, los servidores de correo, etc.
Del nodo raíz, situado en el nivel más alto, parten las ramas que conforman las zonas. Éstas, a su vez, pueden contener uno o más nodos o dominios que a su vez pueden dividirse en subdominios según se baja en la jerarquía.
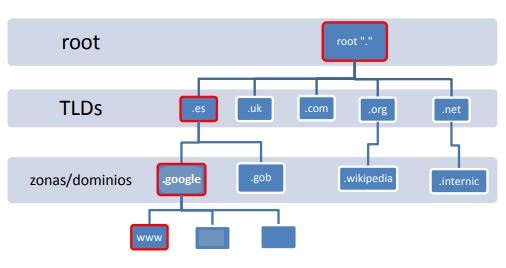
- Cada nodo del árbol se llama dominio y recibe una etiqueta o nombre. El nombre de dominio de un nodo se crea mediante la concatenación de todas las etiquetas, comenzando por dicho nodo y terminando en el nodo raíz. Por tanto, todo dominio completo termina en un punto final “.” que indica el final del espacio en la zona raíz.
- El nivel más alto de toda la jerarquía es el dominio raíz o root, y se representa por “.” (punto). En el sistema DNS un nodo puede tener un nombre de hasta 63 caracteres. La profundidad de nodos está limitada a 127 niveles.
- Justo un nivel por debajo se encuentran los Top Level Domains o TLDs, los cuales están alojados en lo que se conoce como servidores raíz. Existen varios servidores raíz ubicados en diferentes continentes. Se identifican con las letras del alfabeto, y varios de ellos se encuentran divididos físicamente y dispersos geográficamente con el fin de aumentar su rendimiento. Sus nombres son de la forma letra.root-servers.org. Son gestionados por organizaciones independientes. Por ejemplo, a.root-servers.org está gestionado por VeriSign, Inc. Puedes encontrar más información sobre estos servidores en https://root-servers.org/.
- Respecto a los TLDs, existen 3 tipos:
- Dominios de nivel superior geográficos (ccTLD): son aquellos TLDs que representan a países. Utilizan los códigos de país de dos letras definidos en estándar ISO-31663. Por ejemplo, .es para España, .fr para Francia, .pt para Portugal, etc.
- Dominios de nivel superior genéricos (gTLD): aquellos TLD que están abiertos a cualquier persona u organización. Están formados por tres o más caracteres. Por ejemplo, .biz para negocios, .com para propósitos comerciales, .info para información general, etc.
- Dominios de nivel superior de infraestructura (uTLD): esta categoría tiene un único TLD, .arpa, que se utiliza exclusivamente para la gestión de la infraestructura.
- Por debajo de los TLDs aparecen los dominios de segundo nivel, como gob.es, y estos a su vez pueden contener subdominios (educacion.gob.es, www.educacion.gob.es, etc.).
- La jerarquía continúa hasta llegar a un nodo final que representa un recurso. Por ejemplo “www.miweb.com” realmente es “www.miweb.com.”, donde el punto final más a la derecha representa la zona raíz, aunque éste último normalmente no se muestra. El nombre formado por toda la cadena se conoce como Fully Qualified Domain Name (FQDN).
Es importante no confundir los conceptos de zona y dominio. Mientras el dominio hace referencia al nombre lógico en la jerarquía del DNS, una zona es la porción de la base de datos que administra un servidor DNS determinado. Un dominio puede dividirse en varias zonas si se distribuye su gestión.
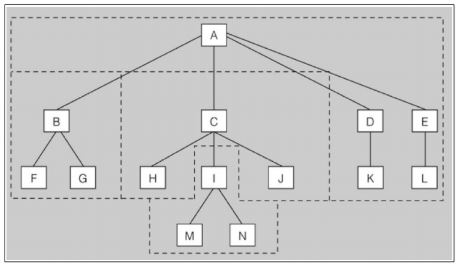
En la figura anterior hay tantos dominios como recuadros de letras agrupados en 4 zonas delimitadas por las líneas discontinuas. El nombre de dominio correspondiente a cada zona (se nombran según su nodo superior) es A, B.A, C.A, I.C.A. Cada una de estas cuatro zonas tendrá uno o más servidores DNS para gestionarla.
5.1.2 Servidores de nombres
Los servidores de nombres son servidores encargados de mantener y proporcionar información del espacio de nombres o dominios.
- Servidores autoritativos: almacenan información completa para una o varias zonas de las cuales son responsables. Proporcionan respuestas sobre los dominios para los que han sido configurados. El estándar que define el DNS establece que toda zona debe tener, al menos, dos servidores autoritativos:
- El primario, que guarda y administra las versiones definitivas de los registros de recursos de la zona
- El secundario, que guarda una copia que se actualiza cada vez que se produce un cambio, a través de un proceso conocido como transferencia de zona. Esto proporciona un mecanismo de redundancia, robustez, rendimiento y copia de seguridad, ya que si el servidor primario falla, la red sigue operativa gracias al servidor secundario.
- Servidores caché (o servidores recursivos): almacenan temporalmente respuestas obtenidas de otros servidores autoritativos. Gracias a su caché, reducen el número de consultas externas y mejoran el rendimiento de la red.
Con esta organización de servidores de nombres, y su intercomunicación, se consigue la distribución y redundancia del espacio de dominios.
5.1.3 Resolvers
El resolver es una rutina o componente del sistema operativo que actúa como intermediario entre las aplicaciones del usuario (como un navegador) y los servidores DNS. Cuando una aplicación necesita la dirección IP correspondiente a un nombre de dominio, el resolver se encarga de gestionar esa petición y devolver la información en el formato que el sistema pueda utilizar. Normalmente, se comunica con un servidor DNS configurado por defecto en el sistema o la red.
5.2 Proceso de resolución DNS
La principal función de un servidor DNS es responder a consultas de clientes o de otros servidores DNS. Existen dos tipos principales de consultas:
- Consulta Recursiva:
- El resolver (cliente) pide a su servidor DNS local una respuesta basada en sus archivos de zona o caché.
- Si el servidor no tiene la información solicitada, responde con el puntero al servidor raíz “.”.
- El resolver consulta al servidor raíz, luego los servidores de dominio de nivel superior (TLD), y así sucesivamente, hasta encontrar el servidor autoritativo que tiene la respuesta correcta.
- Normalmente, el resolver hace una consulta recursiva a un servidor DNS intermedio que actúa como caché recursivo, evitando que el cliente tenga que realizar múltiples consultas.
- Consulta Iterativa:
- El resolver solicita al servidor DNS una respuesta o un error si el recurso no existe.
- El servidor DNS actúa como intermediario, realizando consultas iterativas a otros servidores DNS hasta obtener la respuesta o un error.
En resumen, las consultas recursivas son generalmente generadas por los clientes DNS, mientras que las consultas iterativas son creadas por los servidores DNS al consultar a otros servidores.
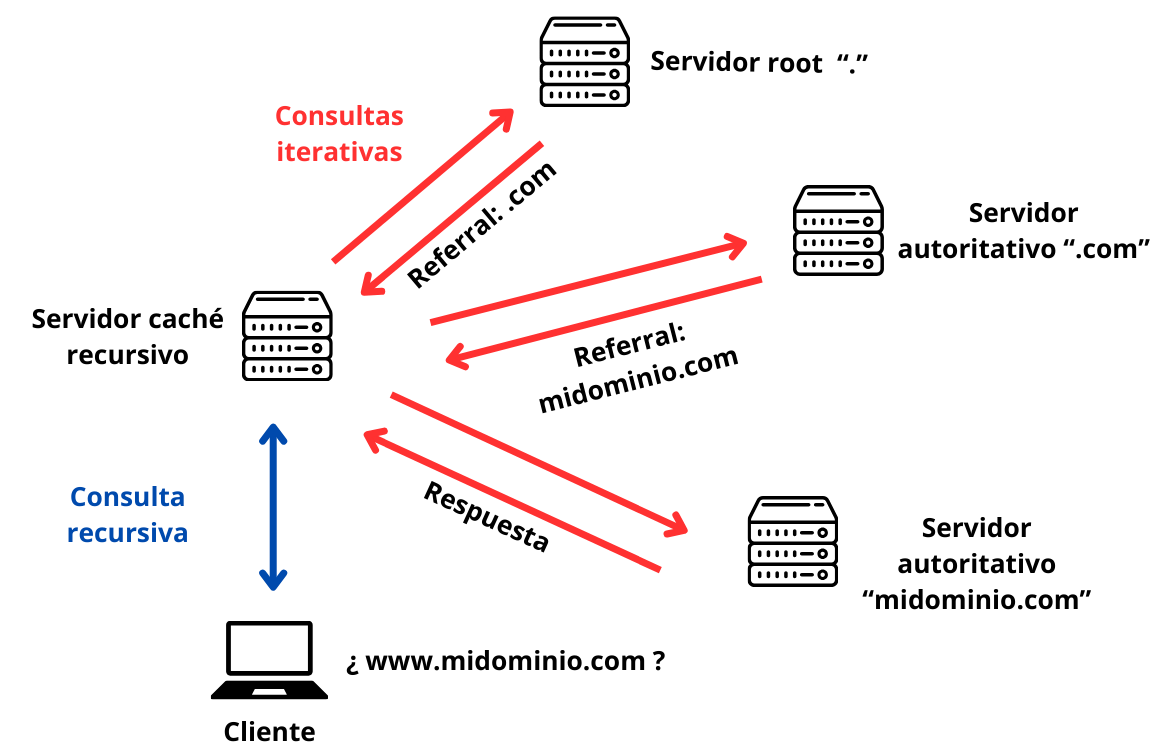
En términos generales, el proceso que se sigue en una resolución DNS es el siguiente.
- El cliente (resolver) envía la consulta a su servidor DNS.
- Si el servidor DNS tiene autoridad sobre el dominio consultado, devuelve la respuesta usando sus propios registros.
- Si el servidor no tiene autoridad y no es recursivo, informa al resolver dónde debe dirigir su consulta.
- Si el servidor no es autoritativo pero es recursivo, realiza consultas iterativas para encontrar el servidor autoritativo y devuelve la respuesta al cliente, almacenando la información en caché para futuras consultas.
Veamos un ejemplo concreto de resolución de nombres para comprender mejor el proceso. Supongamos que un cliente necesita localizar el equipo www.educacion.gob.es y envía una petición a su servidor DNS. Asumamos también que su servidor no tiene información sobre ese dominio. Así, observaremos cómo se lleva a cabo la resolución completa
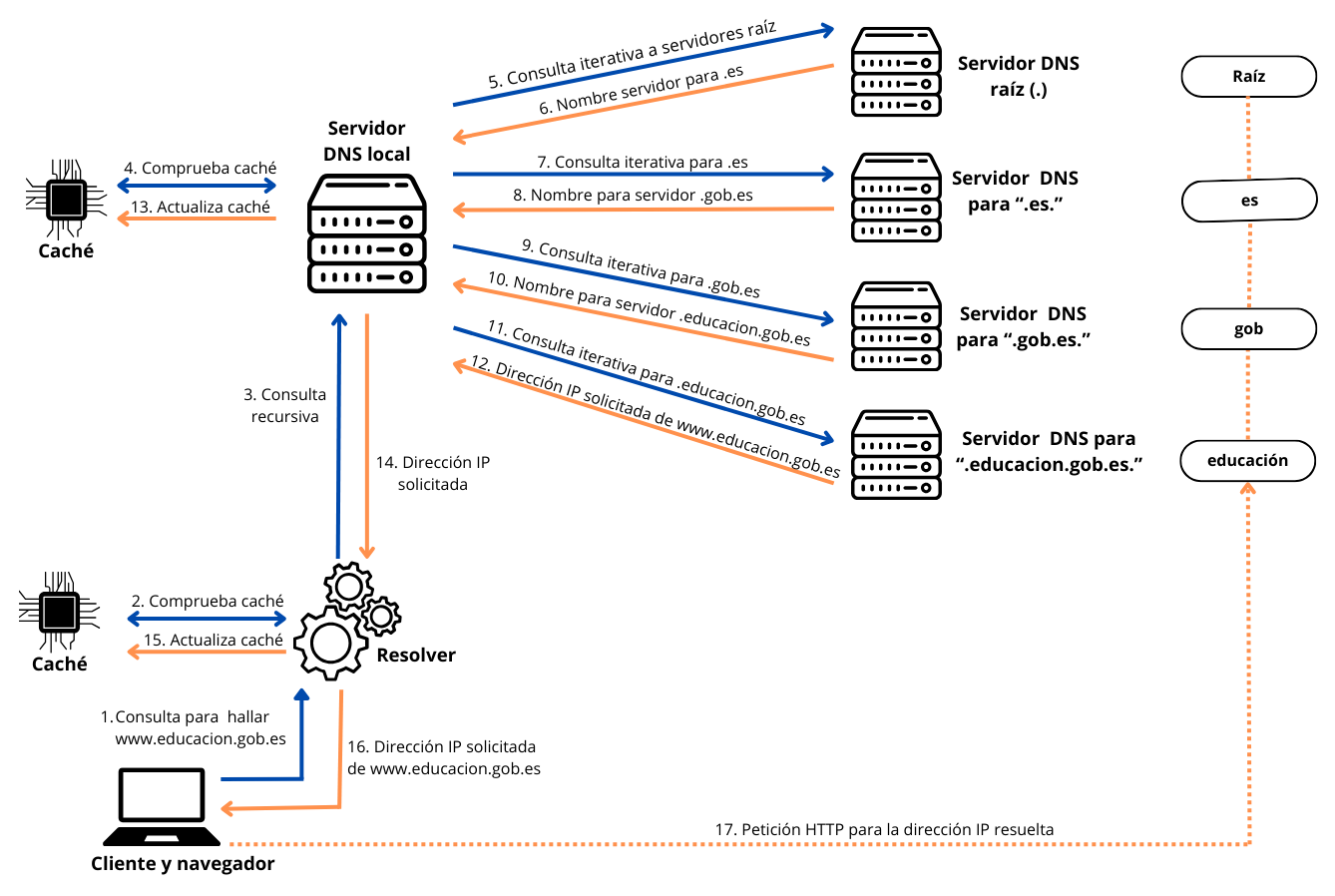
- Consulta inicial del cliente: un cliente, mediante un navegador web, solicita la resolución del nombre de dominio www.educacion.gob.es. El resolver consulta su caché para ver si tiene la dirección IP almacenada.
- Consulta al servidor DNS local: si la dirección no está en la caché, el resolver envía una consulta recursiva al servidor DNS primario o local configurado. Este servidor puede estar dentro de la empresa o en Internet. El servidor DNS local revisa su caché y, si encuentra la información, devuelve la dirección IP correspondiente.
- Consultas iterativas del servidor DNS: si el servidor DNS local no puede resolver la consulta, inicia una serie de consultas iterativas para encontrar el servidor autoritativo del dominio:
- Servidor raíz: consulta al servidor raíz. Si no es autoritativo, el servidor raíz devuelve el nombre del servidor responsable del dominio de primer nivel (.es).
- Servidor TLD: consulta al servidor del TLD (.es). Si no es autoritativo, devuelve el nombre del servidor responsable del dominio de segundo nivel (.gob.es).
- Servidor del dominio específico: consulta al servidor del dominio de segundo nivel (.gob.es). Si no es autoritativo, devuelve el nombre del servidor responsable del dominio específico (educacion.gob.es).
- Respuesta del servidor autoritativo: finalmente, se llega al servidor autoritativo para el dominio educacion.gob.es, que devuelve la dirección IP de www.educacion.gob.es al servidor DNS local.
- Actualización y respuesta:
- El servidor DNS local actualiza su caché con la nueva información.
- El servidor DNS local envía la respuesta al resolver del cliente.
- El resolver del cliente actualiza su caché.
- La respuesta llega al navegador web en el formato adecuado, completando la solicitud de resolución.
Este proceso consume bastante ancho de banda, por lo que es recomendable implementar una solución DNS interna con caché, especialmente en redes con alto tráfico hacia el exterior, como colegios, universidades, bibliotecas o grandes empresas. Esto permite obtener tiempos de respuesta más rápidos y una mejor experiencia de navegación web.
Herramienta DIG
DIG (Domain Information Gopher) es una herramienta de línea de comandos que realiza búsquedas en los registros DNS, a través de los nombres de servidores, y muestra el resultado. Se puede ejecutar tanto en Linux como en Windows aunque, en este último, es posible que sea necesaria su instalación previa.
Veamos un ejemplo de cómo funciona con el comando dig www.gva.es:
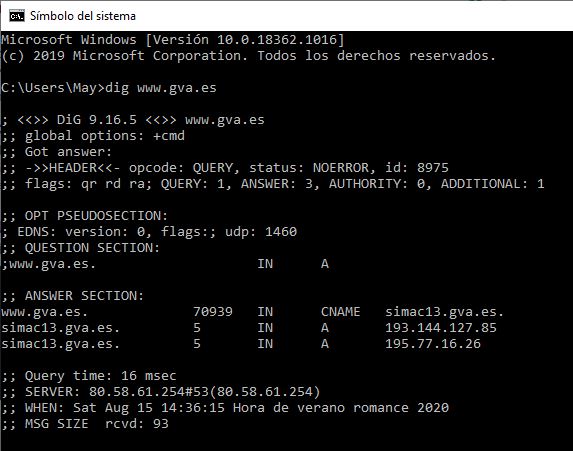
Explicación de la salida:
- Todas las líneas que inician con “;” son comentarios.
- La primera línea nos devuelve la versión del comando dig que estamos utilizando.
- Luego muestra una sección de consulta (question section) con nuestra consulta .
- A continuación, aparece la sección de respuesta (answer section) que contiene la respuesta del servidor DNS.
- Esta sección puede incluir diferentes tipos de registros de recurso (RR). Por defecto, la respuesta está asociada al registro de recurso de dirección A (RR A) y al registro de recurso de nombre canónico (RR CNAME), pero también se pueden consultar otros registros.
- El registro de dirección A (RR A) asocia nombres de dominio (FQDN) a direcciones IPv4. El registro A tiene la estructura siguiente: NombreDominio IN A IP.
- El registro de recurso nombre canónico (RR CNAME) enlaza el nombre de dominio con un alias, es decir, con otro nombre que también redirige al mismo contenido. El verdadero nombre, por lo tanto, es el que se conecta a través del registro A con la dirección IP. La ventaja de este sistema es que, si la dirección IP cambia, solo es necesario modificar el registro A. Puesto que todos los alias se guían según este registro A. Su estructura es la siguiente: NombreDominio IN CNAME Nombre canónico o IP
- Interprestación de la respuesta:
- Primero se muestra el registro CNAME que indica que www.gva.es es un alias de simac13.gva.es.
- Luego se muestran dos registros A para simac13.gva.es, proporcionando sus direcciones IP.
- Cada registro comienza con el nombre completo del dominio (incluyendo el punto final), seguido del tiempo en segundos que permanecerá el registro en la memoria caché.
- Estadísticas de la consulta:
- Finalmente, se muestran estadísticas como el tiempo de consulta, el servidor que respondió, la fecha y hora de la consulta y el tamaño del mensaje recibido.
Si se ejecuta DIG especificando la opción +trace, se muestra una traza de los servidores por los que pasa la consulta hasta llegar al servidor autoritativo, permitiendo ver la lista completa de nodos y pasos de resolución de un nombre. Esto es muy útil para entender cómo funciona el sistema de nombres de dominio.
6. Patrones de diseño software
Después de revisar los tipos de aplicaciones web, la arquitectura básica, los protocolos más comunes y el papel del DNS, llegamos a un componente esencial en el desarrollo de aplicaciones web robustas, mantenibles y eficientes: los patrones de diseño.
Un patrón de diseño es un conjunto de buenas prácticas, directrices estructurales y componentes organizados que proporcionan una solución reutilizable a problemas comunes en el desarrollo de software. Su objetivo principal es estandarizar la forma en que se diseñan y construyen las aplicaciones, facilitando la comprensión del sistema, la colaboración entre desarrolladores y la reutilización de componentes. Además, permiten generar estructuras modulares, predecibles y escalables, haciendo que el código sea más fácil de mantener y extender.
En el ámbito de las aplicaciones web, existen diversos patrones de diseño que nos orientan a la hora de organizar el código, separar responsabilidades y estructurar los distintos componentes. Uno de los más utilizados (y probablemente el más conocido) es el patrón MVC, que veremos a continuación. A partir de él han surgido otros enfoques, diseñados para adaptarse a necesidades concretas, entornos modernos o filosofías distintas de interacción. En este apartado revisaremos MVC y algunas de sus variantes más relevantes.
6.1. El patrón MVC
MVC son las siglas de Modelo-Vista-Controlador (Model-View-Controller), y representa uno de los patrones más utilizados tanto en aplicaciones web como en muchas aplicaciones de escritorio.
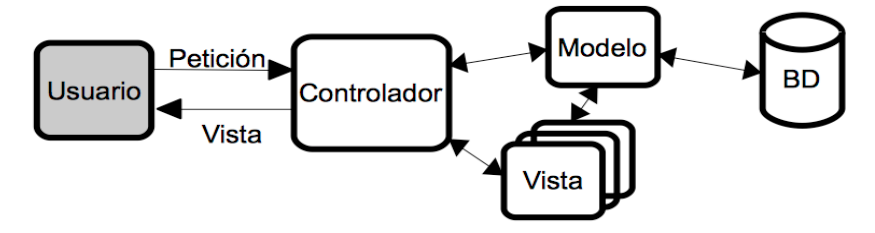
Este patrón se basa en la división del sistema en tres componentes fundamentales, cada uno con una responsabilidad claramente definida:
- El modelo representa los datos y la lógica de negocio de la aplicación. Gestiona el acceso, almacenamiento y validación de la información, normalmente mediante estructuras, clases u objetos que interactúan con bases de datos u otros sistemas de almacenamiento. El modelo no conoce ni depende de los demás componentes, lo que favorece la reutilización y el aislamiento de la lógica principal.
- La vista es la parte de la aplicación que se encarga de mostrar la información al usuario y de recoger su interacción. Está compuesta por páginas, formularios, interfaces gráficas u otros elementos visuales. Su única función es presentar los datos y recoger eventos (clics, formularios, etc.), sin contener lógica de negocio.
- El controlador actúa como intermediario entre el modelo y la vista. Recoge las peticiones del usuario (por ejemplo, mediante una URL o un formulario), procesa la lógica necesaria, accede al modelo para recuperar o modificar datos, y determina qué vista debe mostrarse como respuesta. Puede haber múltiples controladores, según las funcionalidades de la aplicación.
Una de las principales ventajas de este patrón es que separa claramente responsabilidades, lo que permite dividir el trabajo entre distintos perfiles profesionales. Por ejemplo, un diseñador puede centrarse en las vistas sin necesidad de conocer la lógica del modelo o del servidor, mientras que un desarrollador backend puede trabajar en el controlador y el modelo sin preocuparse del diseño visual.
En forma de esquema, podríamos representarlo así:
6.2. Otras alternativas a MVC
A partir de la popularidad y estructura de MVC han surgido otros patrones que lo adaptan o reinterpretan para entornos específicos. En la mayoría de estos patrones se mantiene el modelo de datos y la vista como componentes clave, y se modifica o reemplaza el papel del controlador. Esta familia de patrones se conoce genéricamente como MVW, (Modelo-Vista-Cualquier cosa, o Model-View-Whatever), lo que refleja la flexibilidad del tercer componente.
Estos patrones suelen buscar una mayor modularidad, eliminar la lógica centralizada de los controladores o facilitar la interactividad directa entre modelo y vista. A continuación, se describen los más representativos.
El patrón MVVM
El patrón MVVM (Modelo-Vista-VistaModelo, o Model-View-ViewModel) sustituye el controlador de MVC por un nuevo componente denominado ViewModel (VistaModelo), y se centra exclusivamente en los componentes del modelo y la vista.
En este enfoque, el usuario interactúa directamente con la vista, que está vinculada al modelo a través del ViewModel. Este componente intermedio contiene la lógica necesaria para transformar los datos del modelo en una forma adecuada para ser mostrada en la vista, y también recoge las acciones del usuario para modificar el modelo. La comunicación entre el modelo y la vista es bidireccional: los cambios en la vista actualizan el modelo, y los cambios en el modelo se reflejan automáticamente en la vista. Esto se conoce como data binding (enlace de datos).
MVVM es especialmente útil en aplicaciones donde hay una única vista principal que se actualiza dinámicamente, como es el caso de muchas Single Page Applications (SPA), donde no se recargan páginas completas sino que se actualizan secciones específicas. Dado que en estas aplicaciones no es necesario decidir qué vista cargar (sólo hay una), el controlador pierde relevancia y puede ser sustituido por este vínculo directo modelo-vista. Frameworks modernos como Angular o Vue.js incorporan conceptos de MVVM, con distintos niveles de formalidad.
El patrón MOVE
El patrón MOVE (Modelo-Operación-Vista-Evento, o Model-Operation-View-Event) propone una división distinta del rol del controlador, reemplazándolo por dos componentes: eventos y operaciones. Los eventos representan acciones o sucesos que ocurren en la aplicación, generalmente generados por la interacción del usuario (como hacer clic en un botón, enviar un formulario, etc.). Estos eventos desencadenan operaciones, que definen las tareas que la aplicación puede realizar (como validar datos, consultar el modelo o actualizar la interfaz).
En este patrón, cuando ocurre un evento, se ejecuta una operación asociada, que puede acceder al modelo para obtener o modificar datos, y generar una vista que se muestra al usuario como respuesta. De esta forma, la lógica que en MVC estaba concentrada en el controlador se reparte entre los eventos que la activan y las operaciones que la implementan. Esta separación puede facilitar la organización del código y el manejo de aplicaciones con muchas acciones simultáneas o asincrónicas.
El patrón MVP
El patrón MVP (Modelo-Vista-Presentador, o Model-View-Presenter) sustituye el controlador de MVC por un componente llamado presentador. A diferencia del controlador, que en MVC puede gestionar múltiples vistas, en MVP cada vista tiene asociado su propio presentador, lo que refuerza el encapsulamiento.
En este enfoque, la vista es pasiva y no interactúa directamente con el modelo. Todo el flujo pasa por el presentador: cuando el usuario realiza una acción, esta se envía al presentador, que accede al modelo, obtiene o actualiza datos, y luego actualiza la vista. Esto crea una relación clara entre cada par vista-presentador, lo que facilita la separación de responsabilidades y mejora la capacidad de realizar pruebas automatizadas.
El patrón MVP es muy común en el desarrollo de interfaces gráficas complejas, tanto en aplicaciones de escritorio como móviles, como en entornos .NET o aplicaciones Android.
7. Recursos necesarios
Para implantar una aplicación web y que los clientes puedan utilizarla, es necesario contar con una serie de recursos tanto de hardware como de software.
-
En el lado del cliente, simplemente habrá que contar con un equipo con el hardware necesario (dependiendo de la aplicación web que sea, podrá ser un móvil, una tablet, portátil, PC…), y, típicamente, un navegador web instalado (aunque también podría tratarse de una aplicación híbrida para móvil, o de escritorio, en cuyo caso haría falta la aplicación en sí).
-
En el lado del servidor, normalmente necesitaremos al menos un equipo con características de hardware adecuadas, especialmente en lo que respecta a procesador, memoria RAM y capacidad de almacenamiento. En ese servidor será necesario instalar:
- Un servidor web o servidor de aplicaciones, encargado de alojar la aplicación web y atender las peticiones de los clientes. Es habitual contar con dos entornos diferenciados: un servidor de producción, accesible desde Internet y que contiene la versión final de la aplicación, y un servidor de pruebas o desarrollo, ubicado localmente para realizar las tareas de programación, pruebas y mantenimiento antes de publicar los cambios.
- Un servidor de base de datos (si la aplicación lo requiere), o un sistema gestor de bases de datos (SGBD). Este componente es fundamental para la mayoría de aplicaciones web, ya que muchas de ellas trabajan con datos almacenados y requieren consultar, insertar o modificar información de forma persistente.
7.1. Lenguajes
En el desarrollo de aplicaciones web es importante identificar los lenguajes de programación utilizados, que se clasifican según el entorno en que se ejecutan:
-
Lenguajes del entorno cliente (o lenguajes cliente): se ejecutan en el navegador del usuario y permiten la interacción directa con la aplicación. En este contexto, se utilizan lenguajes como HTML y CSS para el diseño y estructura de las páginas (aunque no se consideran lenguajes de programación en sentido estricto), y JavaScript para manejar eventos, validar formularios, crear animaciones, etc. También existen herramientas y preprocesadores como SASS, que amplían las capacidades de CSS, así como frameworks y librerías JavaScript como Angular, React o Vue, que facilitan el desarrollo de interfaces dinámicas. Además, existen lenguajes como TypeScript, una evolución de JavaScript que añade tipado estático y mayor estructura, lo que facilita el desarrollo de aplicaciones grandes y escalables.
-
Lenguajes del entorno servidor (o lenguajes servidor): se ejecutan en el servidor web y permiten realizar operaciones como consultas a bases de datos, manejo de archivos o gestión de sesiones. Uno de los lenguajes más utilizados tradicionalmente en este ámbito ha sido PHP, que sigue siendo muy común para aplicaciones web dinámicas, especialmente en combinación con servidores Apache. Otro lenguaje ampliamente adoptado es JavaScript, que gracias al entorno de ejecución Node.js también puede utilizarse en el servidor, permitiendo escribir tanto el backend como el frontend de una aplicación en un único lenguaje. Sobre Node.js se apoya el uso de TypeScript, que se está consolidando como una herramienta clave en el desarrollo moderno del lado servidor, al aportar tipado estático, una mayor organización del código y mejor soporte para proyectos de gran tamaño. En aplicaciones que utilizan tecnología Microsoft, también se emplea ASP.NET, que se ejecuta sobre el servidor IIS y se integra con el ecosistema Windows.
7.2. Ejemplos de software
A continuación se describen los programas concretos que se utilizarán durante el curso, tanto en el lado cliente como en el servidor.
En el cliente, necesitaremos un navegador web para visualizar e interactuar con las aplicaciones. Existen varias opciones disponibles, como Mozilla Firefox, Google Chrome, Microsoft Edge (antes Internet Explorer), Safari o Opera, aunque probablemente las mejores alternativas por compatibilidad, rendimiento y herramientas para desarrolladores sean Google Chrome y Mozilla Firefox.
En el servidor, el software a utilizar dependerá del lenguaje de programación elegido y del sistema operativo, aunque en nuestro caso, utilizaremos entornos compatibles con Windows.
- Para el desarrollo con PHP, emplearemos el servidor web Apache, instalado mediante herramientas como XAMPP, que integran Apache, el lenguaje PHP y el sistema gestor de bases de datos MySQL/MariaDB en un único paquete de fácil configuración.
- Para desarrollo con JavaScript del lado servidor, se utilizará Node.js, acompañado de diversos módulos y herramientas que se irán introduciendo a lo largo del curso. En este entorno también se instalará el framework Express, que facilita la creación y organización de rutas, así como la gestión de las peticiones HTTP.
Respecto al servidor de bases de datos, existen múltiples alternativas. Por un lado, tenemos las bases de datos relacionales, como MySQL/MariaDB, PostgreSQL, Oracle o SQL Server, todas ellas disponibles en versiones gratuitas o comerciales según las necesidades del proyecto. Por otro lado, existen opciones no relacionales o NoSQL, como MongoDB, que permiten almacenar documentos en formato JSON y se adaptan especialmente bien a estructuras de datos flexibles y dinámicas.
En nuestro curso, utilizaremos MySQL/MariaDB (integrado con Apache y PHP mediante XAMPP) y MongoDB (en combinación con Node.js) como soluciones principales para almacenamiento de datos.
IDEs
Para el desarrollo de aplicaciones es necesario contar con un buen entorno de desarrollo o IDE con el que editar el código, depurar y probar las aplicaciones.
Existen multitud de opciones disponibles, la mayoría de ellas gratuitas. Desde entornos de propósito general válidos para muchos lenguajes (Atom, Sublime, Visual Studio Code…) a otros más específicos y orientados a algún lenguaje en concreto, como PhpStorm.
En nuestro caso, optaremos por Visual Studio Code, por su versatilidad y popularidad creciente. Permite instalar multitud de extensiones para trabajar con distintos tipos de lenguajes y frameworks, y nos permite también una fácil integración con PHP y Node.js.
7.3. Webs de interés
A continuación se enumeran algunas webs donde consultar o descargar los recursos indicados en este tema, para el desarrollo de aplicaciones en entorno servidor.
- XAMPP - https://www.apachefriends.org/es/index.html
- Apache - https://www.apache.org
- Node.js - https://nodejs.org
- MongoDB - https://www.mongodb.com
- Express - https://expressjs.com
- Laravel - https://laravel.com
- Symfony - https://symfony.com
Ejercicio 3:
Utiliza la herramienta Google Trends para buscar los términos de Laravel, Symfony y Node.js. Deduce a partir de las búsquedas cuál de ellos crees que es más popular actualmente. Después, acude a la web de InfoJobs y busca ofertas de trabajo con estos tres frameworks, para determinar cuál es el más demandado en la actualidad.